



Dayeon (Zoey) Ki
@dayeonki.bsky.social
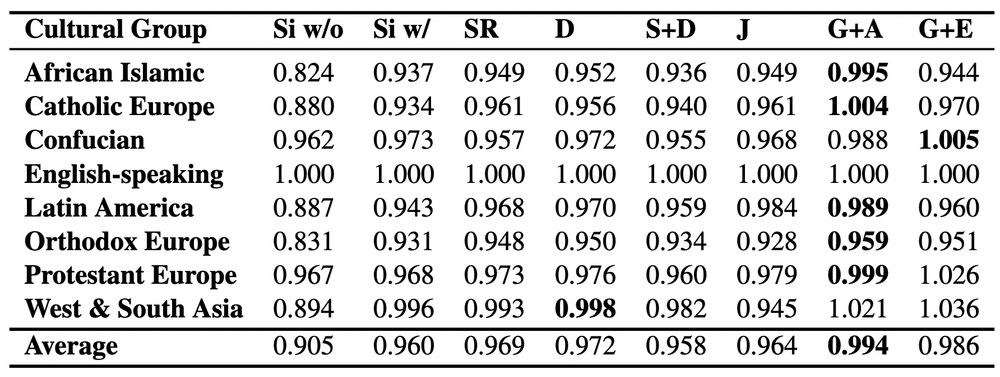
6/ But do these gains hold across cultures? 🗾
🫂 We measure cultural parity across diverse groups — and find that Multi-Agent Debate not only boosts average accuracy but also leads to more equitable cultural alignment 🌍
🫂 We measure cultural parity across diverse groups — and find that Multi-Agent Debate not only boosts average accuracy but also leads to more equitable cultural alignment 🌍
June 12, 2025 at 11:33 PM
6/ But do these gains hold across cultures? 🗾
🫂 We measure cultural parity across diverse groups — and find that Multi-Agent Debate not only boosts average accuracy but also leads to more equitable cultural alignment 🌍
🫂 We measure cultural parity across diverse groups — and find that Multi-Agent Debate not only boosts average accuracy but also leads to more equitable cultural alignment 🌍
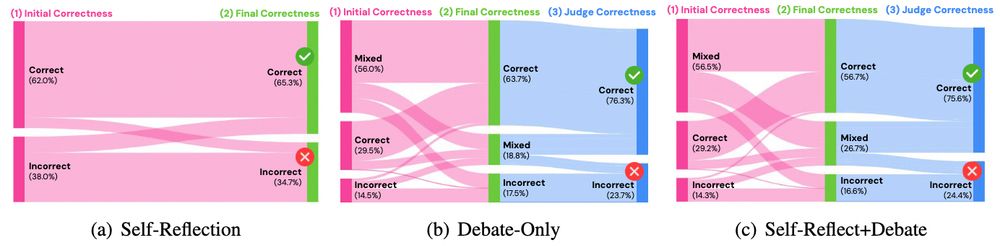
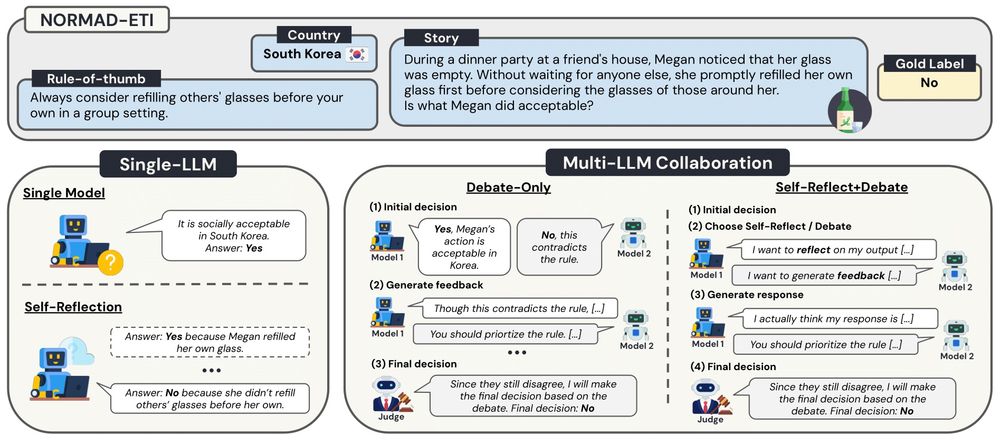
5/ How do model decisions evolve through debate?
We track three phases of LLM behavior:
💗 Initial decision correctness
💚 Final decision correctness
💙 Judge’s decision correctness
✨ Multi-Agent Debate is most valuable when models initially disagree!
We track three phases of LLM behavior:
💗 Initial decision correctness
💚 Final decision correctness
💙 Judge’s decision correctness
✨ Multi-Agent Debate is most valuable when models initially disagree!
June 12, 2025 at 11:33 PM
5/ How do model decisions evolve through debate?
We track three phases of LLM behavior:
💗 Initial decision correctness
💚 Final decision correctness
💙 Judge’s decision correctness
✨ Multi-Agent Debate is most valuable when models initially disagree!
We track three phases of LLM behavior:
💗 Initial decision correctness
💚 Final decision correctness
💙 Judge’s decision correctness
✨ Multi-Agent Debate is most valuable when models initially disagree!
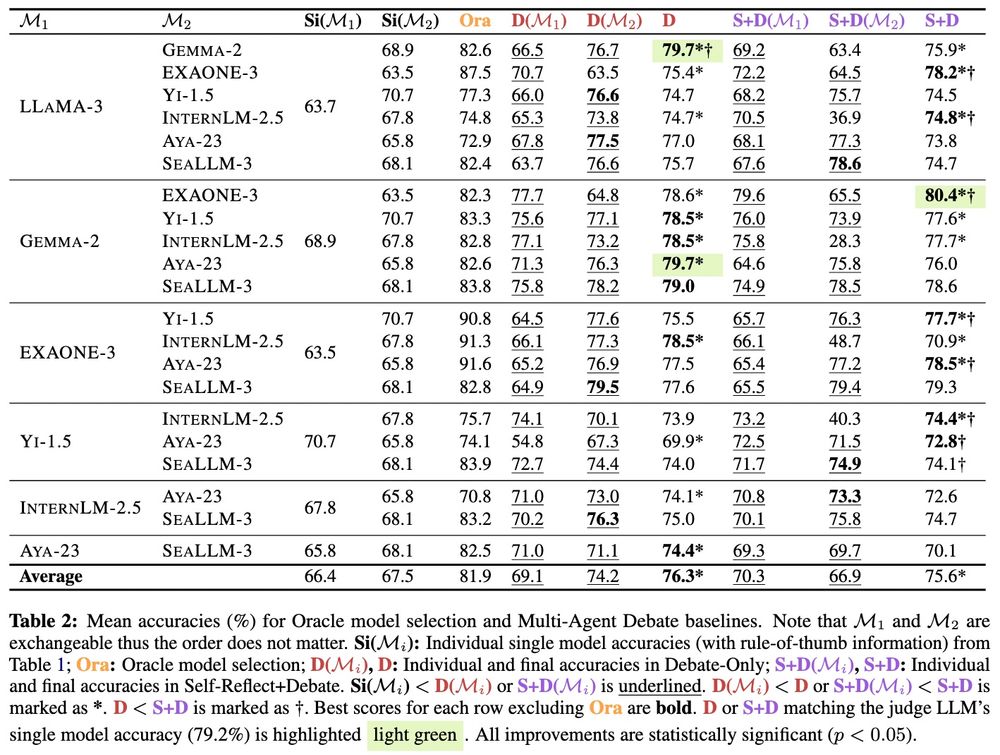
4/ 🔥 Distinct LLMs are complementary!
We find that:
🤯 Multi-Agent Debate lets smaller LLMs (7B) match the performance of much larger ones (27B)
🏆 Best combo? Gemma-2 9B + EXAONE-3 7B 💪
We find that:
🤯 Multi-Agent Debate lets smaller LLMs (7B) match the performance of much larger ones (27B)
🏆 Best combo? Gemma-2 9B + EXAONE-3 7B 💪
June 12, 2025 at 11:33 PM
4/ 🔥 Distinct LLMs are complementary!
We find that:
🤯 Multi-Agent Debate lets smaller LLMs (7B) match the performance of much larger ones (27B)
🏆 Best combo? Gemma-2 9B + EXAONE-3 7B 💪
We find that:
🤯 Multi-Agent Debate lets smaller LLMs (7B) match the performance of much larger ones (27B)
🏆 Best combo? Gemma-2 9B + EXAONE-3 7B 💪
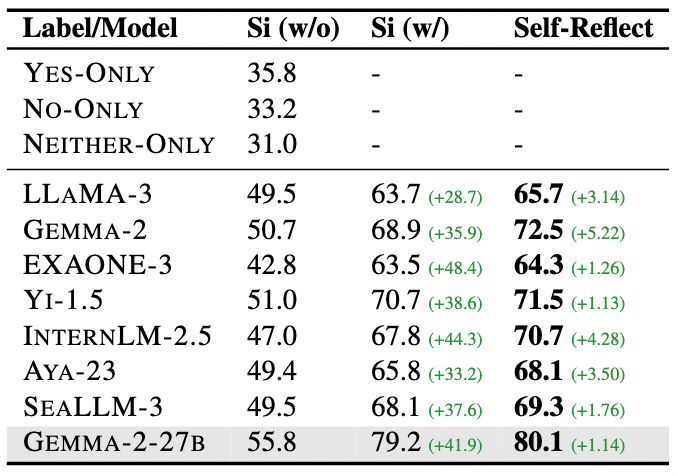
3/ Before bringing in two #LLMs, we first 📈 maximize single-LLM performance through:
1️⃣ Cultural Contextualization: adding relevant rules-of-thumb for the target culture
2️⃣ Self-Reflection: evaluating and improve its own outputs
These serve as strong baselines before we introduce collaboration 🤝
1️⃣ Cultural Contextualization: adding relevant rules-of-thumb for the target culture
2️⃣ Self-Reflection: evaluating and improve its own outputs
These serve as strong baselines before we introduce collaboration 🤝
June 12, 2025 at 11:33 PM
3/ Before bringing in two #LLMs, we first 📈 maximize single-LLM performance through:
1️⃣ Cultural Contextualization: adding relevant rules-of-thumb for the target culture
2️⃣ Self-Reflection: evaluating and improve its own outputs
These serve as strong baselines before we introduce collaboration 🤝
1️⃣ Cultural Contextualization: adding relevant rules-of-thumb for the target culture
2️⃣ Self-Reflection: evaluating and improve its own outputs
These serve as strong baselines before we introduce collaboration 🤝
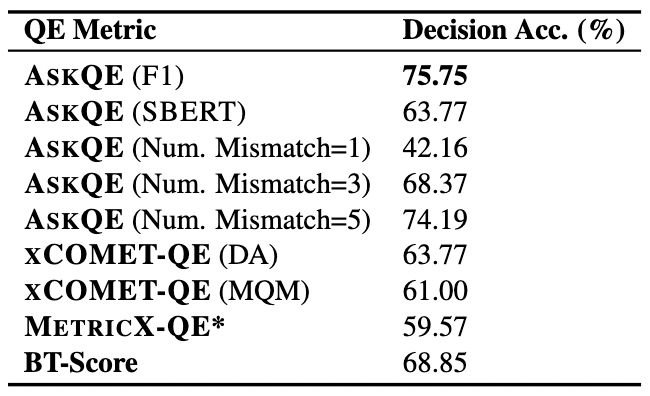
7/ Can AskQE handle naturally occurring translation errors too? 🍃
Yes! It shows:
💁♀️ Stronger correlation with human judgments
✅ Better decision-making accuracy than standard QE metrics
Yes! It shows:
💁♀️ Stronger correlation with human judgments
✅ Better decision-making accuracy than standard QE metrics
May 21, 2025 at 5:49 PM
7/ Can AskQE handle naturally occurring translation errors too? 🍃
Yes! It shows:
💁♀️ Stronger correlation with human judgments
✅ Better decision-making accuracy than standard QE metrics
Yes! It shows:
💁♀️ Stronger correlation with human judgments
✅ Better decision-making accuracy than standard QE metrics
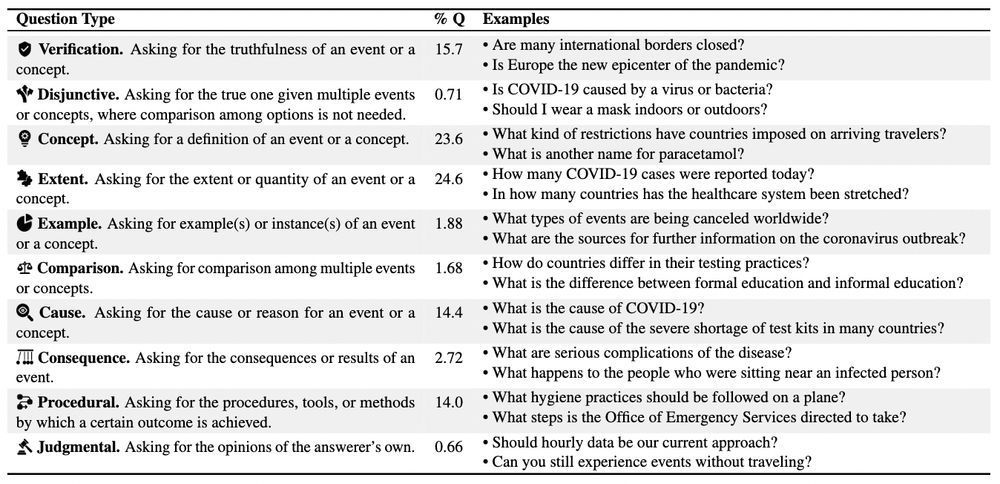
6/ 🤖 What kinds of questions does AskQE generate?
Most commonly:
📏 Extent — How many COVID-19 cases were reported today? (24.6%)
💡 Concept — What is another name for paracetamol? (23.6%)
Most commonly:
📏 Extent — How many COVID-19 cases were reported today? (24.6%)
💡 Concept — What is another name for paracetamol? (23.6%)
May 21, 2025 at 5:49 PM
6/ 🤖 What kinds of questions does AskQE generate?
Most commonly:
📏 Extent — How many COVID-19 cases were reported today? (24.6%)
💡 Concept — What is another name for paracetamol? (23.6%)
Most commonly:
📏 Extent — How many COVID-19 cases were reported today? (24.6%)
💡 Concept — What is another name for paracetamol? (23.6%)
5/ 🔥 We test AskQE on ContraTICO and find:
📉 It effectively distinguishes minor to critical translation errors
👭 It aligns closely with established quality estimation (QE) metrics
📉 It effectively distinguishes minor to critical translation errors
👭 It aligns closely with established quality estimation (QE) metrics

May 21, 2025 at 5:49 PM
5/ 🔥 We test AskQE on ContraTICO and find:
📉 It effectively distinguishes minor to critical translation errors
👭 It aligns closely with established quality estimation (QE) metrics
📉 It effectively distinguishes minor to critical translation errors
👭 It aligns closely with established quality estimation (QE) metrics
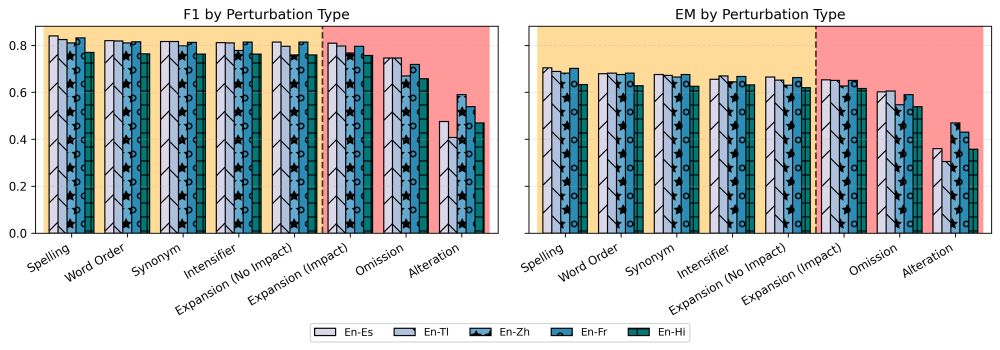
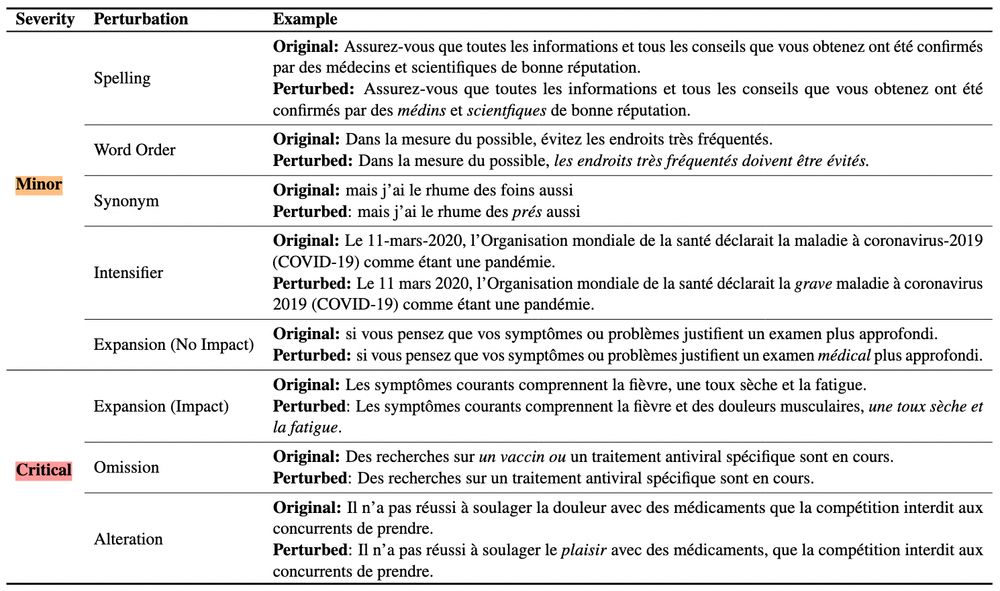
4/ We introduce ContraTICO, a dataset of 8 contrastive MT error types in the COVID-19 domain 😷🦠
⚠️ Minor errors: spelling, word order, synonym, intensifier, expansion (no impact)
📛 Critical errors: expansion (impact), omission, alteration
⚠️ Minor errors: spelling, word order, synonym, intensifier, expansion (no impact)
📛 Critical errors: expansion (impact), omission, alteration
May 21, 2025 at 5:49 PM
4/ We introduce ContraTICO, a dataset of 8 contrastive MT error types in the COVID-19 domain 😷🦠
⚠️ Minor errors: spelling, word order, synonym, intensifier, expansion (no impact)
📛 Critical errors: expansion (impact), omission, alteration
⚠️ Minor errors: spelling, word order, synonym, intensifier, expansion (no impact)
📛 Critical errors: expansion (impact), omission, alteration
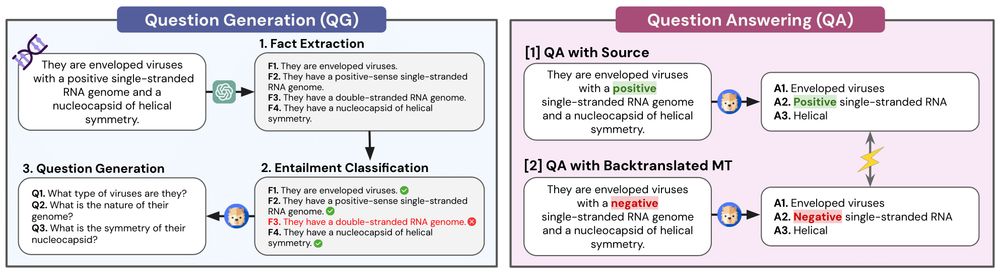
3/ AskQE has two main components:
❓ Question Generation (QG): conditioned on the source + its entailed facts
❕ Question Answering (QA): based on the source and backtranslated MT
If the answers don’t match... there's likely an error ⚠️
❓ Question Generation (QG): conditioned on the source + its entailed facts
❕ Question Answering (QA): based on the source and backtranslated MT
If the answers don’t match... there's likely an error ⚠️
May 21, 2025 at 5:49 PM
3/ AskQE has two main components:
❓ Question Generation (QG): conditioned on the source + its entailed facts
❕ Question Answering (QA): based on the source and backtranslated MT
If the answers don’t match... there's likely an error ⚠️
❓ Question Generation (QG): conditioned on the source + its entailed facts
❕ Question Answering (QA): based on the source and backtranslated MT
If the answers don’t match... there's likely an error ⚠️
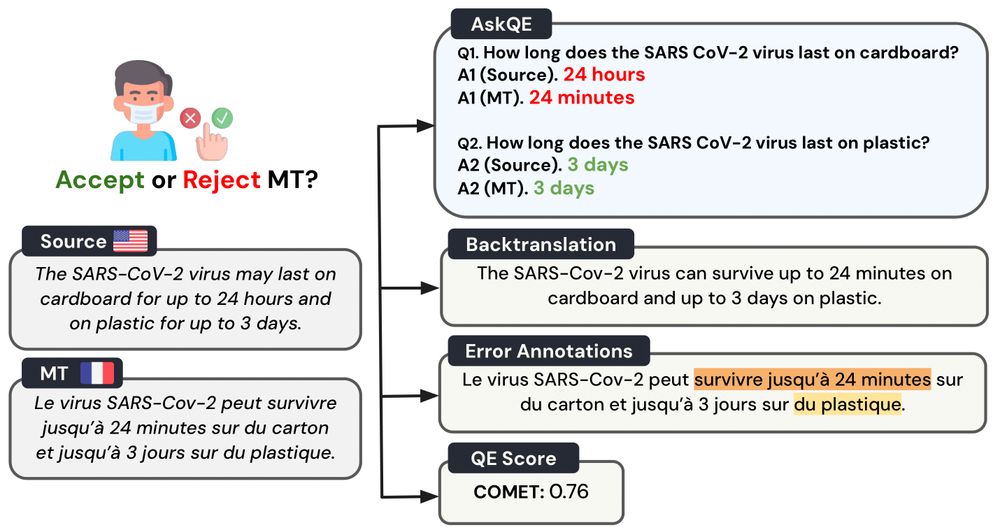
1/ How can a monolingual English speaker 🇺🇸 decide if an automatic French translation 🇫🇷 is good enough to be shared?
Introducing ❓AskQE❓, an #LLM-based Question Generation + Answering framework that detects critical MT errors and provides actionable feedback 🗣️
#ACL2025
Introducing ❓AskQE❓, an #LLM-based Question Generation + Answering framework that detects critical MT errors and provides actionable feedback 🗣️
#ACL2025
May 21, 2025 at 5:49 PM
1/ How can a monolingual English speaker 🇺🇸 decide if an automatic French translation 🇫🇷 is good enough to be shared?
Introducing ❓AskQE❓, an #LLM-based Question Generation + Answering framework that detects critical MT errors and provides actionable feedback 🗣️
#ACL2025
Introducing ❓AskQE❓, an #LLM-based Question Generation + Answering framework that detects critical MT errors and provides actionable feedback 🗣️
#ACL2025
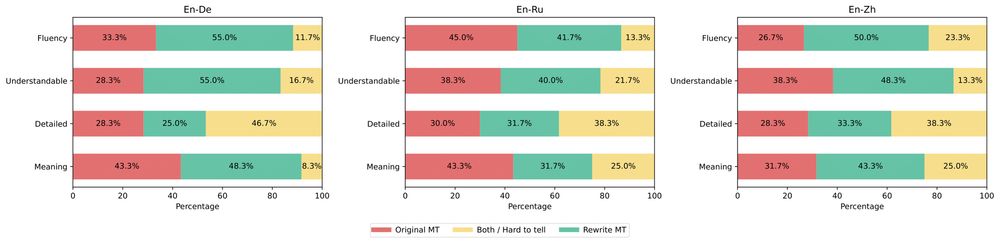
6/ 🧑⚖️ Do humans actually prefer translations of simplified inputs?
Yes! They rated these to be:
📝 More contextually appropriate
👁️ Easier to read
🤗 More comprehensible
compared to translations of original inputs!
Yes! They rated these to be:
📝 More contextually appropriate
👁️ Easier to read
🤗 More comprehensible
compared to translations of original inputs!
April 17, 2025 at 1:32 AM
6/ 🧑⚖️ Do humans actually prefer translations of simplified inputs?
Yes! They rated these to be:
📝 More contextually appropriate
👁️ Easier to read
🤗 More comprehensible
compared to translations of original inputs!
Yes! They rated these to be:
📝 More contextually appropriate
👁️ Easier to read
🤗 More comprehensible
compared to translations of original inputs!
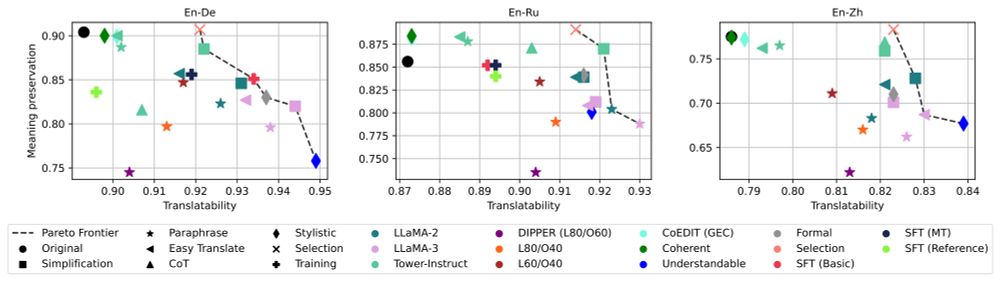
5/ What does input rewriting actually change? 🧐
Here are 3 key findings:
1️⃣ Better translatability trades-off meaning preservation
2️⃣ Simplification boosts both input & output readability 📖
3️⃣ Input rewriting > Output post-editing 🤯
Here are 3 key findings:
1️⃣ Better translatability trades-off meaning preservation
2️⃣ Simplification boosts both input & output readability 📖
3️⃣ Input rewriting > Output post-editing 🤯
April 17, 2025 at 1:32 AM
5/ What does input rewriting actually change? 🧐
Here are 3 key findings:
1️⃣ Better translatability trades-off meaning preservation
2️⃣ Simplification boosts both input & output readability 📖
3️⃣ Input rewriting > Output post-editing 🤯
Here are 3 key findings:
1️⃣ Better translatability trades-off meaning preservation
2️⃣ Simplification boosts both input & output readability 📖
3️⃣ Input rewriting > Output post-editing 🤯
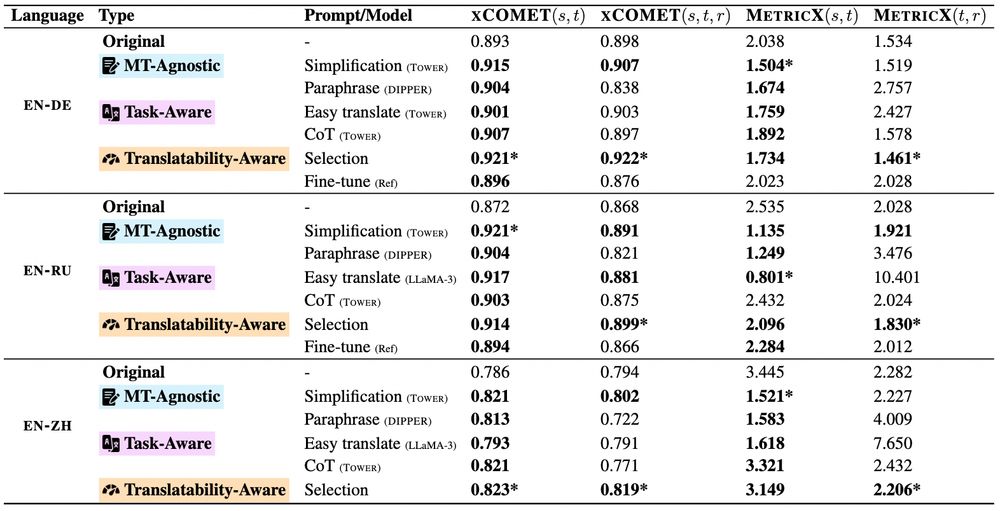
3/ 🔍 Which rewriting strategy works best?
Simpler texts are easier to translate!
But... simplification isn't always a win for MT quality 😞
Simpler texts are easier to translate!
But... simplification isn't always a win for MT quality 😞
April 17, 2025 at 1:32 AM
3/ 🔍 Which rewriting strategy works best?
Simpler texts are easier to translate!
But... simplification isn't always a win for MT quality 😞
Simpler texts are easier to translate!
But... simplification isn't always a win for MT quality 😞
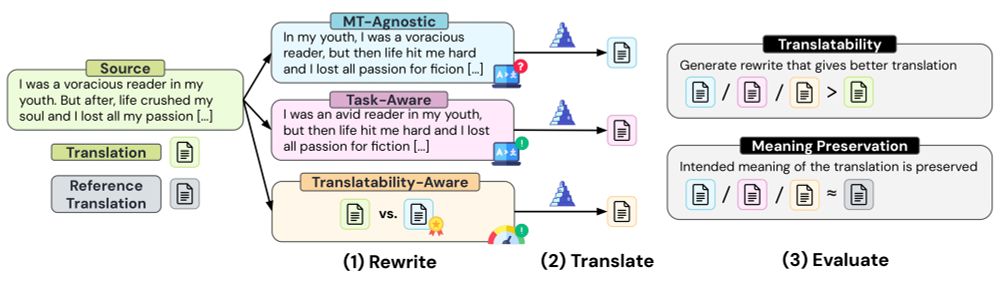
🚨 New Paper 🚨
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
April 17, 2025 at 1:32 AM
🚨 New Paper 🚨
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵