Alaa El-Nouby
@alaaelnouby.bsky.social
350 followers
60 following
8 posts
Research Scientist at @Apple. Previous: @Meta (FAIR), @Inria, @MSFTResearch, @VectorInst and @UofG . Egyptian 🇪🇬
Posts
Media
Videos
Starter Packs
Reposted by Alaa El-Nouby


Reposted by Alaa El-Nouby



Alaa El-Nouby
@alaaelnouby.bsky.social
· Nov 22
Alaa El-Nouby
@alaaelnouby.bsky.social
· Nov 22
Reposted by Alaa El-Nouby

Reposted by Alaa El-Nouby



Reposted by Alaa El-Nouby





Alaa El-Nouby
@alaaelnouby.bsky.social
· Nov 22

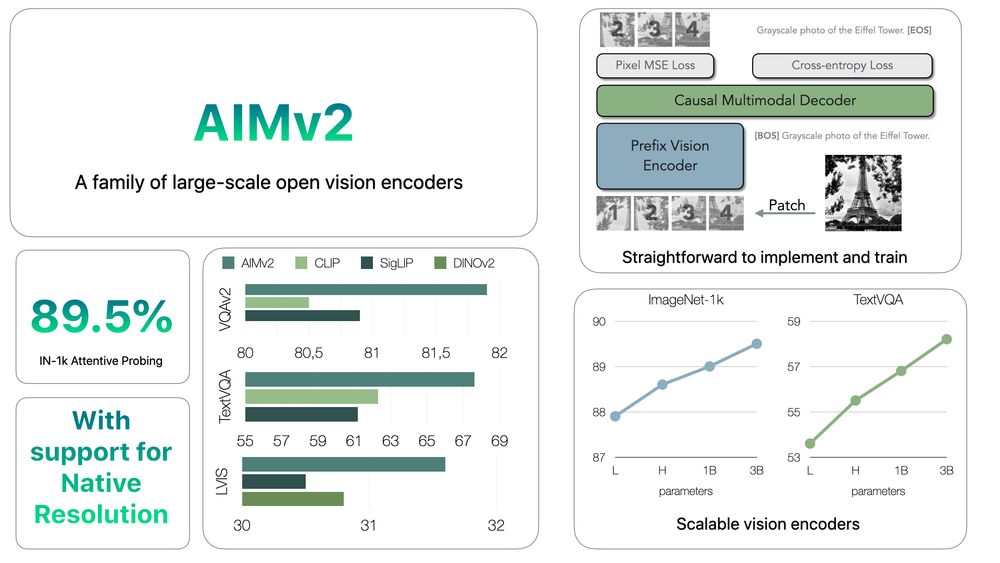
Multimodal Autoregressive Pre-training of Large Vision Encoders
We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in autoregressive pre-training of vision models, we extend this framework to a multimodal s...
arxiv.org




