



John Campbell
@campbell.fi
Data enthusiast, Father, consultant
Reposted by John Campbell

Looking for a practical way to manage rules-based systems? Dmitry Lesnik and Tobias Schäfer walks you through building an engine using "t-objects" and provides an open-source Python library to get started.

Building a Rules Engine from First Principles | Towards Data Science
How recasting propositional logic as sparse algebra leads to an elegant and efficient design
towardsdatascience.com
November 12, 2025 at 5:23 PM
Looking for a practical way to manage rules-based systems? Dmitry Lesnik and Tobias Schäfer walks you through building an engine using "t-objects" and provides an open-source Python library to get started.
Reposted by John Campbell

Big graph, little compute?
In our #NeurIPS2025 paper we propose geometry-aware edge-contraction-based pooling methods for GNNs.
Our methods preserve graph structure, make interpretable pooling choices, and ensure robust performance at downstream tasks.
🧵1/n
In our #NeurIPS2025 paper we propose geometry-aware edge-contraction-based pooling methods for GNNs.
Our methods preserve graph structure, make interpretable pooling choices, and ensure robust performance at downstream tasks.
🧵1/n

November 11, 2025 at 3:48 PM
Big graph, little compute?
In our #NeurIPS2025 paper we propose geometry-aware edge-contraction-based pooling methods for GNNs.
Our methods preserve graph structure, make interpretable pooling choices, and ensure robust performance at downstream tasks.
🧵1/n
In our #NeurIPS2025 paper we propose geometry-aware edge-contraction-based pooling methods for GNNs.
Our methods preserve graph structure, make interpretable pooling choices, and ensure robust performance at downstream tasks.
🧵1/n
Andrew has some great points here on how to get data out of source systems. His point about data engineers lacking the context for collecting source-aligned data shines through in practice. Very insightful

This week I write about source-aligned data products: do they solve our problems or do we need an output port on the source system.
Also articles on scaling data platform teams, the automation paradox in data governance, and a minimal data contract.
a-j.io/n251017 #DataBS
Also articles on scaling data platform teams, the automation paradox in data governance, and a minimal data contract.
a-j.io/n251017 #DataBS

Source-aligned data products, or output ports on the source?
Do source-aligned data products solve the problem, or do we instead need a more suitable output port on the source system.
a-j.io
October 17, 2025 at 10:48 AM
Andrew has some great points here on how to get data out of source systems. His point about data engineers lacking the context for collecting source-aligned data shines through in practice. Very insightful
Reposted by John Campbell


Reposted by John Campbell

For myself to more easily find again later. (GitHub Markdown "alerts")
docs.github.com/en/get-start...
docs.github.com/en/get-start...

October 14, 2025 at 1:32 PM
For myself to more easily find again later. (GitHub Markdown "alerts")
docs.github.com/en/get-start...
docs.github.com/en/get-start...
Reposted by John Campbell

Synthetic aperture radar autofocus and calibration | Discussion

Synthetic aperture radar autofocus and calibration
3D trajectory position error estimation autofocus, antenna pattern normalization, and polarimetric calibration for drone mounted SAR radar.
hforsten.com
October 11, 2025 at 3:40 AM
Synthetic aperture radar autofocus and calibration | Discussion
Reposted by John Campbell

I figured out a uv recipe for running tests for any project with pyproject.toml or setuppy using any Python version:
uv run --python 3.14 --isolated --with-editable '.[test]' pytest
I've wrapped it in a uv-test script:
uv-test -p 3.11
Full details here: til.simonwillison.net/python/uv-te...
uv run --python 3.14 --isolated --with-editable '.[test]' pytest
I've wrapped it in a uv-test script:
uv-test -p 3.11
Full details here: til.simonwillison.net/python/uv-te...
setup.py
October 9, 2025 at 3:40 AM
I figured out a uv recipe for running tests for any project with pyproject.toml or setuppy using any Python version:
uv run --python 3.14 --isolated --with-editable '.[test]' pytest
I've wrapped it in a uv-test script:
uv-test -p 3.11
Full details here: til.simonwillison.net/python/uv-te...
uv run --python 3.14 --isolated --with-editable '.[test]' pytest
I've wrapped it in a uv-test script:
uv-test -p 3.11
Full details here: til.simonwillison.net/python/uv-te...
Reposted by John Campbell

Death to Data Pipelines: The Banana Peel Problem 🍌
Data at the Centre vs. Pipeline-First Data Management, What Constitutes Resiliency in Data Systems Today, and Defensive Designs that are Built to Mistrust
open.substack.com/pub/modernda...
Data at the Centre vs. Pipeline-First Data Management, What Constitutes Resiliency in Data Systems Today, and Defensive Designs that are Built to Mistrust
open.substack.com/pub/modernda...

Death to Data Pipelines: The Banana Peel Problem 🍌
Data at the Centre vs. Pipeline-First Data Management, What Constitutes Resiliency in Data Systems Today, and Defensive Designs that are Built to Mistrust.
open.substack.com
October 7, 2025 at 3:15 AM
Death to Data Pipelines: The Banana Peel Problem 🍌
Data at the Centre vs. Pipeline-First Data Management, What Constitutes Resiliency in Data Systems Today, and Defensive Designs that are Built to Mistrust
open.substack.com/pub/modernda...
Data at the Centre vs. Pipeline-First Data Management, What Constitutes Resiliency in Data Systems Today, and Defensive Designs that are Built to Mistrust
open.substack.com/pub/modernda...
Reposted by John Campbell

If you can stand to listen to me about model economics and synthetic environments for two hours, I have the podcast for you. www.youtube.com/watch?v=ZZKM...

October 5, 2025 at 11:06 AM
If you can stand to listen to me about model economics and synthetic environments for two hours, I have the podcast for you. www.youtube.com/watch?v=ZZKM...
Reposted by John Campbell
A $196 fine-tuned 7B model outperforms OpenAI o3 on document extraction | Discussion
Extract-0: A Specialized Language Model for Document Information Extraction
This paper presents Extract-0, a 7-billion parameter language model specifically optimized for document information extraction that achieves performance exceeding models with parameter counts several orders of magnitude larger. Through a novel combination of synthetic data generation, supervised fine-tuning with Low-Rank Adaptation (LoRA), and reinforcement learning via Group Relative Policy Optimization (GRPO), Extract-0 achieves a mean reward of 0.573 on a benchmark of 1,000 diverse document extraction tasks, outperforming GPT-4.1 (0.457), o3 (0.464), and GPT-4.1-2025 (0.459). The training methodology employs a memory-preserving synthetic data generation pipeline that produces 280,128 training examples from diverse document sources, followed by parameterefficient fine-tuning that modifies only 0.53% of model weights (40.4M out of 7.66B parameters). The reinforcement learning phase introduces a novel semantic similarity-based reward function that handles the inherent ambiguity in information extraction tasks. This research demonstrates that task-specific optimization can yield models that surpass general-purpose systems while requiring substantially fewer computational resource.
arxiv.org
September 30, 2025 at 5:40 PM
A $196 fine-tuned 7B model outperforms OpenAI o3 on document extraction | Discussion
Reposted by John Campbell

the owners of TikTok scandalously release:
REER: a learning method that exposes the logic that led to a good result
Booty: when shaken properly elicits creative writing
ASS: (they couldn’t get an acronym to work, but i’m sure they tried)
huggingface.co/papers/2509....
REER: a learning method that exposes the logic that led to a good result
Booty: when shaken properly elicits creative writing
ASS: (they couldn’t get an acronym to work, but i’m sure they tried)
huggingface.co/papers/2509....

Paper page - Reverse-Engineered Reasoning for Open-Ended Generation
Join the discussion on this paper page
huggingface.co
September 9, 2025 at 3:47 PM
the owners of TikTok scandalously release:
REER: a learning method that exposes the logic that led to a good result
Booty: when shaken properly elicits creative writing
ASS: (they couldn’t get an acronym to work, but i’m sure they tried)
huggingface.co/papers/2509....
REER: a learning method that exposes the logic that led to a good result
Booty: when shaken properly elicits creative writing
ASS: (they couldn’t get an acronym to work, but i’m sure they tried)
huggingface.co/papers/2509....
Reposted by John Campbell

I got introduced to @randyau.com's 'Data Cleaning IS Analysis, Not Grunt Work' post during the #dataBS Conf this week: www.counting-stuff.com/data-cleanin... . I just finished--it was a great read.
Here are some quotes and thoughts I'm walking away with 👇
1/9 #RStats
Here are some quotes and thoughts I'm walking away with 👇
1/9 #RStats

Data Cleaning IS Analysis, Not Grunt Work
Also, most data cleaning articles suck
www.counting-stuff.com
September 28, 2025 at 4:59 AM
I got introduced to @randyau.com's 'Data Cleaning IS Analysis, Not Grunt Work' post during the #dataBS Conf this week: www.counting-stuff.com/data-cleanin... . I just finished--it was a great read.
Here are some quotes and thoughts I'm walking away with 👇
1/9 #RStats
Here are some quotes and thoughts I'm walking away with 👇
1/9 #RStats
Reposted by John Campbell
Google DeepMind's paper on EmbeddingGemma, which scores really well on MTEB (huggingface.co/spaces/mteb/...) for a such a small model (300M)
"EmbeddingGemma: Powerful and Lightweight Text Representations"
"EmbeddingGemma: Powerful and Lightweight Text Representations"

September 28, 2025 at 12:45 AM
Google DeepMind's paper on EmbeddingGemma, which scores really well on MTEB (huggingface.co/spaces/mteb/...) for a such a small model (300M)
"EmbeddingGemma: Powerful and Lightweight Text Representations"
"EmbeddingGemma: Powerful and Lightweight Text Representations"
Reposted by John Campbell

Lucy Edit Dev is the first open-source instruction-guided video editing model that performs instruction-guided edits on videos using free-text prompts.
github.com/DecartAI/luc...
github.com/DecartAI/luc...

GitHub - DecartAI/Lucy-Edit-ComfyUI
Contribute to DecartAI/Lucy-Edit-ComfyUI development by creating an account on GitHub.
github.com
September 25, 2025 at 3:23 PM
Lucy Edit Dev is the first open-source instruction-guided video editing model that performs instruction-guided edits on videos using free-text prompts.
github.com/DecartAI/luc...
github.com/DecartAI/luc...
Reposted by John Campbell
Alibaba released Qwen3-Omni, a natively end-to-end multilingual omni-modal (text, images, audio, video) foundation model, responding as real-time stream in both text and natural speech, available under open-source license.
github.com/QwenLM/Qwen3...
github.com/QwenLM/Qwen3...

GitHub - QwenLM/Qwen3-Omni: Qwen3-omni is a natively end-to-end, omni-modal LLM developed by the Qwen team at Alibaba Cloud, capable of understanding text, audio, images, and video, as well as generat...
Qwen3-omni is a natively end-to-end, omni-modal LLM developed by the Qwen team at Alibaba Cloud, capable of understanding text, audio, images, and video, as well as generating speech in real time. ...
github.com
September 23, 2025 at 11:25 AM
Alibaba released Qwen3-Omni, a natively end-to-end multilingual omni-modal (text, images, audio, video) foundation model, responding as real-time stream in both text and natural speech, available under open-source license.
github.com/QwenLM/Qwen3...
github.com/QwenLM/Qwen3...
Reposted by John Campbell

Now this looks fun to play with!

Speaking of the GhostTown project, I wrote a ranking algorithm, and tied it into a self training GNN for ranking and signal heuristics! Ever wanted to make your own social media website, but realized that like 100% of open source social media ranking algos suck? No more! github.com/LynnColeArt/...

GitHub - LynnColeArt/socialgnn: Hybrid Graph Neural Network (60% learned, 40% heuristic) for production social media ranking with authority multipliers, spam detection, and real-time training.
Hybrid Graph Neural Network (60% learned, 40% heuristic) for production social media ranking with authority multipliers, spam detection, and real-time training. - LynnColeArt/socialgnn
github.com
September 24, 2025 at 7:54 AM
Now this looks fun to play with!
Reposted by John Campbell

First Look at #onelake #apacheiceberg REST Catalog, please notice it is coming soon and not in production yet #MicrosoftFabric
www.youtube.com/watch?v=_QRE...
www.youtube.com/watch?v=_QRE...

First Look at Onelake Iceberg REST Catalog
YouTube video by DataMonkey
www.youtube.com
September 20, 2025 at 6:23 AM
First Look at #onelake #apacheiceberg REST Catalog, please notice it is coming soon and not in production yet #MicrosoftFabric
www.youtube.com/watch?v=_QRE...
www.youtube.com/watch?v=_QRE...
Reposted by John Campbell
the top 2 ARC entries are by individuals
here, Eric Pang breaks down how he added memory to avoid recomputing learned lessons
ctpang.substack.com/p/arc-agi-2-...
here, Eric Pang breaks down how he added memory to avoid recomputing learned lessons
ctpang.substack.com/p/arc-agi-2-...
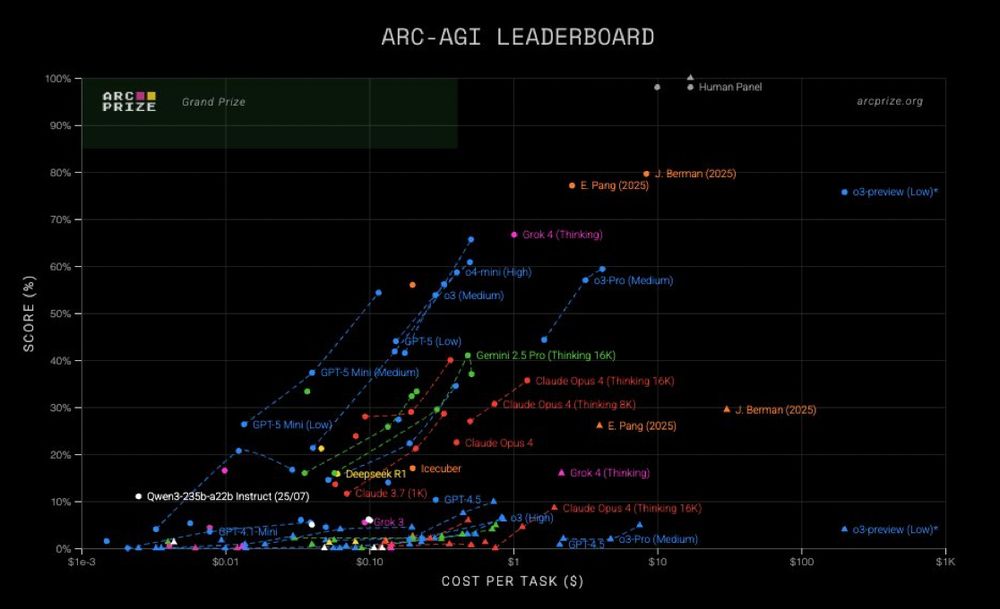
September 17, 2025 at 11:05 AM
the top 2 ARC entries are by individuals
here, Eric Pang breaks down how he added memory to avoid recomputing learned lessons
ctpang.substack.com/p/arc-agi-2-...
here, Eric Pang breaks down how he added memory to avoid recomputing learned lessons
ctpang.substack.com/p/arc-agi-2-...
Reposted by John Campbell

i did not foresee the future in which Markdown was the machine interop format for all human readable documents
blog.xeynergy.com/what-is-micr...
blog.xeynergy.com/what-is-micr...

What is Microsoft MarkItDown and Why It Matters?
You’re trying to build something useful with AI, and then you hit the wall of “how the heck do I get all these random documents into my…
blog.xeynergy.com
September 15, 2025 at 11:53 PM
i did not foresee the future in which Markdown was the machine interop format for all human readable documents
blog.xeynergy.com/what-is-micr...
blog.xeynergy.com/what-is-micr...
Reposted by John Campbell

Does a smaller latent space lead to worse generation in latent diffusion models? Not necessarily! We show that LDMs are extremely robust to a wide range of compression rates (10-1000x) in the context of physics emulation.
We got lost in latent space. Join us 👇
We got lost in latent space. Join us 👇

September 3, 2025 at 1:40 PM
Does a smaller latent space lead to worse generation in latent diffusion models? Not necessarily! We show that LDMs are extremely robust to a wide range of compression rates (10-1000x) in the context of physics emulation.
We got lost in latent space. Join us 👇
We got lost in latent space. Join us 👇
Reposted by John Campbell

i wanted to understand the current landscape better, so i did a deep dive on current embedding sizes and architectures vickiboykis.com/2025/09/01/h...
September 1, 2025 at 4:15 PM
i wanted to understand the current landscape better, so i did a deep dive on current embedding sizes and architectures vickiboykis.com/2025/09/01/h...
Reposted by John Campbell

simple little uv-runnable python script to generate interactive diffs for arxiv papers based on the underlying latex source.
github.com/apoorvalal/a...
github.com/apoorvalal/a...

GitHub - apoorvalal/arxivdiff: a python cli tool to diff arxiv papers
a python cli tool to diff arxiv papers. Contribute to apoorvalal/arxivdiff development by creating an account on GitHub.
github.com
September 1, 2025 at 3:31 PM
simple little uv-runnable python script to generate interactive diffs for arxiv papers based on the underlying latex source.
github.com/apoorvalal/a...
github.com/apoorvalal/a...
Its about time for some random pictures of public transportation. How about some double-decker trams in HK

August 21, 2025 at 6:25 PM
Its about time for some random pictures of public transportation. How about some double-decker trams in HK
@mollyjongfast.bsky.social Re: your latest pod, Trump's bond purchase explains his insistence on lowering interest rates. Bond values have an inverse relationship to interest rates, so it is just another instance of corrupt self-dealing
August 21, 2025 at 5:46 AM
@mollyjongfast.bsky.social Re: your latest pod, Trump's bond purchase explains his insistence on lowering interest rates. Bond values have an inverse relationship to interest rates, so it is just another instance of corrupt self-dealing
Reposted by John Campbell
Show HN: Whispering – Open-source, local-first dictation you can trust | Discussion

epicenter/apps/whispering at main · epicenter-so/epicenter
Press shortcut → speak → get text. Free and open source. More local-first apps soon ❤️ - epicenter-so/epicenter
github.com
August 18, 2025 at 7:00 PM
Show HN: Whispering – Open-source, local-first dictation you can trust | Discussion