



Tiago Pimentel
@tpimentel.bsky.social
Postdoc at ETH. Formerly, PhD student at the University of Cambridge :)
Pinned
Tiago Pimentel
@tpimentel.bsky.social
· Jun 4
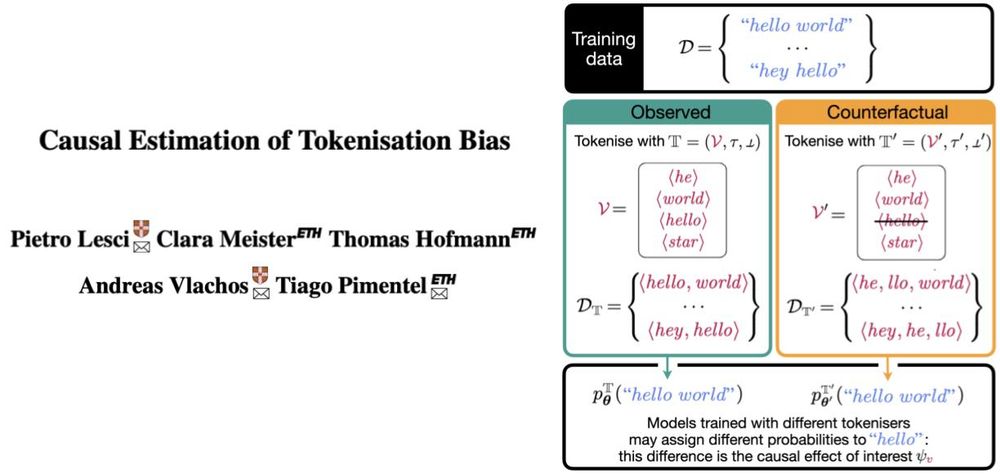
A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
Reposted by Tiago Pimentel

Thrilled to share my first paper! 📄
We prove optimal tokenization is NP-hard on bounded alphabets (like bytes)—even unary for direct tokenization!
Big thanks @tpimentel.bsky.social, @philipwitti.bsky.social & Dennis Komm for the mentorship! Best birthday gift. 🎂
arxiv.org/abs/2511.15709
We prove optimal tokenization is NP-hard on bounded alphabets (like bytes)—even unary for direct tokenization!
Big thanks @tpimentel.bsky.social, @philipwitti.bsky.social & Dennis Komm for the mentorship! Best birthday gift. 🎂
arxiv.org/abs/2511.15709
Tokenisers are a vital part of LLMs, but how hard is it to find an optimal one? 🤔 Considering arbitrarily large alphabets, prior work showed this is NP-hard. But what if we use bytes instead? Or unary strings like a, aa, aaa, ...? In our new paper, we show this is still hard, NP-hard!

November 20, 2025 at 3:27 PM
Thrilled to share my first paper! 📄
We prove optimal tokenization is NP-hard on bounded alphabets (like bytes)—even unary for direct tokenization!
Big thanks @tpimentel.bsky.social, @philipwitti.bsky.social & Dennis Komm for the mentorship! Best birthday gift. 🎂
arxiv.org/abs/2511.15709
We prove optimal tokenization is NP-hard on bounded alphabets (like bytes)—even unary for direct tokenization!
Big thanks @tpimentel.bsky.social, @philipwitti.bsky.social & Dennis Komm for the mentorship! Best birthday gift. 🎂
arxiv.org/abs/2511.15709
Tokenisers are a vital part of LLMs, but how hard is it to find an optimal one? 🤔 Considering arbitrarily large alphabets, prior work showed this is NP-hard. But what if we use bytes instead? Or unary strings like a, aa, aaa, ...? In our new paper, we show this is still hard, NP-hard!
November 20, 2025 at 3:05 PM
Tokenisers are a vital part of LLMs, but how hard is it to find an optimal one? 🤔 Considering arbitrarily large alphabets, prior work showed this is NP-hard. But what if we use bytes instead? Or unary strings like a, aa, aaa, ...? In our new paper, we show this is still hard, NP-hard!
Reposted by Tiago Pimentel

Interested in provable guarantees and fundamental limitations of XAI? Join us at the "Theory of Explainable AI" workshop Dec 2 in Copenhagen! @ellis.eu @euripsconf.bsky.social
Speakers: @jessicahullman.bsky.social @doloresromerom.bsky.social @tpimentel.bsky.social
Call for Contributions: Oct 15
Speakers: @jessicahullman.bsky.social @doloresromerom.bsky.social @tpimentel.bsky.social
Call for Contributions: Oct 15

Theory of XAI Workshop
Explainable AI (XAI) is now deployed across a wide range of settings, including high-stakes domains in which misleading explanations can cause real harm. For example, explanations are required by law ...
sites.google.com
October 7, 2025 at 12:53 PM
Interested in provable guarantees and fundamental limitations of XAI? Join us at the "Theory of Explainable AI" workshop Dec 2 in Copenhagen! @ellis.eu @euripsconf.bsky.social
Speakers: @jessicahullman.bsky.social @doloresromerom.bsky.social @tpimentel.bsky.social
Call for Contributions: Oct 15
Speakers: @jessicahullman.bsky.social @doloresromerom.bsky.social @tpimentel.bsky.social
Call for Contributions: Oct 15
Reposted by Tiago Pimentel

Interested in language models, brains, and concepts? Check out our COLM 2025 🔦 Spotlight paper!
(And if you’re at COLM, come hear about it on Tuesday – sessions Spotlight 2 & Poster 2)!
(And if you’re at COLM, come hear about it on Tuesday – sessions Spotlight 2 & Poster 2)!

October 4, 2025 at 2:15 AM
Interested in language models, brains, and concepts? Check out our COLM 2025 🔦 Spotlight paper!
(And if you’re at COLM, come hear about it on Tuesday – sessions Spotlight 2 & Poster 2)!
(And if you’re at COLM, come hear about it on Tuesday – sessions Spotlight 2 & Poster 2)!
Reposted by Tiago Pimentel

Accepted to EMNLP (and more to come 👀)! The camera ready version is now online---very happy with how this turned out
arxiv.org/abs/2507.01234
arxiv.org/abs/2507.01234
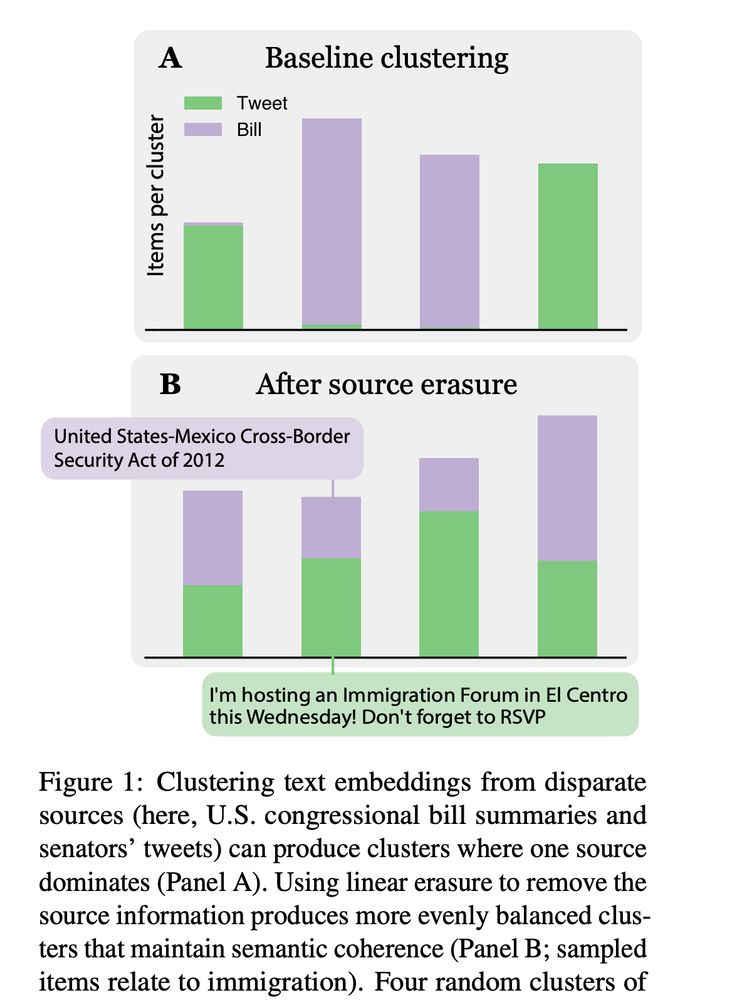
New preprint! Have you ever tried to cluster text embeddings from different sources, but the clusters just reproduce the sources? Or attempted to retrieve similar documents across multiple languages, and even multilingual embeddings return items in the same language?
Turns out there's an easy fix🧵
Turns out there's an easy fix🧵
September 24, 2025 at 3:21 PM
Accepted to EMNLP (and more to come 👀)! The camera ready version is now online---very happy with how this turned out
arxiv.org/abs/2507.01234
arxiv.org/abs/2507.01234
LLMs are trained to mimic a “true” distribution—their reducing cross-entropy then confirms they get closer to this target while training. Do similar models approach this target distribution in similar ways, though? 🤔 Not really! Our new paper studies this, finding 4-convergence phases in training 🧵

October 1, 2025 at 6:08 PM
LLMs are trained to mimic a “true” distribution—their reducing cross-entropy then confirms they get closer to this target while training. Do similar models approach this target distribution in similar ways, though? 🤔 Not really! Our new paper studies this, finding 4-convergence phases in training 🧵
Very happy this paper got accepted to NeurIPS 2025 as a Spotlight! 😁
Main takeaway: In mechanistic interpretability, we need assumptions about how DNNs encode concepts in their representations (eg, the linear representation hypothesis). Without them, we can claim any DNN implements any algorithm!
Main takeaway: In mechanistic interpretability, we need assumptions about how DNNs encode concepts in their representations (eg, the linear representation hypothesis). Without them, we can claim any DNN implements any algorithm!
Mechanistic interpretability often relies on *interventions* to study how DNNs work. Are these interventions enough to guarantee the features we find are not spurious? No!⚠️ In our new paper, we show many mech int methods implicitly rely on the linear representation hypothesis🧵

October 1, 2025 at 3:00 PM
Very happy this paper got accepted to NeurIPS 2025 as a Spotlight! 😁
Main takeaway: In mechanistic interpretability, we need assumptions about how DNNs encode concepts in their representations (eg, the linear representation hypothesis). Without them, we can claim any DNN implements any algorithm!
Main takeaway: In mechanistic interpretability, we need assumptions about how DNNs encode concepts in their representations (eg, the linear representation hypothesis). Without them, we can claim any DNN implements any algorithm!
Honoured to receive two (!!) SAC highlights awards at #ACL2025 😁 (Conveniently placed on the same slide!)
With the amazing: @philipwitti.bsky.social, @gregorbachmann.bsky.social and @wegotlieb.bsky.social,
@cuiding.bsky.social, Giovanni Acampa, @alexwarstadt.bsky.social, @tamaregev.bsky.social
With the amazing: @philipwitti.bsky.social, @gregorbachmann.bsky.social and @wegotlieb.bsky.social,
@cuiding.bsky.social, Giovanni Acampa, @alexwarstadt.bsky.social, @tamaregev.bsky.social


July 31, 2025 at 7:41 AM
Honoured to receive two (!!) SAC highlights awards at #ACL2025 😁 (Conveniently placed on the same slide!)
With the amazing: @philipwitti.bsky.social, @gregorbachmann.bsky.social and @wegotlieb.bsky.social,
@cuiding.bsky.social, Giovanni Acampa, @alexwarstadt.bsky.social, @tamaregev.bsky.social
With the amazing: @philipwitti.bsky.social, @gregorbachmann.bsky.social and @wegotlieb.bsky.social,
@cuiding.bsky.social, Giovanni Acampa, @alexwarstadt.bsky.social, @tamaregev.bsky.social
We are presenting this paper at #ACL2025 😁 Find us at poster session 4 (Wednesday morning, 11h~12h30) to learn more about tokenisation bias!
A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
July 27, 2025 at 11:59 AM
We are presenting this paper at #ACL2025 😁 Find us at poster session 4 (Wednesday morning, 11h~12h30) to learn more about tokenisation bias!
@philipwitti.bsky.social will be presenting our paper "Tokenisation is NP-Complete" at #ACL2025 😁 Come to the language modelling 2 session (Wednesday morning, 9h~10h30) to learn more about how challenging tokenisation can be!
BPE is a greedy method to find a tokeniser which maximises compression! Why don't we try to find properly optimal tokenisers instead? Well, it seems this is a pretty difficult—in fact, NP-complete—problem!🤯
New paper + @philipwitti.bsky.social
@gregorbachmann.bsky.social :) arxiv.org/abs/2412.15210
New paper + @philipwitti.bsky.social
@gregorbachmann.bsky.social :) arxiv.org/abs/2412.15210

Tokenisation is NP-Complete
In this work, we prove the NP-completeness of two variants of tokenisation, defined as the problem of compressing a dataset to at most $δ$ symbols by either finding a vocabulary directly (direct token...
arxiv.org
July 27, 2025 at 9:41 AM
@philipwitti.bsky.social will be presenting our paper "Tokenisation is NP-Complete" at #ACL2025 😁 Come to the language modelling 2 session (Wednesday morning, 9h~10h30) to learn more about how challenging tokenisation can be!
Reposted by Tiago Pimentel

Headed to Vienna for #ACL2025 to present our tokenisation bias paper and co-organise the L2M2 workshop on memorisation in language models. Reach out to chat about tokenisation, memorisation, and all things pre-training (esp. data-related topics)!
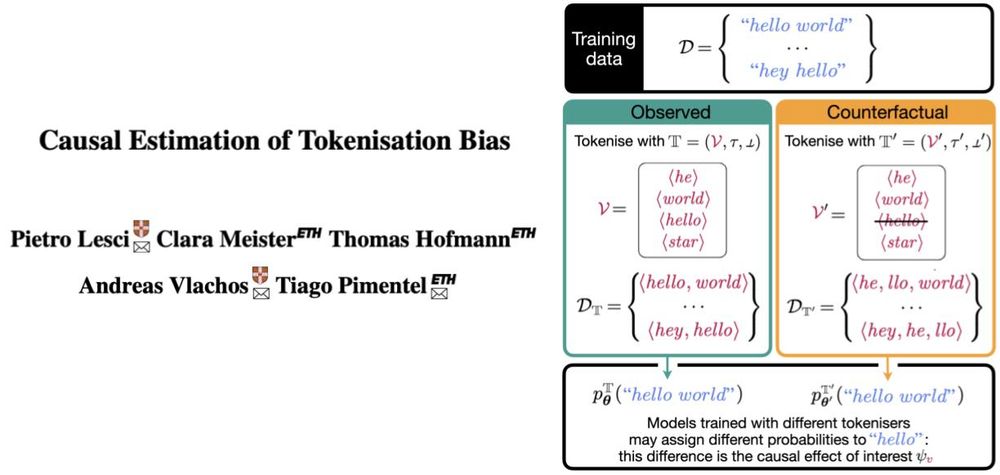
All modern LLMs run on top of a tokeniser, an often overlooked “preprocessing detail”. But what if that tokeniser systematically affects model behaviour? We call this tokenisation bias.
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
July 27, 2025 at 6:40 AM
Headed to Vienna for #ACL2025 to present our tokenisation bias paper and co-organise the L2M2 workshop on memorisation in language models. Reach out to chat about tokenisation, memorisation, and all things pre-training (esp. data-related topics)!
Reposted by Tiago Pimentel

Causal Abstraction, the theory behind DAS, tests if a network realizes a given algorithm. We show (w/ @denissutter.bsky.social, T. Hofmann, @tpimentel.bsky.social ) that the theory collapses without the linear representation hypothesis—a problem we call the non-linear representation dilemma.

July 17, 2025 at 10:57 AM
Causal Abstraction, the theory behind DAS, tests if a network realizes a given algorithm. We show (w/ @denissutter.bsky.social, T. Hofmann, @tpimentel.bsky.social ) that the theory collapses without the linear representation hypothesis—a problem we call the non-linear representation dilemma.
Mechanistic interpretability often relies on *interventions* to study how DNNs work. Are these interventions enough to guarantee the features we find are not spurious? No!⚠️ In our new paper, we show many mech int methods implicitly rely on the linear representation hypothesis🧵
July 14, 2025 at 12:15 PM
Mechanistic interpretability often relies on *interventions* to study how DNNs work. Are these interventions enough to guarantee the features we find are not spurious? No!⚠️ In our new paper, we show many mech int methods implicitly rely on the linear representation hypothesis🧵
Reposted by Tiago Pimentel
All modern LLMs run on top of a tokeniser, an often overlooked “preprocessing detail”. But what if that tokeniser systematically affects model behaviour? We call this tokenisation bias.
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
June 5, 2025 at 10:43 AM
All modern LLMs run on top of a tokeniser, an often overlooked “preprocessing detail”. But what if that tokeniser systematically affects model behaviour? We call this tokenisation bias.
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
Let’s talk about it and why it matters👇
@aclmeeting.bsky.social #ACL2025 #NLProc
Reposted by Tiago Pimentel

The word "laundry" contains both steps of the laundry process:
1. Undry
2. Dry
1. Undry
2. Dry
June 4, 2025 at 7:14 PM
The word "laundry" contains both steps of the laundry process:
1. Undry
2. Dry
1. Undry
2. Dry
Reposted by Tiago Pimentel

Love this! Especially the explicit operationalization of what “bias” they are measuring via specifying the relevant counterfactual.
Definitely an approach that more papers talking about effects can incorporate to better clarify what the phenomenon they are studying.
Definitely an approach that more papers talking about effects can incorporate to better clarify what the phenomenon they are studying.
A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
June 4, 2025 at 3:55 PM
Love this! Especially the explicit operationalization of what “bias” they are measuring via specifying the relevant counterfactual.
Definitely an approach that more papers talking about effects can incorporate to better clarify what the phenomenon they are studying.
Definitely an approach that more papers talking about effects can incorporate to better clarify what the phenomenon they are studying.
If you use LLMs, tokenisation bias probably affects you:
* Text generation: tokenisation bias ⇒ length bias 🤯
* Psycholinguistics: tokenisation bias ⇒ systematically biased surprisal estimates 🫠
* Interpretability: tokenisation bias ⇒ biased logits 🤔
* Text generation: tokenisation bias ⇒ length bias 🤯
* Psycholinguistics: tokenisation bias ⇒ systematically biased surprisal estimates 🫠
* Interpretability: tokenisation bias ⇒ biased logits 🤔
A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
June 4, 2025 at 2:55 PM
If you use LLMs, tokenisation bias probably affects you:
* Text generation: tokenisation bias ⇒ length bias 🤯
* Psycholinguistics: tokenisation bias ⇒ systematically biased surprisal estimates 🫠
* Interpretability: tokenisation bias ⇒ biased logits 🤔
* Text generation: tokenisation bias ⇒ length bias 🤯
* Psycholinguistics: tokenisation bias ⇒ systematically biased surprisal estimates 🫠
* Interpretability: tokenisation bias ⇒ biased logits 🤔
A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
June 4, 2025 at 10:51 AM
A string may get 17 times less probability if tokenised as two symbols (e.g., ⟨he, llo⟩) than as one (e.g., ⟨hello⟩)—by an LM trained from scratch in each situation! Our new ACL paper proposes an observational method to estimate this causal effect! Longer thread soon!
If you're finishing your camera-ready for ACL or ICML and want to cite co-first authors more fairly, I just made a simple fix to do this! Just add $^*$ to the authors' names in your bibtex, and the citations should change :)
github.com/tpimentelms/...
github.com/tpimentelms/...

May 29, 2025 at 8:53 AM
If you're finishing your camera-ready for ACL or ICML and want to cite co-first authors more fairly, I just made a simple fix to do this! Just add $^*$ to the authors' names in your bibtex, and the citations should change :)
github.com/tpimentelms/...
github.com/tpimentelms/...
Reposted by Tiago Pimentel

⭐🗣️New preprint out: 🗣️⭐ “Using Information Theory to Characterize Prosodic Typology: The Case of Tone, Pitch-Accent and Stress-Accent” with @cuiding.bsky.social , Giovanni Acampa, @tpimentel.bsky.social , @alexwarstadt.bsky.social ,Tamar Regev: arxiv.org/abs/2505.07659

Using Information Theory to Characterize Prosodic Typology: The Case of Tone, Pitch-Accent and Stress-Accent
This paper argues that the relationship between lexical identity and prosody -- one well-studied parameter of linguistic variation -- can be characterized using information theory. We predict that lan...
arxiv.org
May 13, 2025 at 1:21 PM
⭐🗣️New preprint out: 🗣️⭐ “Using Information Theory to Characterize Prosodic Typology: The Case of Tone, Pitch-Accent and Stress-Accent” with @cuiding.bsky.social , Giovanni Acampa, @tpimentel.bsky.social , @alexwarstadt.bsky.social ,Tamar Regev: arxiv.org/abs/2505.07659
Reposted by Tiago Pimentel

How do language models generalize from information they learn in-context vs. via finetuning? In arxiv.org/abs/2505.00661 we show that in-context learning can generalize more flexibly, illustrating key differences in the inductive biases of these modes of learning — and ways to improve finetuning. 1/
arxiv.org
May 2, 2025 at 5:02 PM
How do language models generalize from information they learn in-context vs. via finetuning? In arxiv.org/abs/2505.00661 we show that in-context learning can generalize more flexibly, illustrating key differences in the inductive biases of these modes of learning — and ways to improve finetuning. 1/
Super happy we got this award for our paper on memorisation 😁🎉 congrats to the team and in particular to @pietrolesci.bsky.social, who led the project! Pietro is super smart, creative, hard-working, and on the job market -- you should hire him if you can :)

🎉 Congratulations @pietrolesci.bsky.social, Clara Meister, Thomas Hofmann, @andreasvlachos.bsky.social & Tiago Pimentel! They won Publication of the Year at our annual Hall of Fame awards last week for their paper on 'Causal Estimation of Memorisation Profiles'. www.cst.cam.ac.uk/announcing-w...

April 30, 2025 at 7:29 AM
Super happy we got this award for our paper on memorisation 😁🎉 congrats to the team and in particular to @pietrolesci.bsky.social, who led the project! Pietro is super smart, creative, hard-working, and on the job market -- you should hire him if you can :)
Reposted by Tiago Pimentel

Honoured to receive this award! Tagging @pietrolesci.bsky.social and @tpimentel.bsky.social !
🎉 Congratulations @pietrolesci.bsky.social, Clara Meister, Thomas Hofmann, @andreasvlachos.bsky.social & Tiago Pimentel! They won Publication of the Year at our annual Hall of Fame awards last week for their paper on 'Causal Estimation of Memorisation Profiles'. www.cst.cam.ac.uk/announcing-w...
April 29, 2025 at 9:31 PM
Honoured to receive this award! Tagging @pietrolesci.bsky.social and @tpimentel.bsky.social !
Reposted by Tiago Pimentel
I'm truly honoured that our paper "Causal Estimation of Memorisation Profiles" has been selected as the Paper of the Year by @cst.cam.ac.uk 🎉
I thank my amazing co-authors Clara Meister, Thomas Hofmann, @tpimentel.bsky.social, and my great advisor and co-author @andreasvlachos.bsky.social!
I thank my amazing co-authors Clara Meister, Thomas Hofmann, @tpimentel.bsky.social, and my great advisor and co-author @andreasvlachos.bsky.social!
🎉 Congratulations @pietrolesci.bsky.social, Clara Meister, Thomas Hofmann, @andreasvlachos.bsky.social & Tiago Pimentel! They won Publication of the Year at our annual Hall of Fame awards last week for their paper on 'Causal Estimation of Memorisation Profiles'. www.cst.cam.ac.uk/announcing-w...
April 30, 2025 at 4:10 AM
I'm truly honoured that our paper "Causal Estimation of Memorisation Profiles" has been selected as the Paper of the Year by @cst.cam.ac.uk 🎉
I thank my amazing co-authors Clara Meister, Thomas Hofmann, @tpimentel.bsky.social, and my great advisor and co-author @andreasvlachos.bsky.social!
I thank my amazing co-authors Clara Meister, Thomas Hofmann, @tpimentel.bsky.social, and my great advisor and co-author @andreasvlachos.bsky.social!
Reposted by Tiago Pimentel

💡 New ICLR paper! 💡
"On Linear Representations and Pretraining Data Frequency in Language Models":
We provide an explanation for when & why linear representations form in large (or small) language models.
Led by @jackmerullo.bsky.social, w/ @nlpnoah.bsky.social & @sarah-nlp.bsky.social
"On Linear Representations and Pretraining Data Frequency in Language Models":
We provide an explanation for when & why linear representations form in large (or small) language models.
Led by @jackmerullo.bsky.social, w/ @nlpnoah.bsky.social & @sarah-nlp.bsky.social

April 25, 2025 at 1:55 AM
💡 New ICLR paper! 💡
"On Linear Representations and Pretraining Data Frequency in Language Models":
We provide an explanation for when & why linear representations form in large (or small) language models.
Led by @jackmerullo.bsky.social, w/ @nlpnoah.bsky.social & @sarah-nlp.bsky.social
"On Linear Representations and Pretraining Data Frequency in Language Models":
We provide an explanation for when & why linear representations form in large (or small) language models.
Led by @jackmerullo.bsky.social, w/ @nlpnoah.bsky.social & @sarah-nlp.bsky.social