



Benno Krojer
@bennokrojer.bsky.social
AI PhDing at Mila/McGill. Happily residing in Montreal 🥯❄️
Academic stuff: language grounding, vision+language, interp, rigorous & creative evals, cogsci
Other: many sports, urban explorations, puzzles/quizzes
bennokrojer.com
Academic stuff: language grounding, vision+language, interp, rigorous & creative evals, cogsci
Other: many sports, urban explorations, puzzles/quizzes
bennokrojer.com
Finally on a personal note, this will be the final paper of my PhD... what a journey it has been

February 11, 2026 at 3:10 PM
Finally on a personal note, this will be the final paper of my PhD... what a journey it has been
Pivoting to interpretability this year was great and i also wrote a blog post on this specifically:
bennokrojer.com/interp.html
bennokrojer.com/interp.html

February 11, 2026 at 3:10 PM
Pivoting to interpretability this year was great and i also wrote a blog post on this specifically:
bennokrojer.com/interp.html
bennokrojer.com/interp.html
This is a major lesson i will keep in mind for any future project:
Test your assumptions, do not assume the field already has settled
Test your assumptions, do not assume the field already has settled

February 11, 2026 at 3:10 PM
This is a major lesson i will keep in mind for any future project:
Test your assumptions, do not assume the field already has settled
Test your assumptions, do not assume the field already has settled
This project was definitely accelerated and shaped by Claude Code/Cursor. Building intuitive demos in interp is now much easier

February 11, 2026 at 3:10 PM
This project was definitely accelerated and shaped by Claude Code/Cursor. Building intuitive demos in interp is now much easier
Finally we do test it empirically: finding some models where the embedding matrix of the LLM already provides decently interpretable nearest neighbors
But this was not the full story yet...
@mariusmosbach.bsky.social and @elinorpd.bsky.social nudged me to use contextual embeddings
But this was not the full story yet...
@mariusmosbach.bsky.social and @elinorpd.bsky.social nudged me to use contextual embeddings

February 11, 2026 at 3:10 PM
Finally we do test it empirically: finding some models where the embedding matrix of the LLM already provides decently interpretable nearest neighbors
But this was not the full story yet...
@mariusmosbach.bsky.social and @elinorpd.bsky.social nudged me to use contextual embeddings
But this was not the full story yet...
@mariusmosbach.bsky.social and @elinorpd.bsky.social nudged me to use contextual embeddings
Then the project went "off-track" for a while, partially because we didn't question our assumptions enough:
We just assumed visual tokens going into an LLM would not be that interpretable (based on the literature and our intuition)
But we never fully tested it for many weeks!
We just assumed visual tokens going into an LLM would not be that interpretable (based on the literature and our intuition)
But we never fully tested it for many weeks!

February 11, 2026 at 3:10 PM
Then the project went "off-track" for a while, partially because we didn't question our assumptions enough:
We just assumed visual tokens going into an LLM would not be that interpretable (based on the literature and our intuition)
But we never fully tested it for many weeks!
We just assumed visual tokens going into an LLM would not be that interpretable (based on the literature and our intuition)
But we never fully tested it for many weeks!
The initial ideation phase:
Pivoting to a new direction, wondering what kind of interp work would be meaningful, getting feedback from my lab, ...
Pivoting to a new direction, wondering what kind of interp work would be meaningful, getting feedback from my lab, ...

February 11, 2026 at 3:10 PM
The initial ideation phase:
Pivoting to a new direction, wondering what kind of interp work would be meaningful, getting feedback from my lab, ...
Pivoting to a new direction, wondering what kind of interp work would be meaningful, getting feedback from my lab, ...
For every one of my papers, I try to include a "Behind the Scenes" section
I think this paper in particular has a lot going on behind the scenes; from lessons learned to personal reflections
let me share some
I think this paper in particular has a lot going on behind the scenes; from lessons learned to personal reflections
let me share some

February 11, 2026 at 3:10 PM
For every one of my papers, I try to include a "Behind the Scenes" section
I think this paper in particular has a lot going on behind the scenes; from lessons learned to personal reflections
let me share some
I think this paper in particular has a lot going on behind the scenes; from lessons learned to personal reflections
let me share some
One last puzzle 🧩
How can LatentLens outperform EmbeddingLens even at layer 0?
Our hypothsis: Visual tokens arrive already packaged in a semantic format
Concretely: An input visual token might have the highest similarity with text representations at e.g. LLM layer 8
We call this "Mid-Layer Leap"
How can LatentLens outperform EmbeddingLens even at layer 0?
Our hypothsis: Visual tokens arrive already packaged in a semantic format
Concretely: An input visual token might have the highest similarity with text representations at e.g. LLM layer 8
We call this "Mid-Layer Leap"

February 11, 2026 at 2:12 PM
One last puzzle 🧩
How can LatentLens outperform EmbeddingLens even at layer 0?
Our hypothsis: Visual tokens arrive already packaged in a semantic format
Concretely: An input visual token might have the highest similarity with text representations at e.g. LLM layer 8
We call this "Mid-Layer Leap"
How can LatentLens outperform EmbeddingLens even at layer 0?
Our hypothsis: Visual tokens arrive already packaged in a semantic format
Concretely: An input visual token might have the highest similarity with text representations at e.g. LLM layer 8
We call this "Mid-Layer Leap"
Beyond our controlled setup, we also show how LatentLens works much better than baselines on off-the-shelf Qwen2-VL-7B-Instruct

February 11, 2026 at 2:12 PM
Beyond our controlled setup, we also show how LatentLens works much better than baselines on off-the-shelf Qwen2-VL-7B-Instruct
With this automatic metric, we can compare LogitLens, EmbeddingLens and LatentLens on 9 model combinations that we train (3 vision encoders x 3 LLMs)
The two baselines are a mixed bag: some models and some layers are okay but many others not
LatentLens shows high interpretability across the board
The two baselines are a mixed bag: some models and some layers are okay but many others not
LatentLens shows high interpretability across the board

February 11, 2026 at 2:12 PM
With this automatic metric, we can compare LogitLens, EmbeddingLens and LatentLens on 9 model combinations that we train (3 vision encoders x 3 LLMs)
The two baselines are a mixed bag: some models and some layers are okay but many others not
LatentLens shows high interpretability across the board
The two baselines are a mixed bag: some models and some layers are okay but many others not
LatentLens shows high interpretability across the board
This might sound abstract, so here are some examples
We can see:
a) LatentLens makes visual tokens interpretable at all layers
b) it has no issues with single-token results like logit lens and provides detailed full sentences!
(no training or tuning involved)
We can see:
a) LatentLens makes visual tokens interpretable at all layers
b) it has no issues with single-token results like logit lens and provides detailed full sentences!
(no training or tuning involved)

February 11, 2026 at 2:12 PM
This might sound abstract, so here are some examples
We can see:
a) LatentLens makes visual tokens interpretable at all layers
b) it has no issues with single-token results like logit lens and provides detailed full sentences!
(no training or tuning involved)
We can see:
a) LatentLens makes visual tokens interpretable at all layers
b) it has no issues with single-token results like logit lens and provides detailed full sentences!
(no training or tuning involved)
LatentLens in a nutshell:
Instead of an LLM's fixed vocabulary (eg embedding matrix), we propose contextual representations as our pool of nearest neighbors
→ e.g. the representation of “dog” in “my brown dog” at some layer N
Instead of an LLM's fixed vocabulary (eg embedding matrix), we propose contextual representations as our pool of nearest neighbors
→ e.g. the representation of “dog” in “my brown dog” at some layer N

February 11, 2026 at 2:12 PM
LatentLens in a nutshell:
Instead of an LLM's fixed vocabulary (eg embedding matrix), we propose contextual representations as our pool of nearest neighbors
→ e.g. the representation of “dog” in “my brown dog” at some layer N
Instead of an LLM's fixed vocabulary (eg embedding matrix), we propose contextual representations as our pool of nearest neighbors
→ e.g. the representation of “dog” in “my brown dog” at some layer N
🚨New paper
Are visual tokens going into an LLM interpretable 🤔
Existing methods (e.g. logit lens) and assumptions would lead you to think “not much”...
We propose LatentLens and show that most visual tokens are interpretable across *all* layers 💡
Details 🧵
Are visual tokens going into an LLM interpretable 🤔
Existing methods (e.g. logit lens) and assumptions would lead you to think “not much”...
We propose LatentLens and show that most visual tokens are interpretable across *all* layers 💡
Details 🧵

February 11, 2026 at 2:12 PM
🚨New paper
Are visual tokens going into an LLM interpretable 🤔
Existing methods (e.g. logit lens) and assumptions would lead you to think “not much”...
We propose LatentLens and show that most visual tokens are interpretable across *all* layers 💡
Details 🧵
Are visual tokens going into an LLM interpretable 🤔
Existing methods (e.g. logit lens) and assumptions would lead you to think “not much”...
We propose LatentLens and show that most visual tokens are interpretable across *all* layers 💡
Details 🧵
According to Gemini 2021 was the least crazy year

February 8, 2026 at 3:48 PM
According to Gemini 2021 was the least crazy year
Wild output from Gemini i got two weeks ago
i wonder if the appearance on tv is meant to represent the sin of pride
i wonder if the appearance on tv is meant to represent the sin of pride

January 12, 2026 at 7:55 PM
Wild output from Gemini i got two weeks ago
i wonder if the appearance on tv is meant to represent the sin of pride
i wonder if the appearance on tv is meant to represent the sin of pride
Devoured this book in 18 hours, usually not a big fan of audio books!
It covered lots from crowdworker rights, the ideologies (doomers, EA, ...) and the silicon valley startup world to the many big egos and company-internal battles
Great work by @karenhao.bsky.social
It covered lots from crowdworker rights, the ideologies (doomers, EA, ...) and the silicon valley startup world to the many big egos and company-internal battles
Great work by @karenhao.bsky.social

September 22, 2025 at 2:34 AM
Devoured this book in 18 hours, usually not a big fan of audio books!
It covered lots from crowdworker rights, the ideologies (doomers, EA, ...) and the silicon valley startup world to the many big egos and company-internal battles
Great work by @karenhao.bsky.social
It covered lots from crowdworker rights, the ideologies (doomers, EA, ...) and the silicon valley startup world to the many big egos and company-internal battles
Great work by @karenhao.bsky.social
very happy to see the trend of a Behind the Scenes section catching on! transparent & honest science 👌
love the detailed montreal spots mentioned
consider including such a section in your next appendix!
(paper by @a-krishnan.bsky.social arxiv.org/pdf/2504.050...)
love the detailed montreal spots mentioned
consider including such a section in your next appendix!
(paper by @a-krishnan.bsky.social arxiv.org/pdf/2504.050...)

August 13, 2025 at 12:19 PM
very happy to see the trend of a Behind the Scenes section catching on! transparent & honest science 👌
love the detailed montreal spots mentioned
consider including such a section in your next appendix!
(paper by @a-krishnan.bsky.social arxiv.org/pdf/2504.050...)
love the detailed montreal spots mentioned
consider including such a section in your next appendix!
(paper by @a-krishnan.bsky.social arxiv.org/pdf/2504.050...)
Turns out condensing your research into 3min is very hard but also teaches you a lot
Finally the video from Mila's speed science competition is on YouTube!
From a soup of raw pixels to abstract meaning
t.co/RDpu1kR7jM
Finally the video from Mila's speed science competition is on YouTube!
From a soup of raw pixels to abstract meaning
t.co/RDpu1kR7jM
June 20, 2025 at 3:54 PM
Turns out condensing your research into 3min is very hard but also teaches you a lot
Finally the video from Mila's speed science competition is on YouTube!
From a soup of raw pixels to abstract meaning
t.co/RDpu1kR7jM
Finally the video from Mila's speed science competition is on YouTube!
From a soup of raw pixels to abstract meaning
t.co/RDpu1kR7jM
Some reflections at the end:
There's a lot of talk about math reasoning these days, but this project made me appreciate what simple reasoning we humans take for granted, arising in our first months and years of living
As usual i also included "Behind The Scenes" in the Appendix:
There's a lot of talk about math reasoning these days, but this project made me appreciate what simple reasoning we humans take for granted, arising in our first months and years of living
As usual i also included "Behind The Scenes" in the Appendix:

June 13, 2025 at 2:47 PM
Some reflections at the end:
There's a lot of talk about math reasoning these days, but this project made me appreciate what simple reasoning we humans take for granted, arising in our first months and years of living
As usual i also included "Behind The Scenes" in the Appendix:
There's a lot of talk about math reasoning these days, but this project made me appreciate what simple reasoning we humans take for granted, arising in our first months and years of living
As usual i also included "Behind The Scenes" in the Appendix:
I am super grateful to my smart+kind collaborators at Meta who made this a very enjoyable project :)
(Mido Assran Nicolas Ballas @koustuvsinha.com @candaceross.bsky.social @quentin-garrido.bsky.social Mojtaba Komeili)
The Montreal office in general is a very fun place 👇
(Mido Assran Nicolas Ballas @koustuvsinha.com @candaceross.bsky.social @quentin-garrido.bsky.social Mojtaba Komeili)
The Montreal office in general is a very fun place 👇

June 13, 2025 at 2:47 PM
I am super grateful to my smart+kind collaborators at Meta who made this a very enjoyable project :)
(Mido Assran Nicolas Ballas @koustuvsinha.com @candaceross.bsky.social @quentin-garrido.bsky.social Mojtaba Komeili)
The Montreal office in general is a very fun place 👇
(Mido Assran Nicolas Ballas @koustuvsinha.com @candaceross.bsky.social @quentin-garrido.bsky.social Mojtaba Komeili)
The Montreal office in general is a very fun place 👇
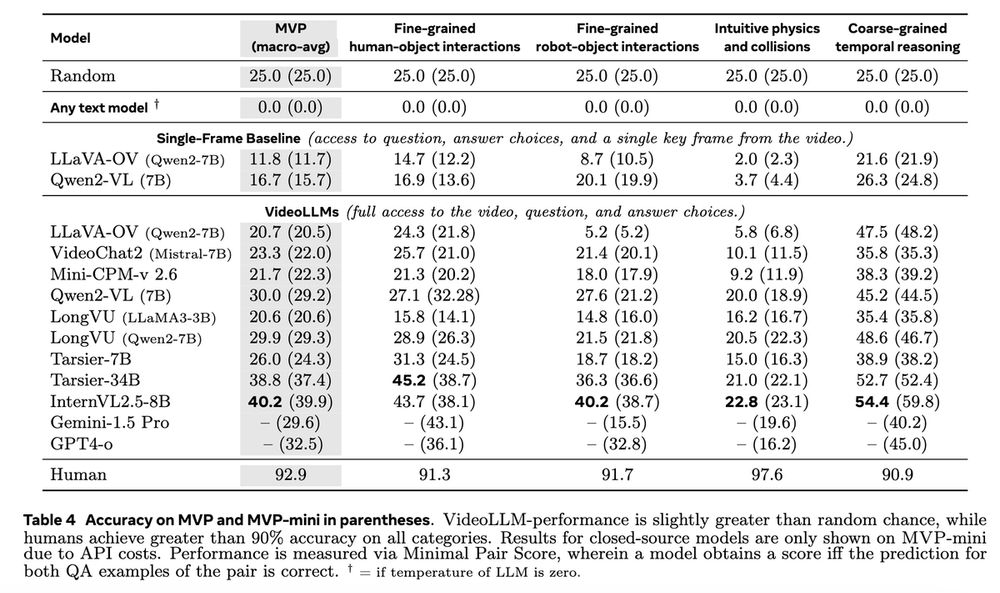
The hardest tasks for current models are still intuitive physics tasks where performance is often below random (In line with the prev. literature)
We encourage the community to use MVPBench to check if the latest VideoLLMs possess a *real* understanding of the physical world!
We encourage the community to use MVPBench to check if the latest VideoLLMs possess a *real* understanding of the physical world!
June 13, 2025 at 2:47 PM
The hardest tasks for current models are still intuitive physics tasks where performance is often below random (In line with the prev. literature)
We encourage the community to use MVPBench to check if the latest VideoLLMs possess a *real* understanding of the physical world!
We encourage the community to use MVPBench to check if the latest VideoLLMs possess a *real* understanding of the physical world!
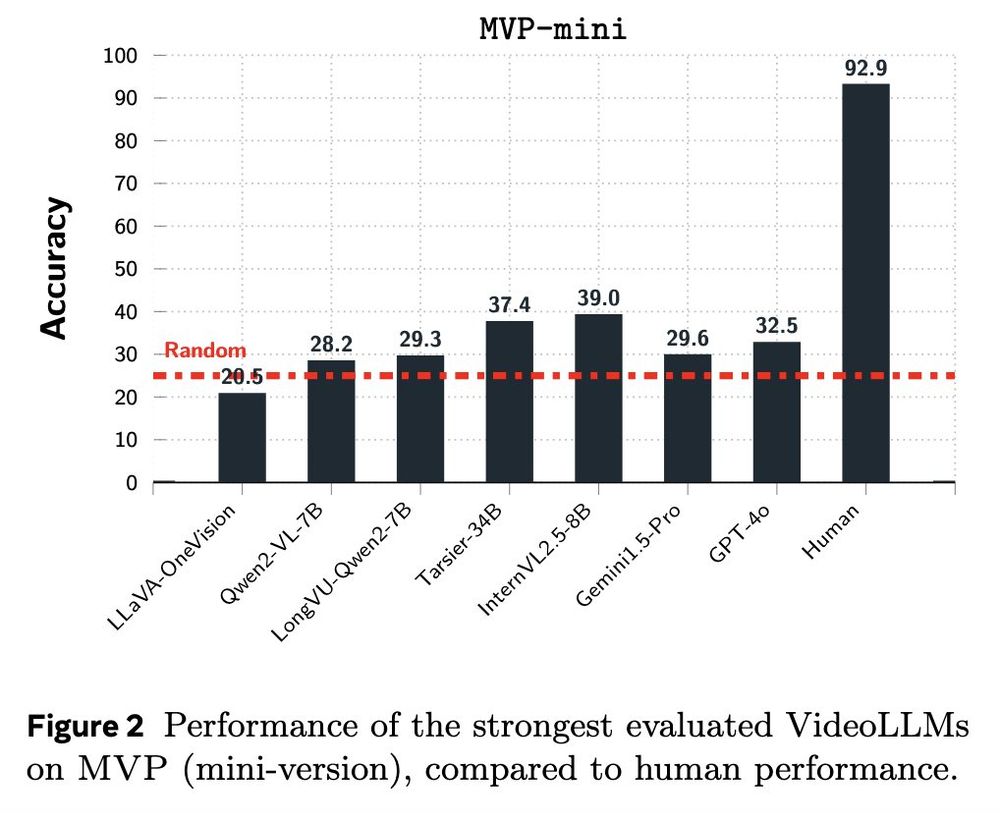
On the other hand even the strongest sota models perform around random chance, with only 2-3 models significantly above random
June 13, 2025 at 2:47 PM
On the other hand even the strongest sota models perform around random chance, with only 2-3 models significantly above random
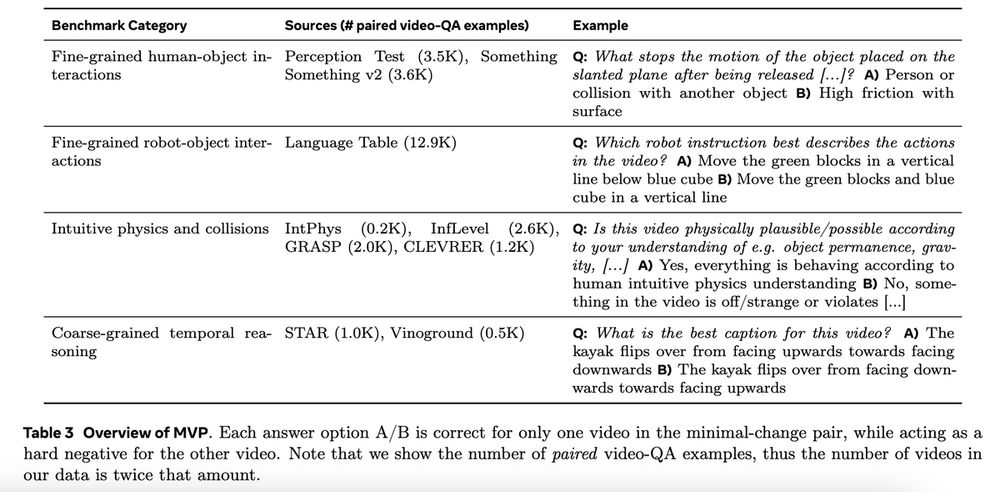
The questions in MVPBench are conceptually simple: relatively short videos with little linguistic or cultural knowledge needed. As a result humans have no problem with these questions, e.g. it is known that even babies do well on various intuitive physics tasks
June 13, 2025 at 2:47 PM
The questions in MVPBench are conceptually simple: relatively short videos with little linguistic or cultural knowledge needed. As a result humans have no problem with these questions, e.g. it is known that even babies do well on various intuitive physics tasks
By automating the pairing of highly similar video pairs pairs and unifying different datasets, as well filtering out examples that models can solve with a single-frame, we end up with (probably) the largest and most diverse dataset of its kind:
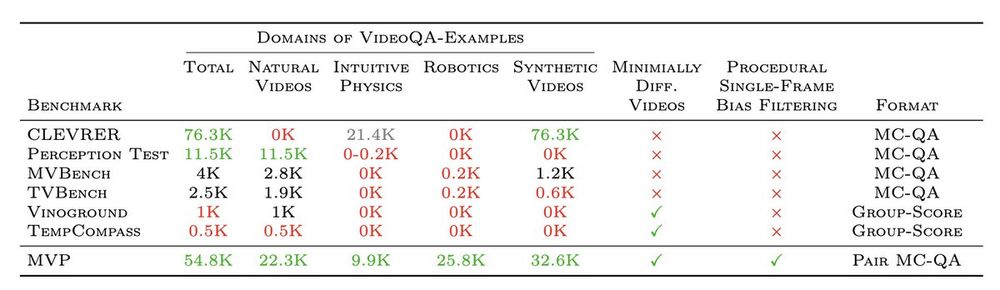
June 13, 2025 at 2:47 PM
By automating the pairing of highly similar video pairs pairs and unifying different datasets, as well filtering out examples that models can solve with a single-frame, we end up with (probably) the largest and most diverse dataset of its kind: