
Belongie Lab
@belongielab.org
1.1K followers
41 following
32 posts
Computer Vision & Machine Learning
📍 Pioneer Centre for AI, University of Copenhagen
🌐 https://www.belongielab.org
Posts
Media
Videos
Starter Packs
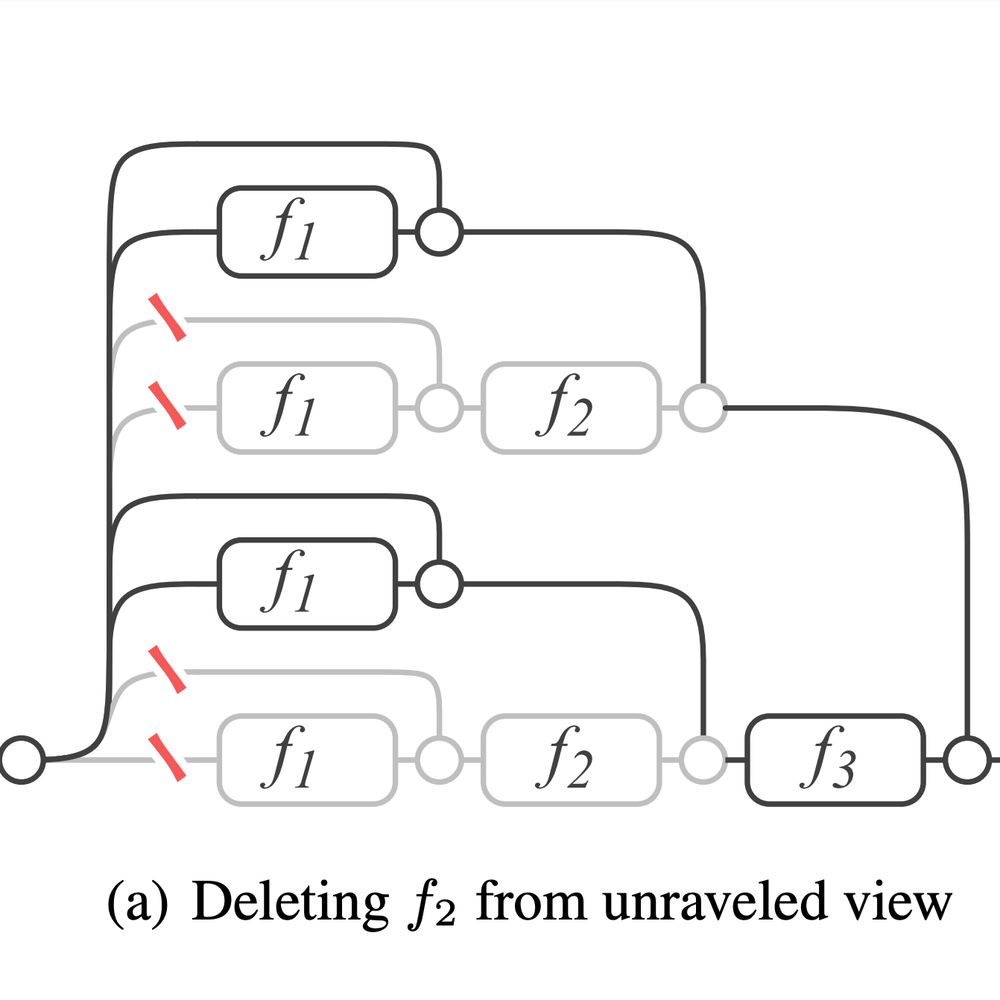
Belongie Lab
@belongielab.org
· Aug 13








Reposted by Belongie Lab


Reposted by Belongie Lab


Belongie Lab
@belongielab.org
· May 9
Belongie Lab
@belongielab.org
· May 9
Belongie Lab
@belongielab.org
· May 9
Belongie Lab
@belongielab.org
· May 9
Belongie Lab
@belongielab.org
· May 9


Belongie Lab
@belongielab.org
· May 8
Belongie Lab
@belongielab.org
· May 8
Belongie Lab
@belongielab.org
· May 8
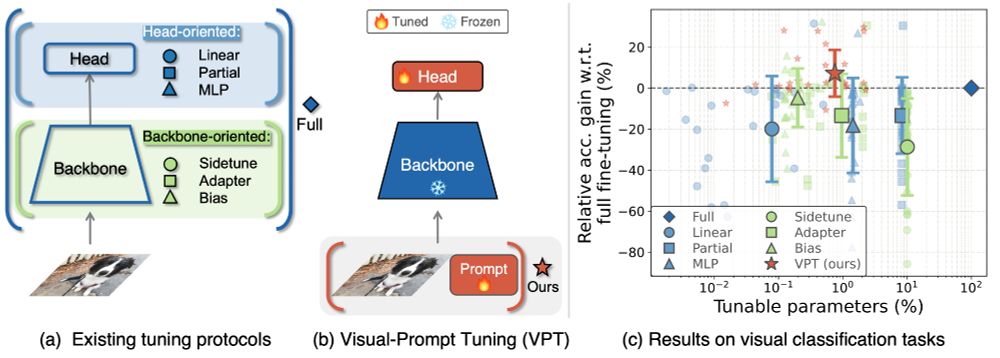





Reposted by Belongie Lab


Reposted by Belongie Lab


