




Sagnik Mukherjee
@sagnikmukherjee.bsky.social
NLP PhD student @convai_uiuc | Agents, Reasoning, evaluation etc.
https://sagnikmukherjee.github.io
https://scholar.google.com/citations?user=v4lvWXoAAAAJ&hl=en
https://sagnikmukherjee.github.io
https://scholar.google.com/citations?user=v4lvWXoAAAAJ&hl=en
Pinned
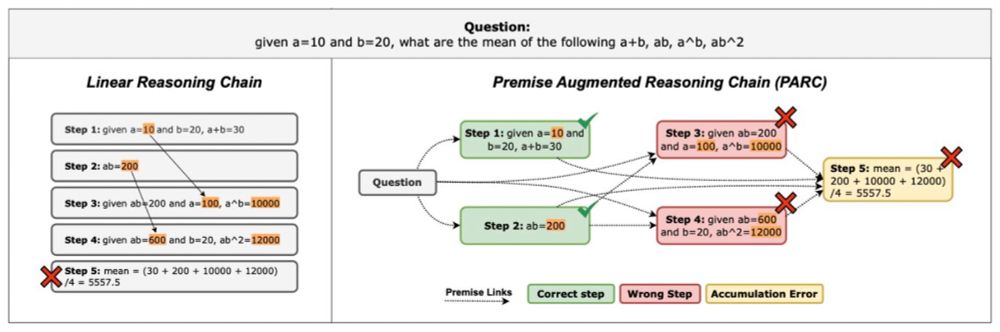
🚀Our ICML 2025 paper introduces "Premise-Augmented Reasoning Chains" - a structured approach to induce explicit dependencies in reasoning chains.
By revealing the dependencies within chains, we significantly improve how LLM reasoning can be verified.
🧵[1/n]
By revealing the dependencies within chains, we significantly improve how LLM reasoning can be verified.
🧵[1/n]
Reposted by Sagnik Mukherjee

Reinforcement Learning Finetunes Small Subnetworks in Large Language Models by @sagnikmukherjee.bsky.social, Lifan Yuan, @dilekh.bsky.social, Hao Peng
Read more here: arxiv.org/abs/2505.11711
x.com/saagnikkk/st...
Read more here: arxiv.org/abs/2505.11711
x.com/saagnikkk/st...

Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
Reinforcement learning (RL) yields substantial improvements in large language models (LLMs) downstream task performance and alignment with human values. Surprisingly, such large gains result from upda...
arxiv.org
September 20, 2025 at 3:17 PM
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models by @sagnikmukherjee.bsky.social, Lifan Yuan, @dilekh.bsky.social, Hao Peng
Read more here: arxiv.org/abs/2505.11711
x.com/saagnikkk/st...
Read more here: arxiv.org/abs/2505.11711
x.com/saagnikkk/st...
🚨 Paper Alert: “RL Finetunes Small Subnetworks in Large Language Models”
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive

May 21, 2025 at 3:50 AM
🚨 Paper Alert: “RL Finetunes Small Subnetworks in Large Language Models”
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive
🚀Our ICML 2025 paper introduces "Premise-Augmented Reasoning Chains" - a structured approach to induce explicit dependencies in reasoning chains.
By revealing the dependencies within chains, we significantly improve how LLM reasoning can be verified.
🧵[1/n]
By revealing the dependencies within chains, we significantly improve how LLM reasoning can be verified.
🧵[1/n]
May 7, 2025 at 6:52 PM
🚀Our ICML 2025 paper introduces "Premise-Augmented Reasoning Chains" - a structured approach to induce explicit dependencies in reasoning chains.
By revealing the dependencies within chains, we significantly improve how LLM reasoning can be verified.
🧵[1/n]
By revealing the dependencies within chains, we significantly improve how LLM reasoning can be verified.
🧵[1/n]
Reposted by Sagnik Mukherjee

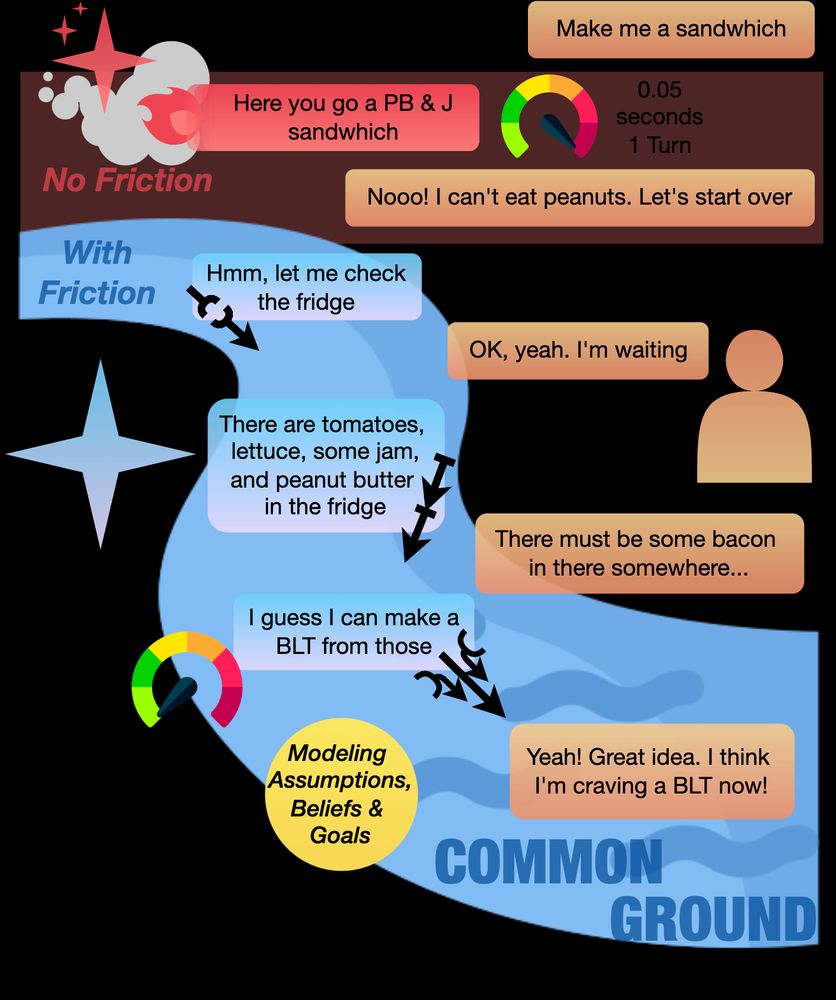
AI over-reliance is an important issue for conversational agents. Our work supported mainly by the DARPA FACT program proposes introducing positive friction to encourage users to think critically when making decisions. Great team-work, all!
@convai-uiuc.bsky.social @gokhantur.bsky.social
@convai-uiuc.bsky.social @gokhantur.bsky.social

‼️ Ever wish LLMs would just... slow down for a second?
In our latest work, "Better Slow than Sorry: Introducing Positive Friction for Reliable Dialogue Systems", we delve into how strategic delays can enhance dialogue systems.
Paper Website: merterm.github.io/positive-fri...
In our latest work, "Better Slow than Sorry: Introducing Positive Friction for Reliable Dialogue Systems", we delve into how strategic delays can enhance dialogue systems.
Paper Website: merterm.github.io/positive-fri...
February 9, 2025 at 12:54 AM
AI over-reliance is an important issue for conversational agents. Our work supported mainly by the DARPA FACT program proposes introducing positive friction to encourage users to think critically when making decisions. Great team-work, all!
@convai-uiuc.bsky.social @gokhantur.bsky.social
@convai-uiuc.bsky.social @gokhantur.bsky.social
Reposted by Sagnik Mukherjee

I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
November 23, 2024 at 7:54 PM
I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
📢📢LLMs are biased towards Western Culture. Well, okay, but what do you mean by "Culture"?
In our survey of on cultural bias in LLMs, we reviewed ~90 papers. Interestingly, none of these papers define "culture" explicitly. They use “proxies”. [1/7]
[Appeared in EMNLP mains]
In our survey of on cultural bias in LLMs, we reviewed ~90 papers. Interestingly, none of these papers define "culture" explicitly. They use “proxies”. [1/7]
[Appeared in EMNLP mains]

November 21, 2024 at 10:03 PM
📢📢LLMs are biased towards Western Culture. Well, okay, but what do you mean by "Culture"?
In our survey of on cultural bias in LLMs, we reviewed ~90 papers. Interestingly, none of these papers define "culture" explicitly. They use “proxies”. [1/7]
[Appeared in EMNLP mains]
In our survey of on cultural bias in LLMs, we reviewed ~90 papers. Interestingly, none of these papers define "culture" explicitly. They use “proxies”. [1/7]
[Appeared in EMNLP mains]
Reposted by Sagnik Mukherjee

Nice overview of the ReSpAct framework for conversational task completion agents @convai-uiuc.bsky.social
cobusgreyling.medium.com/building-con...
cobusgreyling.medium.com/building-con...

Building Conversational AI Agents By Integrating Reasoning, Speaking & Acting With LLMs
AI Agents meet Conversational UI for intuitive & natural conversations.
cobusgreyling.medium.com
November 19, 2024 at 8:29 PM
Nice overview of the ReSpAct framework for conversational task completion agents @convai-uiuc.bsky.social
cobusgreyling.medium.com/building-con...
cobusgreyling.medium.com/building-con...
Reposted by Sagnik Mukherjee
November 18, 2024 at 7:51 PM
Reposted by Sagnik Mukherjee
Welcome to the official page of ConvAI@UIUC! 🤖 Based in the cornfields of UIUC, and led by Dilek Hakkani-Tur and Gokhan Tur, we do cool research on chatbots, dialogue, embodied agents, and everything in between!
November 17, 2024 at 7:35 PM
Welcome to the official page of ConvAI@UIUC! 🤖 Based in the cornfields of UIUC, and led by Dilek Hakkani-Tur and Gokhan Tur, we do cool research on chatbots, dialogue, embodied agents, and everything in between!
Reposted by Sagnik Mukherjee
We had so much fun at #EMNLP2024 during the poster sessions and in Miami 🎉🎉 Evidence of fun (excursion to the south beach! 🏖️):



November 17, 2024 at 7:36 PM
We had so much fun at #EMNLP2024 during the poster sessions and in Miami 🎉🎉 Evidence of fun (excursion to the south beach! 🏖️):
Reposted by Sagnik Mukherjee

All the ACL chapters are here now: @aaclmeeting.bsky.social @emnlpmeeting.bsky.social @eaclmeeting.bsky.social @naaclmeeting.bsky.social #NLProc
November 19, 2024 at 3:48 AM
All the ACL chapters are here now: @aaclmeeting.bsky.social @emnlpmeeting.bsky.social @eaclmeeting.bsky.social @naaclmeeting.bsky.social #NLProc