
ammar i marvi
@aimarvi.bsky.social
59 followers
160 following
13 posts
vision lab @ harvard
[i am] unbearably naive
Posts
Media
Videos
Starter Packs
Reposted by ammar i marvi



Reposted by ammar i marvi

Reposted by ammar i marvi


Reposted by ammar i marvi

Jenelle Feather
@jfeather.bsky.social
· Apr 24

Discriminating image representations with principal distortions
Image representations (artificial or biological) are often compared in terms of their global geometric structure; however, representations with similar global structure can have strikingly...
openreview.net

ammar i marvi
@aimarvi.bsky.social
· Apr 22

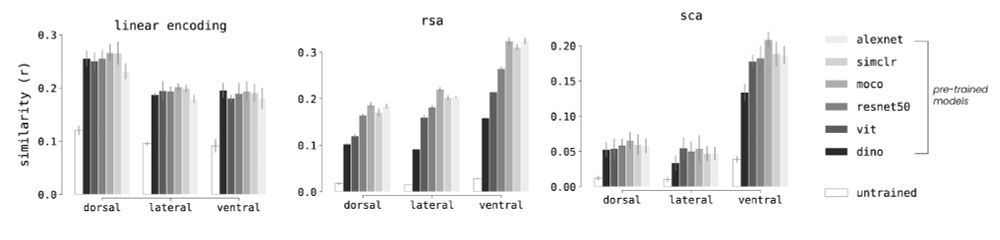
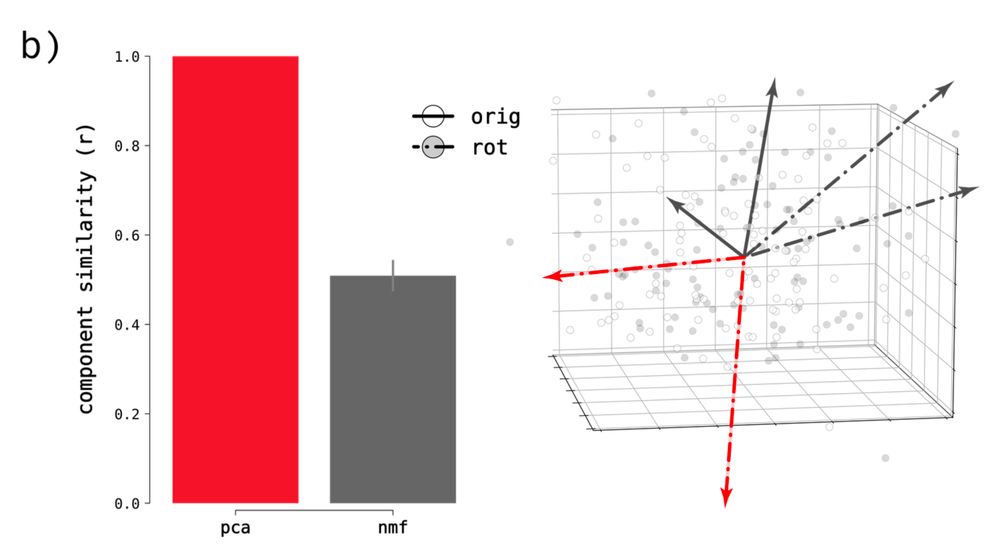
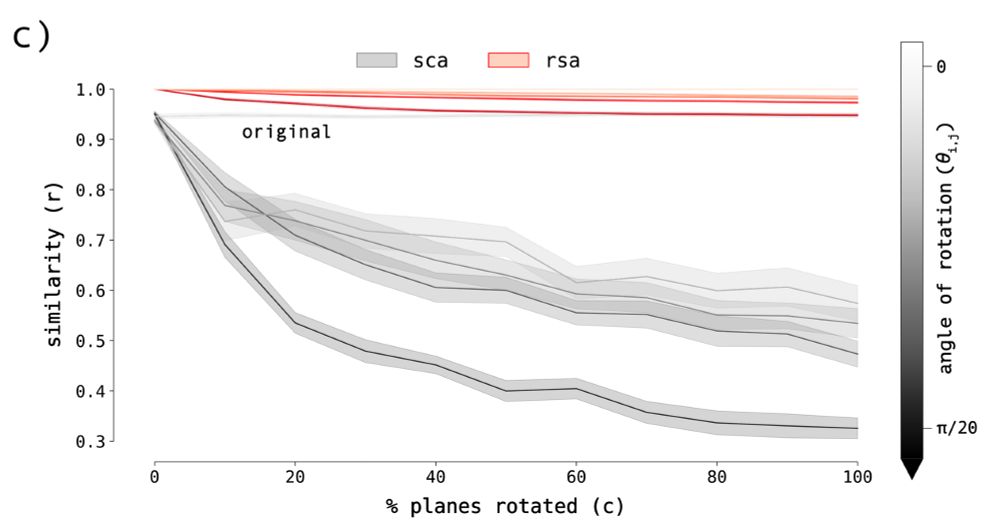
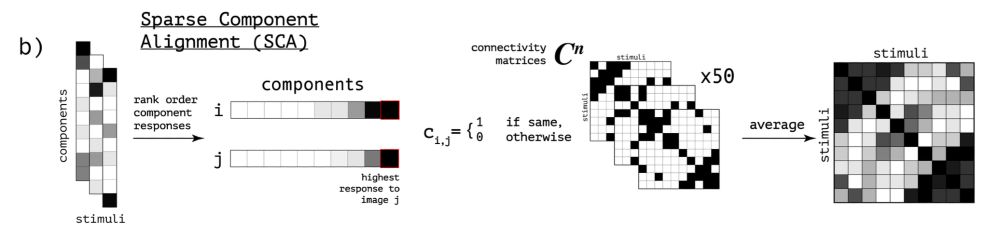
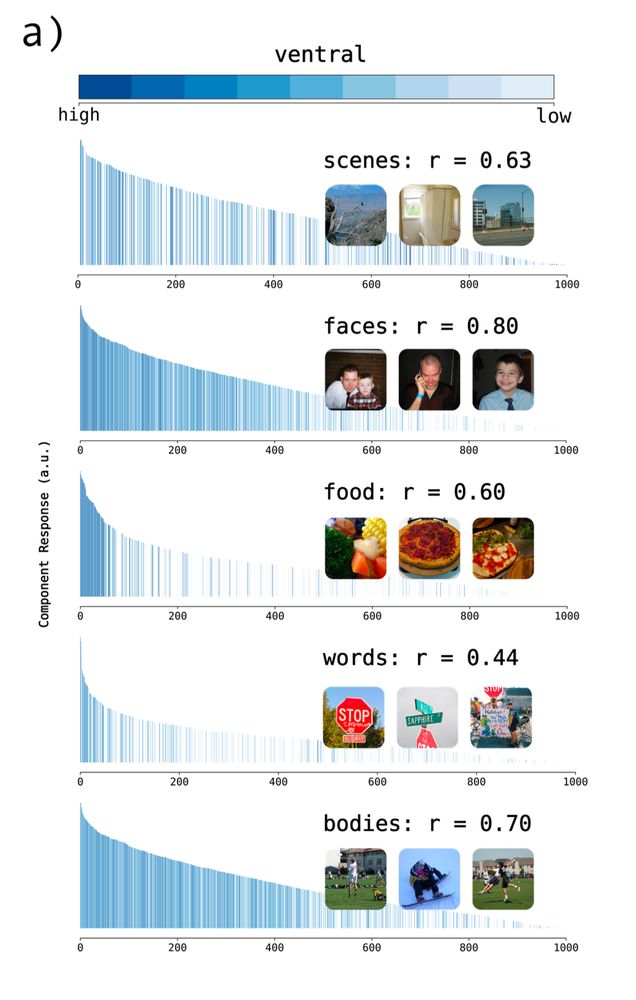
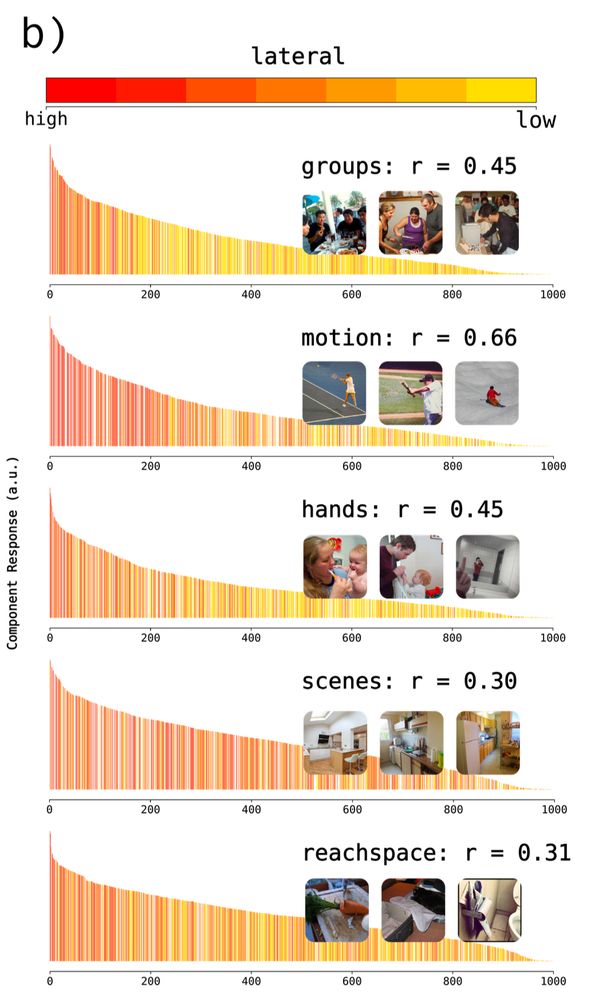
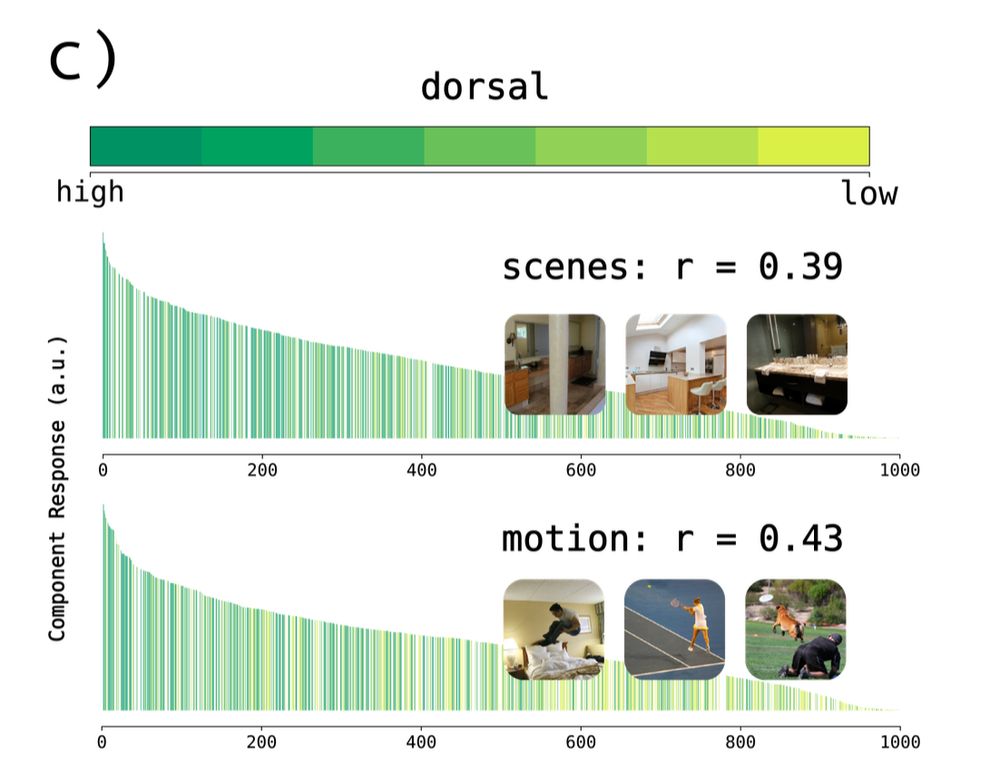
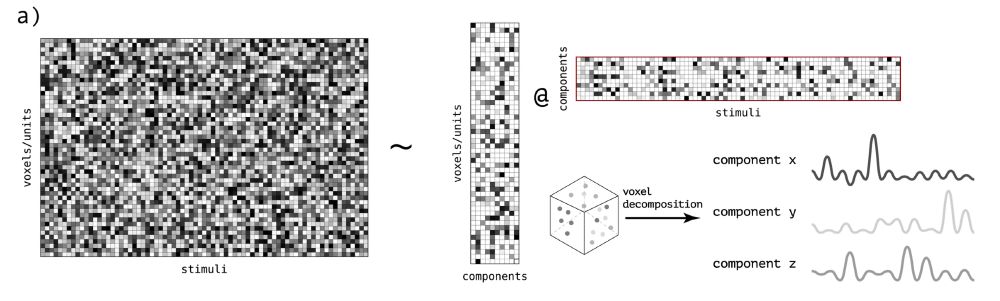
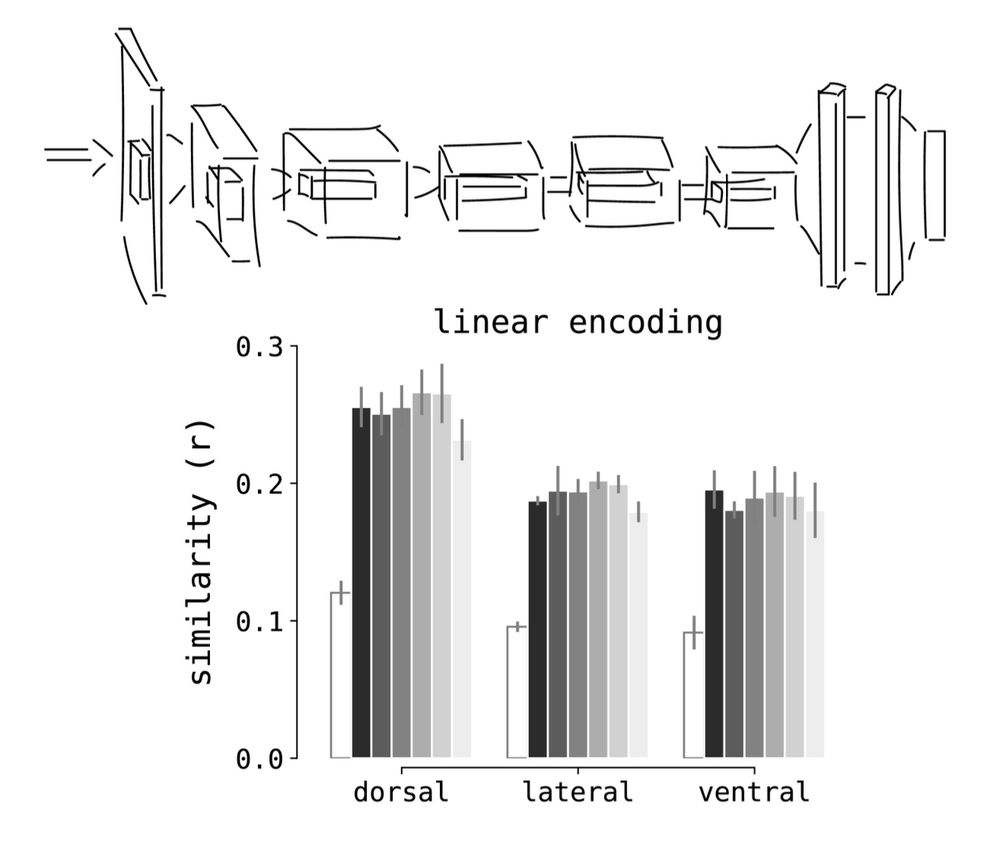
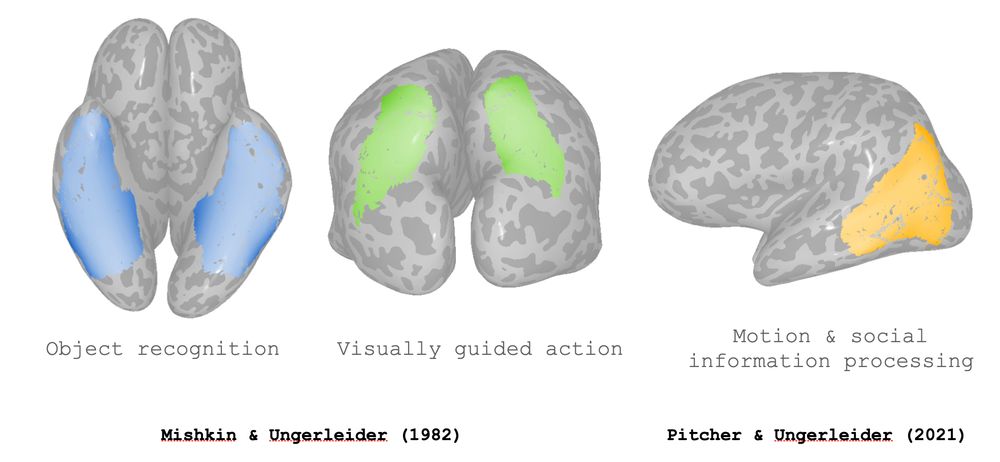
Sparse components distinguish visual pathways & their alignment to...
The ventral, dorsal, and lateral streams in high-level human visual cortex are implicated in distinct functional processes. Yet, deep neural networks (DNNs) trained on a single task model the...
openreview.net
ammar i marvi
@aimarvi.bsky.social
· Apr 22

ammar i marvi
@aimarvi.bsky.social
· Apr 22
ammar i marvi
@aimarvi.bsky.social
· Apr 22
ammar i marvi
@aimarvi.bsky.social
· Apr 22
Sparse components distinguish visual pathways & their alignment to...
The ventral, dorsal, and lateral streams in high-level human visual cortex are implicated in distinct functional processes. Yet, deep neural networks (DNNs) trained on a single task model the...
openreview.net
Reposted by ammar i marvi
