



Emma Roscow
@emmaroscow.bsky.social
Machine learning @ EcoVadis | ex-neuroscience-postdoc who still dabbles
Pinned

Post-learning replay of hippocampal-striatal activity is biased by reward-prediction signals
Nature Communications - It is unclear which aspects of experience shape sleep’s contributions to learning. Here, by combining neural recordings in rats with reinforcement learning, the...
rdcu.be
New(ish) paper!
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
Reposted by Emma Roscow

More press on our recent Behavioral and Brain Sciences article:
#philsci #cogsky #CognitiveNeuroscience
@phaueis.bsky.social
aktuell.uni-bielefeld.de/2025/11/24/t...
#philsci #cogsky #CognitiveNeuroscience
@phaueis.bsky.social
aktuell.uni-bielefeld.de/2025/11/24/t...

Thinking Takes Energy
A new study shows how our brain metabolism sets the limits of thinking. Researchers explain why cognitive models remain incomplete without considering biological resources.
aktuell.uni-bielefeld.de
December 1, 2025 at 11:33 PM
More press on our recent Behavioral and Brain Sciences article:
#philsci #cogsky #CognitiveNeuroscience
@phaueis.bsky.social
aktuell.uni-bielefeld.de/2025/11/24/t...
#philsci #cogsky #CognitiveNeuroscience
@phaueis.bsky.social
aktuell.uni-bielefeld.de/2025/11/24/t...
Reposted by Emma Roscow

A neat perspective on what makes RL for LLMs tractable

I'd say that's because it's not sparse reward in a meaningful way, in the same way Go in self-play is not sparse in a meaningful way.
That is, in Go, your reward is 0 for most time steps and only +1/-1 at end. That sound's sparse, but not from an algorithmic perspective.
That is, in Go, your reward is 0 for most time steps and only +1/-1 at end. That sound's sparse, but not from an algorithmic perspective.
December 1, 2025 at 12:52 PM
A neat perspective on what makes RL for LLMs tractable
Reposted by Emma Roscow

1/3 How reward prediction errors shape memory: when people gamble and cues signal unexpectedly high reward probability, those incidental images are remembered better than ones on safe trials, linking RL computations to episodic encoding. #RewardSignals #neuroskyence www.nature.com/articles/s41...

Positive reward prediction errors during decision-making strengthen memory encoding - Nature Human Behaviour
Jang and colleagues show that positive reward prediction errors elicited during incidental encoding enhance the formation of episodic memories.
www.nature.com
November 30, 2025 at 11:12 AM
1/3 How reward prediction errors shape memory: when people gamble and cues signal unexpectedly high reward probability, those incidental images are remembered better than ones on safe trials, linking RL computations to episodic encoding. #RewardSignals #neuroskyence www.nature.com/articles/s41...
New(ish) paper!
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
Post-learning replay of hippocampal-striatal activity is biased by reward-prediction signals
Nature Communications - It is unclear which aspects of experience shape sleep’s contributions to learning. Here, by combining neural recordings in rats with reinforcement learning, the...
rdcu.be
November 29, 2025 at 6:32 PM
New(ish) paper!
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
It's often said that hippocampal replay, which helps to build up a model of the world, is biased by reward. But the canonical temporal-difference learning requires updates proportional to reward-prediction error (RPE), not reward magnitude
1/4
rdcu.be/eRxNz
Reposted by Emma Roscow

Terrific work led by @emmaroscow.bsky.social showing that hippocampal replay reflects events with large prediction errors, all the better to bootstrap learning as we slumber
Congratulations to Matt Jones & Nathan Lepora for seeing this through to the end!
www.nature.com/articles/s41...
Congratulations to Matt Jones & Nathan Lepora for seeing this through to the end!
www.nature.com/articles/s41...
Post-learning replay of hippocampal-striatal activity is biased by reward-prediction signals - Nature Communications
It is unclear which aspects of experience shape sleep’s contributions to learning. Here, by combining neural recordings in rats with reinforcement learning, the authors show that reward-prediction sig...
www.nature.com
November 27, 2025 at 10:24 AM
Terrific work led by @emmaroscow.bsky.social showing that hippocampal replay reflects events with large prediction errors, all the better to bootstrap learning as we slumber
Congratulations to Matt Jones & Nathan Lepora for seeing this through to the end!
www.nature.com/articles/s41...
Congratulations to Matt Jones & Nathan Lepora for seeing this through to the end!
www.nature.com/articles/s41...
Reposted by Emma Roscow

How does a neuron get its activity? 👀
Check out our latest preprint, where we tracked the activity of the same neurons throughout early postnatal development: www.biorxiv.org/content/10.1...
see 🧵 (1/?)
Check out our latest preprint, where we tracked the activity of the same neurons throughout early postnatal development: www.biorxiv.org/content/10.1...
see 🧵 (1/?)
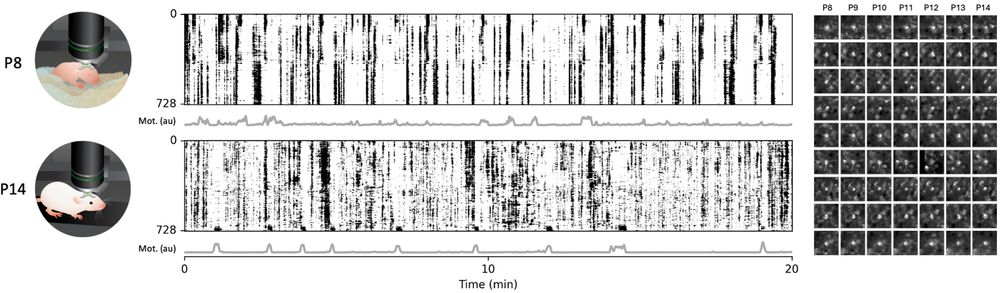
March 3, 2025 at 11:23 AM
How does a neuron get its activity? 👀
Check out our latest preprint, where we tracked the activity of the same neurons throughout early postnatal development: www.biorxiv.org/content/10.1...
see 🧵 (1/?)
Check out our latest preprint, where we tracked the activity of the same neurons throughout early postnatal development: www.biorxiv.org/content/10.1...
see 🧵 (1/?)
Reposted by Emma Roscow

REM sleep and nightmares as transdiagnostic features of psychiatric disorders:
www.sciencedirect.com/science/arti...
www.sciencedirect.com/science/arti...

Systematic review: REM sleep, dysphoric dreams and nightmares as transdiagnostic features of psychiatric disorders with emotion dysregulation - Clinical implications
Fragmented rapid eye movement (REM) sleep disrupts the overnight resolution of emotional distress, a process crucial for emotion regulation. Emotion d…
www.sciencedirect.com
February 16, 2025 at 8:18 AM
REM sleep and nightmares as transdiagnostic features of psychiatric disorders:
www.sciencedirect.com/science/arti...
www.sciencedirect.com/science/arti...