
Ekdeep Singh @ ICML
@ekdeepl.bsky.social
260 followers
380 following
48 posts
Postdoc at CBS, Harvard University
(New around here)
Posts
Media
Videos
Starter Packs



Reposted by Ekdeep Singh @ ICML

Ekdeep Singh @ ICML
@ekdeepl.bsky.social
· Jul 12

Ekdeep Singh @ ICML
@ekdeepl.bsky.social
· Jun 28
Ekdeep Singh @ ICML
@ekdeepl.bsky.social
· Jun 28

Ekdeep Singh @ ICML
@ekdeepl.bsky.social
· Apr 29
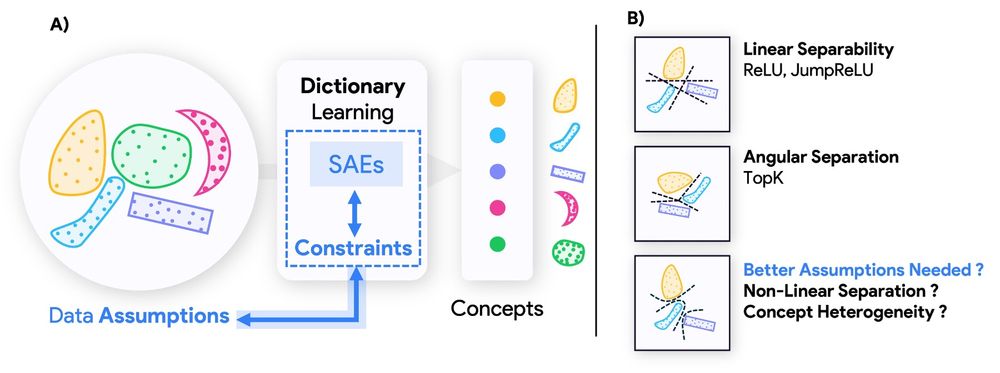
Reposted by Ekdeep Singh @ ICML

Ekdeep Singh @ ICML
@ekdeepl.bsky.social
· Feb 17
Reposted by Ekdeep Singh @ ICML

Andrew Lampinen
@lampinen.bsky.social
· Feb 16
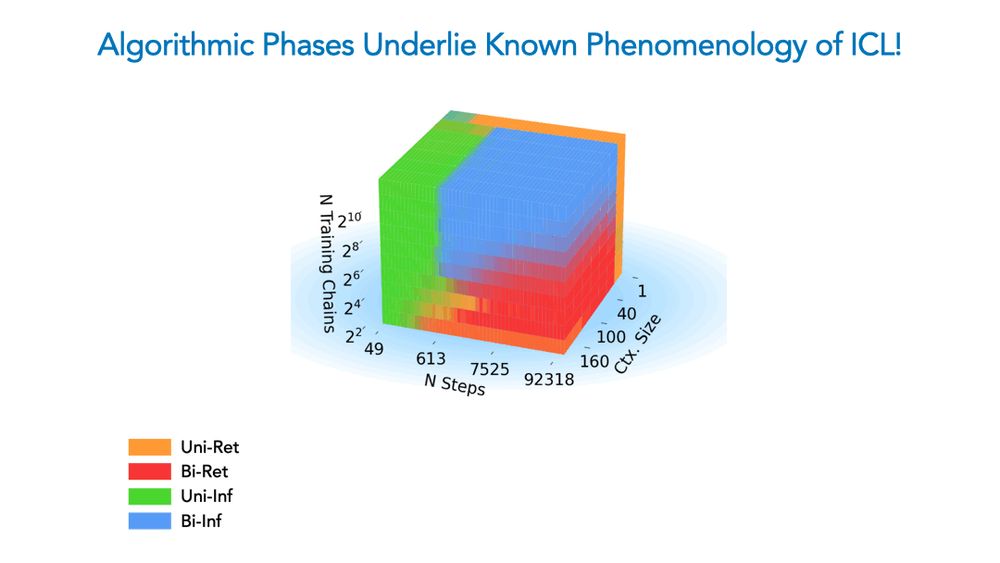
Ekdeep Singh @ ICML
@ekdeepl.bsky.social
· Feb 16

Competition Dynamics Shape Algorithmic Phases of In-Context Learning
In-Context Learning (ICL) has significantly expanded the general-purpose nature of large language models, allowing them to adapt to novel tasks using merely the inputted context. This has motivated a ...
arxiv.org
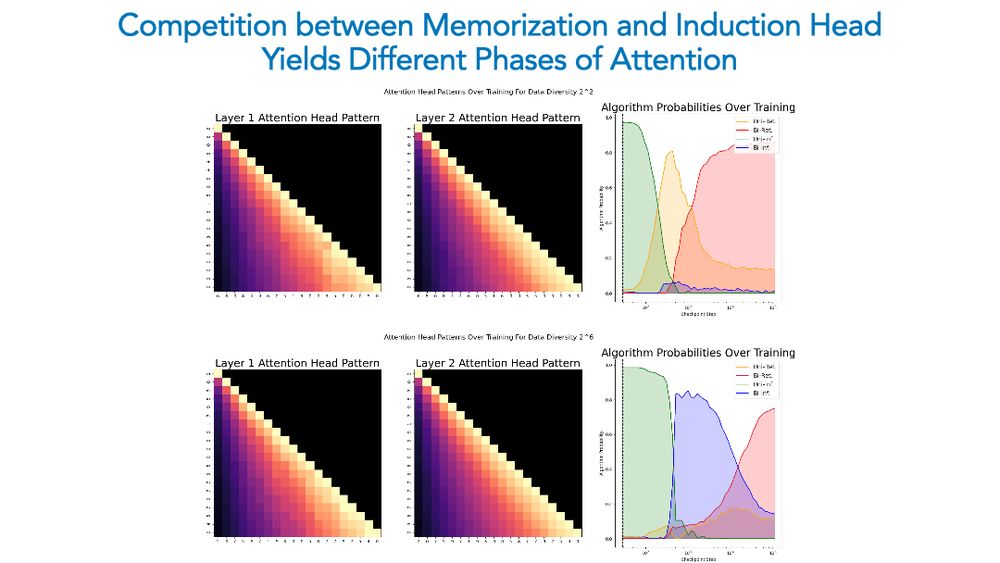
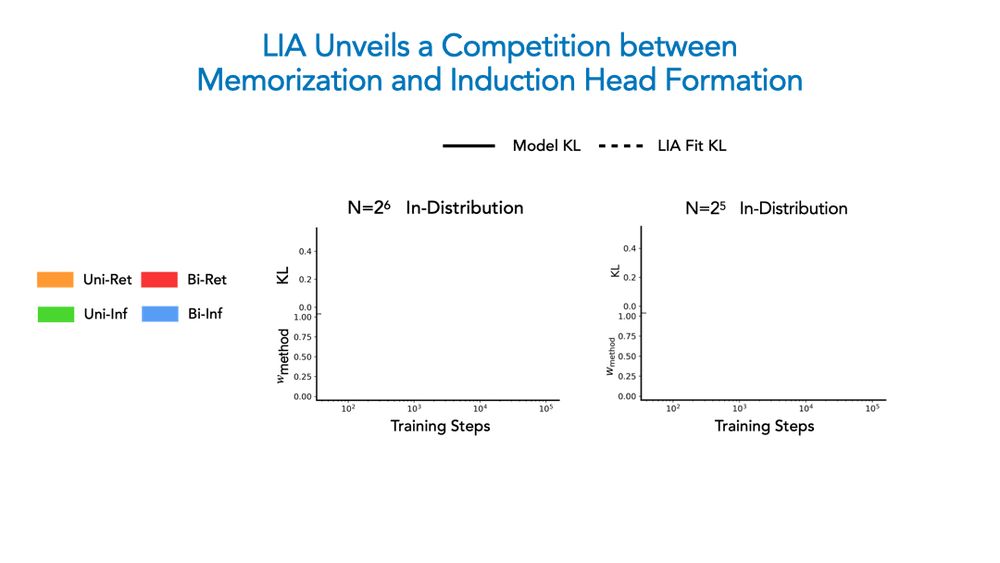






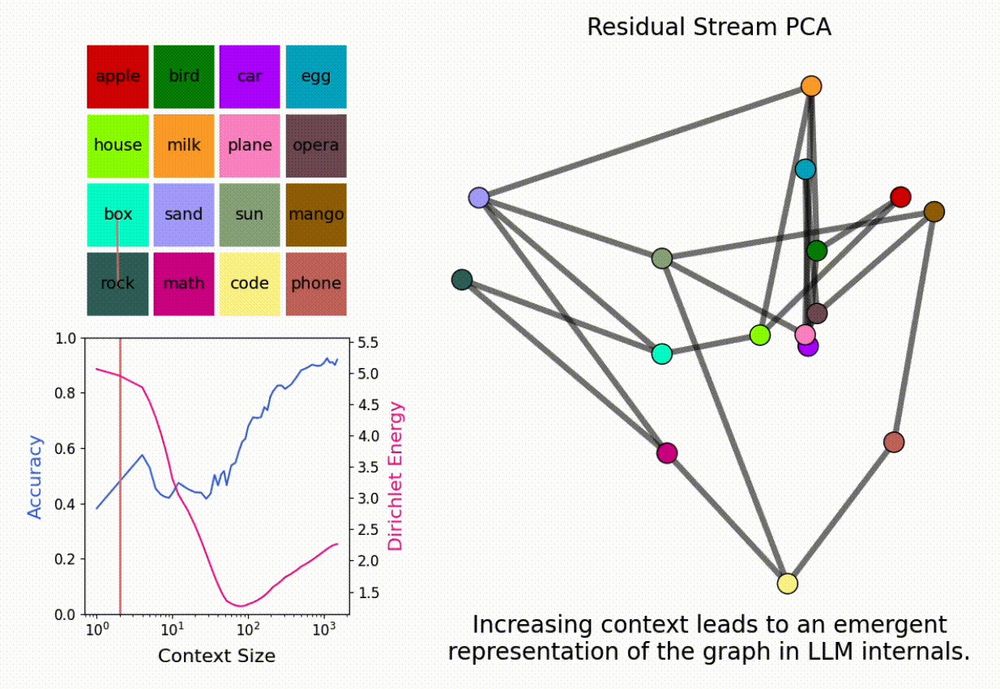
Ekdeep Singh @ ICML
@ekdeepl.bsky.social
· Feb 12

