



Hugo Ninou
@hugoninou.bsky.social
I am a PhD student working at the intersection of neuroscience and machine learning.
My work focuses on learning dynamics in biologically plausible neural networks. #NeuroAI
My work focuses on learning dynamics in biologically plausible neural networks. #NeuroAI
Pinned
Hugo Ninou
@hugoninou.bsky.social
· Oct 10

Curl Descent: Non-Gradient Learning Dynamics with Sign-Diverse Plasticity
Gradient-based algorithms are a cornerstone of artificial neural network training, yet it remains unclear whether biological neural networks use similar gradient-based strategies during learning. Expe...
www.arxiv.org
🚨New spotlight paper at Neurips 2025🚨
We show that in sign-diverse networks, inherent non-gradient “curl” terms arise, and can, depending on network architecture, destabilize gradient-descent solutions or paradoxically accelerate learning beyond pure gradient flow.
🧵⬇️
www.arxiv.org/abs/2510.02765
We show that in sign-diverse networks, inherent non-gradient “curl” terms arise, and can, depending on network architecture, destabilize gradient-descent solutions or paradoxically accelerate learning beyond pure gradient flow.
🧵⬇️
www.arxiv.org/abs/2510.02765
🚨New spotlight paper at Neurips 2025🚨
We show that in sign-diverse networks, inherent non-gradient “curl” terms arise, and can, depending on network architecture, destabilize gradient-descent solutions or paradoxically accelerate learning beyond pure gradient flow.
🧵⬇️
www.arxiv.org/abs/2510.02765
We show that in sign-diverse networks, inherent non-gradient “curl” terms arise, and can, depending on network architecture, destabilize gradient-descent solutions or paradoxically accelerate learning beyond pure gradient flow.
🧵⬇️
www.arxiv.org/abs/2510.02765
Curl Descent: Non-Gradient Learning Dynamics with Sign-Diverse Plasticity
Gradient-based algorithms are a cornerstone of artificial neural network training, yet it remains unclear whether biological neural networks use similar gradient-based strategies during learning. Expe...
www.arxiv.org
October 10, 2025 at 5:53 PM
🚨New spotlight paper at Neurips 2025🚨
We show that in sign-diverse networks, inherent non-gradient “curl” terms arise, and can, depending on network architecture, destabilize gradient-descent solutions or paradoxically accelerate learning beyond pure gradient flow.
🧵⬇️
www.arxiv.org/abs/2510.02765
We show that in sign-diverse networks, inherent non-gradient “curl” terms arise, and can, depending on network architecture, destabilize gradient-descent solutions or paradoxically accelerate learning beyond pure gradient flow.
🧵⬇️
www.arxiv.org/abs/2510.02765
Reposted by Hugo Ninou

Big week for astrocyte research: 3 new Science papers link astrocytes to behavior. We're excited to add to the momentum with our new PNAS paper: a theory, grounded in biology, proposing astrocytes as key players in memory storage and recall. w/ JJ Slotine and @krotov.bsky.social
(1/6)
(1/6)

May 28, 2025 at 7:44 PM
Big week for astrocyte research: 3 new Science papers link astrocytes to behavior. We're excited to add to the momentum with our new PNAS paper: a theory, grounded in biology, proposing astrocytes as key players in memory storage and recall. w/ JJ Slotine and @krotov.bsky.social
(1/6)
(1/6)
Reposted by Hugo Ninou

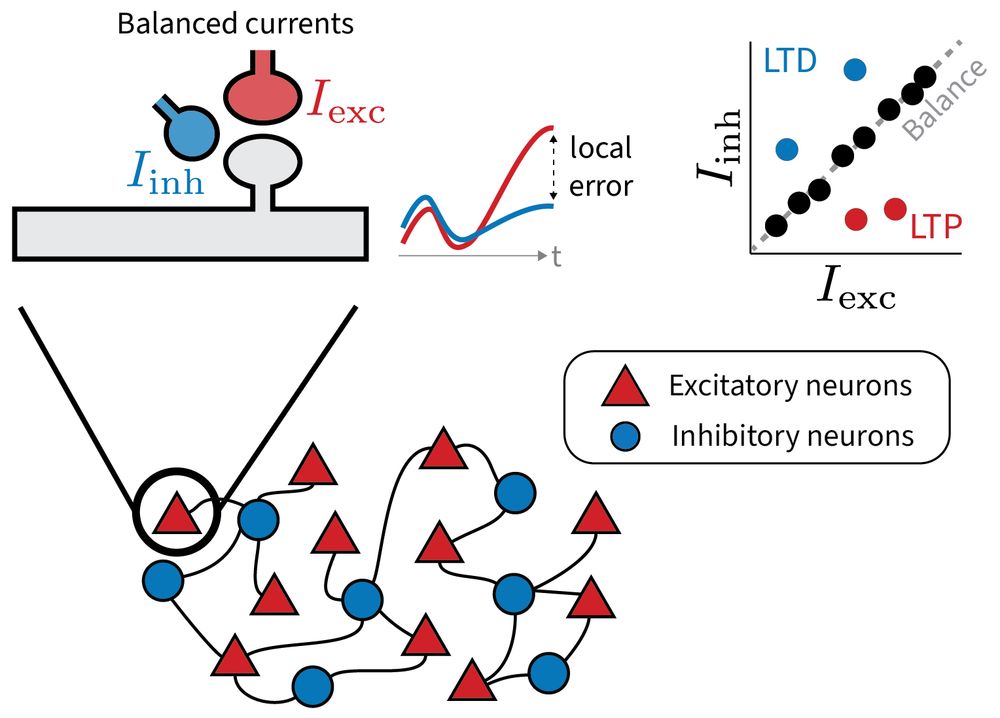
1/6 Why does the brain maintain such precise excitatory-inhibitory balance?
Our new preprint explores a provocative idea: Small, targeted deviations from this balance may serve a purpose: to encode local error signals for learning.
www.biorxiv.org/content/10.1...
led by @jrbch.bsky.social
Our new preprint explores a provocative idea: Small, targeted deviations from this balance may serve a purpose: to encode local error signals for learning.
www.biorxiv.org/content/10.1...
led by @jrbch.bsky.social
May 27, 2025 at 7:49 AM
1/6 Why does the brain maintain such precise excitatory-inhibitory balance?
Our new preprint explores a provocative idea: Small, targeted deviations from this balance may serve a purpose: to encode local error signals for learning.
www.biorxiv.org/content/10.1...
led by @jrbch.bsky.social
Our new preprint explores a provocative idea: Small, targeted deviations from this balance may serve a purpose: to encode local error signals for learning.
www.biorxiv.org/content/10.1...
led by @jrbch.bsky.social
Reposted by Hugo Ninou

(1/6) Excited to share a new preprint from our lab! Can large, deep nonlinear neural networks trained with indirect, low-dimensional error signals compete with full-fledged backpropagation? Tl;dr: Yes! arxiv.org/abs/2502.20580.

Training Large Neural Networks With Low-Dimensional Error Feedback
Training deep neural networks typically relies on backpropagating high dimensional error signals a computationally intensive process with little evidence supporting its implementation in the brain. Ho...
arxiv.org
March 23, 2025 at 9:23 AM
(1/6) Excited to share a new preprint from our lab! Can large, deep nonlinear neural networks trained with indirect, low-dimensional error signals compete with full-fledged backpropagation? Tl;dr: Yes! arxiv.org/abs/2502.20580.
🚨 Paper Alert! 🚨
1/n Thrilled to share our latest research, now published in Nature Communications! 🎉 This study dives deep into how the cerebellum shapes cortical preparatory activity during motor adaptation.
www.nature.com/articles/s41...
#neuroskyence #motorcontrol #cerebellum #motoradaptation
1/n Thrilled to share our latest research, now published in Nature Communications! 🎉 This study dives deep into how the cerebellum shapes cortical preparatory activity during motor adaptation.
www.nature.com/articles/s41...
#neuroskyence #motorcontrol #cerebellum #motoradaptation
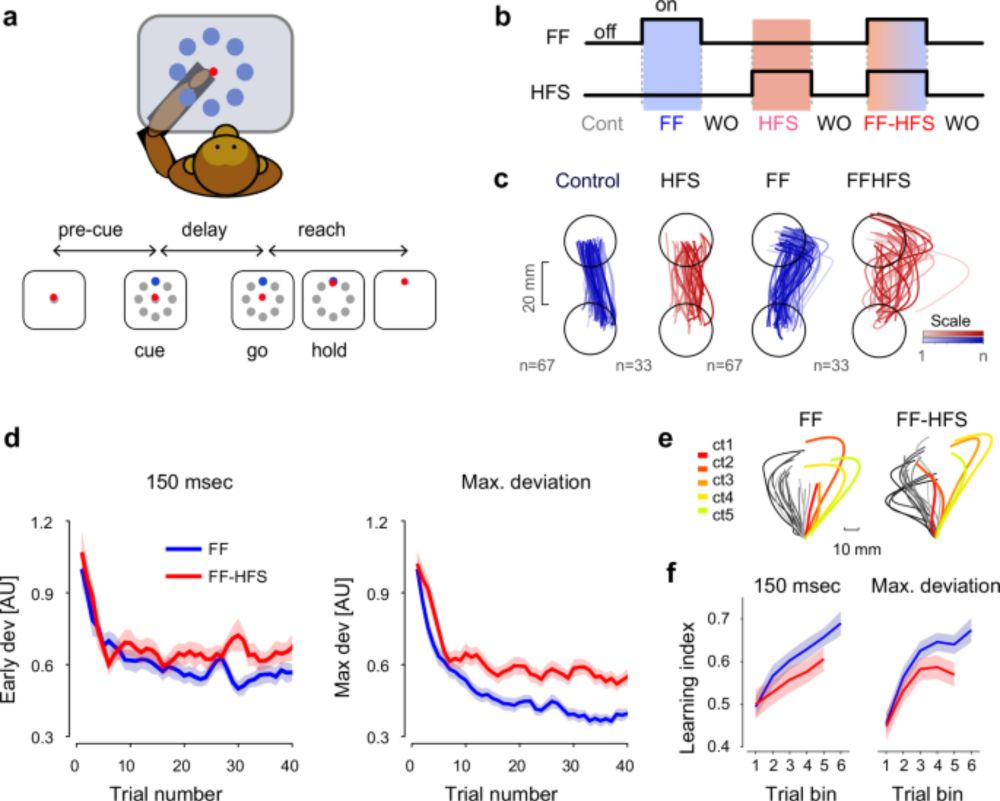
Cerebellar output shapes cortical preparatory activity during motor adaptation - Nature Communications
Functional role of the cerebellum in motor adaptation is not fully understood. The authors show that cerebellar signals act as low-dimensional feedback which constrains the structure of the preparator...
www.nature.com
March 22, 2025 at 6:35 PM
🚨 Paper Alert! 🚨
1/n Thrilled to share our latest research, now published in Nature Communications! 🎉 This study dives deep into how the cerebellum shapes cortical preparatory activity during motor adaptation.
www.nature.com/articles/s41...
#neuroskyence #motorcontrol #cerebellum #motoradaptation
1/n Thrilled to share our latest research, now published in Nature Communications! 🎉 This study dives deep into how the cerebellum shapes cortical preparatory activity during motor adaptation.
www.nature.com/articles/s41...
#neuroskyence #motorcontrol #cerebellum #motoradaptation
Reposted by Hugo Ninou

Created a starter pack of neuroscience in/from Paris.
Let me know if you want to be added (the 'from' can include those not in Paris anymore) or just tap in if you want to know what we're talking about!
Regardless, please re-tweet!
go.bsky.app/3Zs9w5w
Let me know if you want to be added (the 'from' can include those not in Paris anymore) or just tap in if you want to know what we're talking about!
Regardless, please re-tweet!
go.bsky.app/3Zs9w5w
December 16, 2024 at 8:45 PM
Created a starter pack of neuroscience in/from Paris.
Let me know if you want to be added (the 'from' can include those not in Paris anymore) or just tap in if you want to know what we're talking about!
Regardless, please re-tweet!
go.bsky.app/3Zs9w5w
Let me know if you want to be added (the 'from' can include those not in Paris anymore) or just tap in if you want to know what we're talking about!
Regardless, please re-tweet!
go.bsky.app/3Zs9w5w
Reposted by Hugo Ninou

For the Blueskyers interested in #NeuroAI 🧠🤖,
I created a starter pack! Please comment on this if you are not on the list and working in this field 🙂
go.bsky.app/CscFTAr
I created a starter pack! Please comment on this if you are not on the list and working in this field 🙂
go.bsky.app/CscFTAr
October 17, 2024 at 8:04 PM
For the Blueskyers interested in #NeuroAI 🧠🤖,
I created a starter pack! Please comment on this if you are not on the list and working in this field 🙂
go.bsky.app/CscFTAr
I created a starter pack! Please comment on this if you are not on the list and working in this field 🙂
go.bsky.app/CscFTAr