



Eugene Yan
@eugeneyan.com
RecSys, AI, Engineering; Principal Applied Scientist @ Amazon. Led ML @ Alibaba, Lazada, Healthtech Series A. Writing @ eugeneyan.com, aiteratelabs.com.
Pinned
Eugene Yan
@eugeneyan.com
· Sep 17

How to Train an LLM-RecSys Hybrid for Steerable Recs with Semantic IDs
An LLM that can converse in English & item IDs, and make recommendations w/o retrieval or tools.
eugeneyan.com
I've been nerdsniped by the idea of Semantic IDs.
Here's the result of my training runs:
• RQ-VAE to compress item embeddings into tokens
• SASRec to predict the next item (i.e., 4-tokens) exactly
• Qwen3-8B that can return recs and natural language!
eugeneyan.com/writing/sema...
Here's the result of my training runs:
• RQ-VAE to compress item embeddings into tokens
• SASRec to predict the next item (i.e., 4-tokens) exactly
• Qwen3-8B that can return recs and natural language!
eugeneyan.com/writing/sema...
Reposted by Eugene Yan

I’ve seen semantic IDs pop up but never bothered to actually look into them. This write up from @eugeneyan.com is a great intro that also illustrates why they’re pretty interesting for mixing recsys and LLMs eugeneyan.com/writing/sema...

How to Train an LLM-RecSys Hybrid for Steerable Recs with Semantic IDs
An LLM that can converse in English & item IDs, and make recommendations w/o retrieval or tools.
eugeneyan.com
September 18, 2025 at 11:56 AM
I’ve seen semantic IDs pop up but never bothered to actually look into them. This write up from @eugeneyan.com is a great intro that also illustrates why they’re pretty interesting for mixing recsys and LLMs eugeneyan.com/writing/sema...
I've been nerdsniped by the idea of Semantic IDs.
Here's the result of my training runs:
• RQ-VAE to compress item embeddings into tokens
• SASRec to predict the next item (i.e., 4-tokens) exactly
• Qwen3-8B that can return recs and natural language!
eugeneyan.com/writing/sema...
Here's the result of my training runs:
• RQ-VAE to compress item embeddings into tokens
• SASRec to predict the next item (i.e., 4-tokens) exactly
• Qwen3-8B that can return recs and natural language!
eugeneyan.com/writing/sema...
How to Train an LLM-RecSys Hybrid for Steerable Recs with Semantic IDs
An LLM that can converse in English & item IDs, and make recommendations w/o retrieval or tools.
eugeneyan.com
September 17, 2025 at 2:04 AM
I've been nerdsniped by the idea of Semantic IDs.
Here's the result of my training runs:
• RQ-VAE to compress item embeddings into tokens
• SASRec to predict the next item (i.e., 4-tokens) exactly
• Qwen3-8B that can return recs and natural language!
eugeneyan.com/writing/sema...
Here's the result of my training runs:
• RQ-VAE to compress item embeddings into tokens
• SASRec to predict the next item (i.e., 4-tokens) exactly
• Qwen3-8B that can return recs and natural language!
eugeneyan.com/writing/sema...
Reposted by Eugene Yan
Wrote an intro to evals for long-context Q&A systems:
• How it differs from basic Q&A
• What dimensions & metrics to eval on
• How to build llm-evaluators
• How to build eval datasets
• Benchmarks: narratives, technical docs, multi-docs
eugeneyan.com/writing/qa-e...
• How it differs from basic Q&A
• What dimensions & metrics to eval on
• How to build llm-evaluators
• How to build eval datasets
• Benchmarks: narratives, technical docs, multi-docs
eugeneyan.com/writing/qa-e...

Evaluating Long-Context Question & Answer Systems
Evaluation metrics, how to build eval datasets, eval methodology, and a review of several benchmarks.
eugeneyan.com
June 25, 2025 at 1:48 AM
Wrote an intro to evals for long-context Q&A systems:
• How it differs from basic Q&A
• What dimensions & metrics to eval on
• How to build llm-evaluators
• How to build eval datasets
• Benchmarks: narratives, technical docs, multi-docs
eugeneyan.com/writing/qa-e...
• How it differs from basic Q&A
• What dimensions & metrics to eval on
• How to build llm-evaluators
• How to build eval datasets
• Benchmarks: narratives, technical docs, multi-docs
eugeneyan.com/writing/qa-e...
Wrote an intro to evals for long-context Q&A systems:
• How it differs from basic Q&A
• What dimensions & metrics to eval on
• How to build llm-evaluators
• How to build eval datasets
• Benchmarks: narratives, technical docs, multi-docs
eugeneyan.com/writing/qa-e...
• How it differs from basic Q&A
• What dimensions & metrics to eval on
• How to build llm-evaluators
• How to build eval datasets
• Benchmarks: narratives, technical docs, multi-docs
eugeneyan.com/writing/qa-e...
Evaluating Long-Context Question & Answer Systems
Evaluation metrics, how to build eval datasets, eval methodology, and a review of several benchmarks.
eugeneyan.com
June 25, 2025 at 1:48 AM
Wrote an intro to evals for long-context Q&A systems:
• How it differs from basic Q&A
• What dimensions & metrics to eval on
• How to build llm-evaluators
• How to build eval datasets
• Benchmarks: narratives, technical docs, multi-docs
eugeneyan.com/writing/qa-e...
• How it differs from basic Q&A
• What dimensions & metrics to eval on
• How to build llm-evaluators
• How to build eval datasets
• Benchmarks: narratives, technical docs, multi-docs
eugeneyan.com/writing/qa-e...
Some thoughts on leadership: eugeneyan.com/writing/lead...
• What makes an exceptional leader?
• What do exceptional leaders do?
• Leadership styles: Commando, soldier, police
• What makes an exceptional leader?
• What do exceptional leaders do?
• Leadership styles: Commando, soldier, police



May 21, 2025 at 2:17 AM
Some thoughts on leadership: eugeneyan.com/writing/lead...
• What makes an exceptional leader?
• What do exceptional leaders do?
• Leadership styles: Commando, soldier, police
• What makes an exceptional leader?
• What do exceptional leaders do?
• Leadership styles: Commando, soldier, police
The best leaders I’ve worked with operate with perma-urgency. They act like early founders, mindful of existential threats. And they can balance speed, sustainability, and repay tech debt. Ultimately, customers love it and teams thrive when we ship fast to deliver delight.
May 20, 2025 at 2:14 AM
The best leaders I’ve worked with operate with perma-urgency. They act like early founders, mindful of existential threats. And they can balance speed, sustainability, and repay tech debt. Ultimately, customers love it and teams thrive when we ship fast to deliver delight.
Had a fun couple of hours this weekend with Codex & Windsurf
• Migrated off deprecated jekyll-algolia to official sdk (better indexing)
• Added recommendations + relevance scores to each post
• Improved site responsiveness; fixed dark mode flicker
• Marie Kondo-ed unused files & dead code
• Migrated off deprecated jekyll-algolia to official sdk (better indexing)
• Added recommendations + relevance scores to each post
• Improved site responsiveness; fixed dark mode flicker
• Marie Kondo-ed unused files & dead code

May 18, 2025 at 9:06 PM
Had a fun couple of hours this weekend with Codex & Windsurf
• Migrated off deprecated jekyll-algolia to official sdk (better indexing)
• Added recommendations + relevance scores to each post
• Improved site responsiveness; fixed dark mode flicker
• Marie Kondo-ed unused files & dead code
• Migrated off deprecated jekyll-algolia to official sdk (better indexing)
• Added recommendations + relevance scores to each post
• Improved site responsiveness; fixed dark mode flicker
• Marie Kondo-ed unused files & dead code
In orgs pushing the envelope, there's always a minority that can be counted on to get shit done against all odds, driven by force of will, resourcefulness, influence, etc. When you identify them, vest in them authority, autonomy, and step back and watch them perform miracles.
May 14, 2025 at 5:22 AM
In orgs pushing the envelope, there's always a minority that can be counted on to get shit done against all odds, driven by force of will, resourcefulness, influence, etc. When you identify them, vest in them authority, autonomy, and step back and watch them perform miracles.
To better understand MCPs and agentic workflows, I built news-agents to generate a daily news recap. The main agent spawns sub-agents, assigning them news feeds to parse and summarize, and then generates a final overall summary plus analysis.
eugeneyan.com/writing/news...
eugeneyan.com/writing/news...
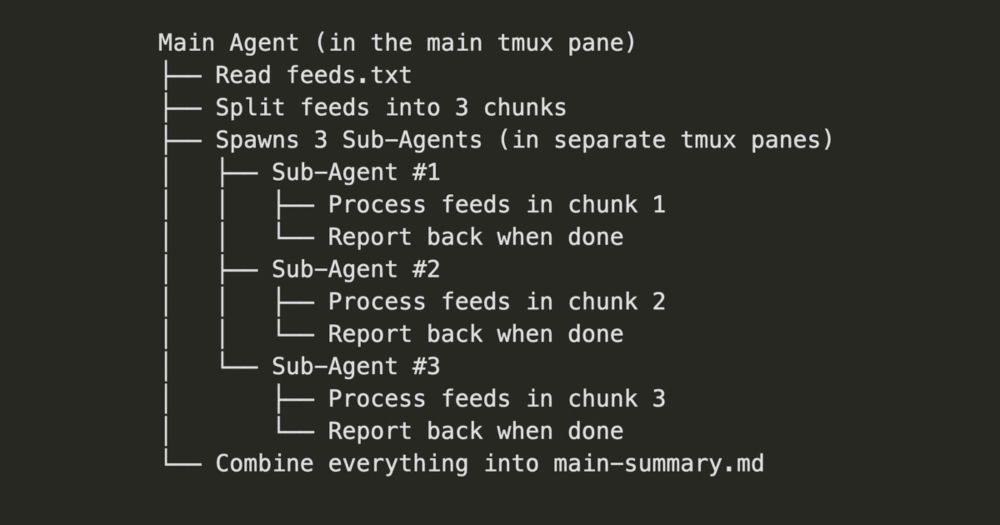
Building News Agents for Daily News Recaps with MCP, Q, and tmux
Learning to automate simple agentic workflows with Amazon Q CLI, Anthropic MCP, and tmux.
eugeneyan.com
May 7, 2025 at 12:21 AM
To better understand MCPs and agentic workflows, I built news-agents to generate a daily news recap. The main agent spawns sub-agents, assigning them news feeds to parse and summarize, and then generates a final overall summary plus analysis.
eugeneyan.com/writing/news...
eugeneyan.com/writing/news...
@hamel.bsky.social & @sh-reya.bsky.social are two of the world's best on evals. They've built evals for 35+ AI apps & helped teams ship confidently. Now they'll teach everything they know on building evals that work.
Enrollment closes in 4 days.
Secret 35% discount code: maven.com/parlance-lab...
Enrollment closes in 4 days.
Secret 35% discount code: maven.com/parlance-lab...

April 30, 2025 at 2:56 AM
@hamel.bsky.social & @sh-reya.bsky.social are two of the world's best on evals. They've built evals for 35+ AI apps & helped teams ship confidently. Now they'll teach everything they know on building evals that work.
Enrollment closes in 4 days.
Secret 35% discount code: maven.com/parlance-lab...
Enrollment closes in 4 days.
Secret 35% discount code: maven.com/parlance-lab...
The Art of Doing Science and Engineering: Learning to Learn by Richard Hamming only $1.99 for the Kindle version today: amazon.com/dp/B088TMLQDC

April 27, 2025 at 11:01 PM
The Art of Doing Science and Engineering: Learning to Learn by Richard Hamming only $1.99 for the Kindle version today: amazon.com/dp/B088TMLQDC
Reposted by Eugene Yan

Enjoyed this on eval-driven product development from @eugeneyan.com. It chimes with my own experiences building around LLMs and search engines, including the thoughts on automated evaluators.
When deconstructed, EDD is just the good old scientific method under a new name
When deconstructed, EDD is just the good old scientific method under a new name

An LLM‑as‑Judge Won't Save The Product—Fixing Your Process Will
Applying the scientific method, building via eval-driven development, and monitoring AI output.
eugeneyan.com
April 26, 2025 at 6:28 PM
Enjoyed this on eval-driven product development from @eugeneyan.com. It chimes with my own experiences building around LLMs and search engines, including the thoughts on automated evaluators.
When deconstructed, EDD is just the good old scientific method under a new name
When deconstructed, EDD is just the good old scientific method under a new name
Surround yourself with people whose "work" is their calling, craft, and play.
They are intrinsically motivated, are driven to excel and do what's right, and and get so much shit done just because it's fun.
They are intrinsically motivated, are driven to excel and do what's right, and and get so much shit done just because it's fun.
April 26, 2025 at 6:01 PM
Surround yourself with people whose "work" is their calling, craft, and play.
They are intrinsically motivated, are driven to excel and do what's right, and and get so much shit done just because it's fun.
They are intrinsically motivated, are driven to excel and do what's right, and and get so much shit done just because it's fun.
Reposted by Eugene Yan

Some of the anti-AI stuff feels a bit like when people would say "don't use Wikipedia as a source." It's just like anything else, a piece of information that you weigh against multiple sources and your own understanding of its likely failure modes
April 26, 2025 at 1:23 PM
Some of the anti-AI stuff feels a bit like when people would say "don't use Wikipedia as a source." It's just like anything else, a piece of information that you weigh against multiple sources and your own understanding of its likely failure modes
Product evals are misunderstood. Many teams think that adding another tool, metric, or llm-as-judge will solve all their problems and save their product. But that just dodges the hard truth and avoids the real work. Here's how to fix your process instead.
eugeneyan.com/writing/eval...
eugeneyan.com/writing/eval...

An LLM‑as‑Judge Won't Save Your Product—Fixing Your Process Will
Applying the scientific method, building via eval-driven development, and monitoring AI output.
eugeneyan.com
April 23, 2025 at 2:45 AM
Product evals are misunderstood. Many teams think that adding another tool, metric, or llm-as-judge will solve all their problems and save their product. But that just dodges the hard truth and avoids the real work. Here's how to fix your process instead.
eugeneyan.com/writing/eval...
eugeneyan.com/writing/eval...
The default state of projects is to drift toward entropy; you need to actively resist & reverse it.
April 19, 2025 at 12:19 AM
The default state of projects is to drift toward entropy; you need to actively resist & reverse it.
Interesting paper from Google that challenges a core assumption in translation evaluation—a single metric can measure both accuracy & naturalness.
They found that the best systems had neural metrics that did not correlate with human preferences.
arxiv.org/abs/2503.24013
They found that the best systems had neural metrics that did not correlate with human preferences.
arxiv.org/abs/2503.24013

You Cannot Feed Two Birds with One Score: the Accuracy-Naturalness Tradeoff in Translation
The goal of translation, be it by human or by machine, is, given some text in a source language, to produce text in a target language that simultaneously 1) preserves the meaning of the source text an...
arxiv.org
April 18, 2025 at 2:07 AM
Interesting paper from Google that challenges a core assumption in translation evaluation—a single metric can measure both accuracy & naturalness.
They found that the best systems had neural metrics that did not correlate with human preferences.
arxiv.org/abs/2503.24013
They found that the best systems had neural metrics that did not correlate with human preferences.
arxiv.org/abs/2503.24013
Had a session with very senior folks on how they build with AI and can’t help thinking there’s no better time to learn, clarify, brainstorm, write, debate, plan, design, code, debug, review, analyze, delegate, play, and in general do more more while doing less with AI—so psyched!
April 17, 2025 at 4:08 AM
Had a session with very senior folks on how they build with AI and can’t help thinking there’s no better time to learn, clarify, brainstorm, write, debate, plan, design, code, debug, review, analyze, delegate, play, and in general do more more while doing less with AI—so psyched!
Great list of what the best devs do, such as:
• Read the source, docs, error msgs
• Simplify problems, write simple code
• Get their hands dirty
• Write to share & write well
• Have beginner's mind & keep learning
• Not afraid to say: I don't know
endler.dev/2025/best-pr...
• Read the source, docs, error msgs
• Simplify problems, write simple code
• Get their hands dirty
• Write to share & write well
• Have beginner's mind & keep learning
• Not afraid to say: I don't know
endler.dev/2025/best-pr...

The Best Programmers I Know | Matthias Endler
I have met a lot of developers in my life.
Late…
endler.dev
April 17, 2025 at 1:45 AM
Great list of what the best devs do, such as:
• Read the source, docs, error msgs
• Simplify problems, write simple code
• Get their hands dirty
• Write to share & write well
• Have beginner's mind & keep learning
• Not afraid to say: I don't know
endler.dev/2025/best-pr...
• Read the source, docs, error msgs
• Simplify problems, write simple code
• Get their hands dirty
• Write to share & write well
• Have beginner's mind & keep learning
• Not afraid to say: I don't know
endler.dev/2025/best-pr...
@hamel.bsky.social & his wisdom on evals, error analysis, looking at your data is what we need. Here are his 10 Don'ts:
• Don't skip error analysis
• Don't skip looking at your data
• Don't gatekeep who can write prompts
• Don't let zero users be a roadblock
• Don't be blindsided by criteria drift
• Don't skip error analysis
• Don't skip looking at your data
• Don't gatekeep who can write prompts
• Don't let zero users be a roadblock
• Don't be blindsided by criteria drift
April 16, 2025 at 1:05 AM
@hamel.bsky.social & his wisdom on evals, error analysis, looking at your data is what we need. Here are his 10 Don'ts:
• Don't skip error analysis
• Don't skip looking at your data
• Don't gatekeep who can write prompts
• Don't let zero users be a roadblock
• Don't be blindsided by criteria drift
• Don't skip error analysis
• Don't skip looking at your data
• Don't gatekeep who can write prompts
• Don't let zero users be a roadblock
• Don't be blindsided by criteria drift
Great example of generate -> validate loop + error analysis
> "the most effective route to improve outcomes was brute force: retry steps until they passed or reached a limit. We give the validation errors ... to the LLM and built a loop runner"
> "the most effective route to improve outcomes was brute force: retry steps until they passed or reached a limit. We give the validation errors ... to the LLM and built a loop runner"

April 15, 2025 at 1:57 AM
Great example of generate -> validate loop + error analysis
> "the most effective route to improve outcomes was brute force: retry steps until they passed or reached a limit. We give the validation errors ... to the LLM and built a loop runner"
> "the most effective route to improve outcomes was brute force: retry steps until they passed or reached a limit. We give the validation errors ... to the LLM and built a loop runner"
Reposted by Eugene Yan

This is a great list, things that “the best engineers I know” do, stuff like:
- understanding things deeply, reading the actual source
- being willing to help other people
- status doesn’t matter, good ideas come from anywhere
endler.dev/2025/best-pr...
- understanding things deeply, reading the actual source
- being willing to help other people
- status doesn’t matter, good ideas come from anywhere
endler.dev/2025/best-pr...

The Best Programmers I Know | Matthias Endler
I have met a lot of developers in my life.
Late…
endler.dev
April 13, 2025 at 3:57 PM
This is a great list, things that “the best engineers I know” do, stuff like:
- understanding things deeply, reading the actual source
- being willing to help other people
- status doesn’t matter, good ideas come from anywhere
endler.dev/2025/best-pr...
- understanding things deeply, reading the actual source
- being willing to help other people
- status doesn’t matter, good ideas come from anywhere
endler.dev/2025/best-pr...
Stumbled on the first(?) RAG in NarrativeQA from 2017.
Because books & movies were too large for LSTMs to do Q&A on, they embedded 200-word chunks and retrieved similar snippets to answer questions.
"Chunking and cosine similarity retrieval is so 2017."
arxiv.org/abs/1712.07040
Because books & movies were too large for LSTMs to do Q&A on, they embedded 200-word chunks and retrieved similar snippets to answer questions.
"Chunking and cosine similarity retrieval is so 2017."
arxiv.org/abs/1712.07040


April 12, 2025 at 5:34 PM
Stumbled on the first(?) RAG in NarrativeQA from 2017.
Because books & movies were too large for LSTMs to do Q&A on, they embedded 200-word chunks and retrieved similar snippets to answer questions.
"Chunking and cosine similarity retrieval is so 2017."
arxiv.org/abs/1712.07040
Because books & movies were too large for LSTMs to do Q&A on, they embedded 200-word chunks and retrieved similar snippets to answer questions.
"Chunking and cosine similarity retrieval is so 2017."
arxiv.org/abs/1712.07040
If you were building a Q&A feature (or chatbot) based on very long documents (like books), what evals would you focus on?
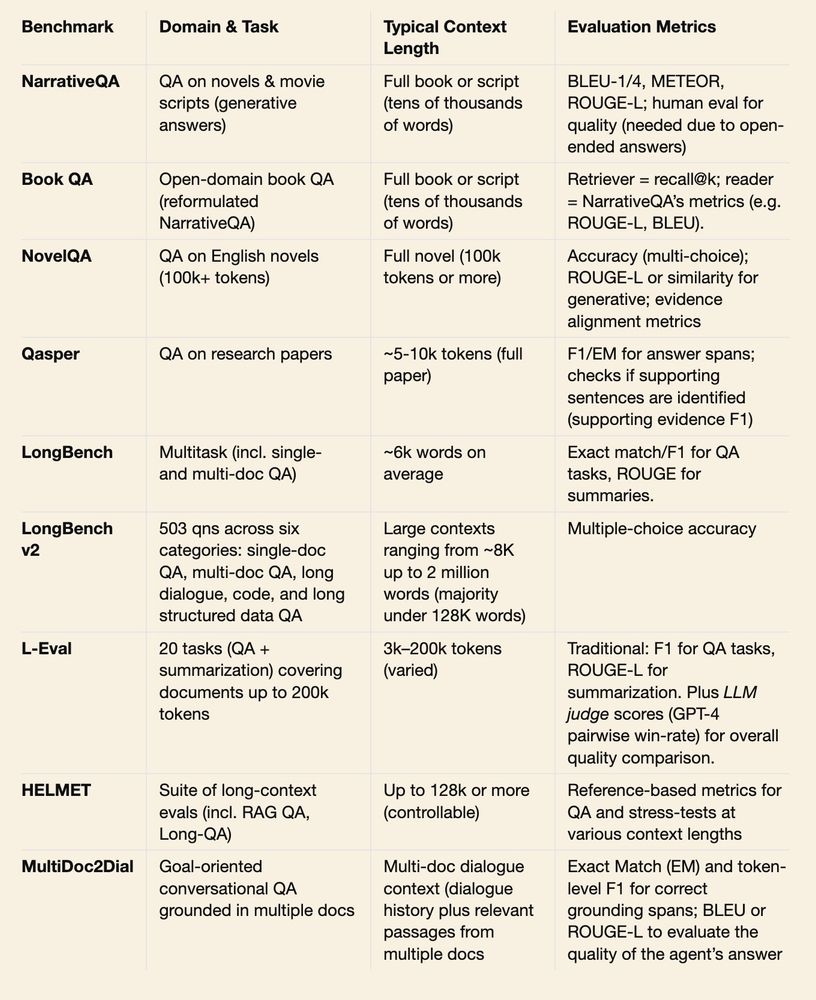
April 9, 2025 at 1:48 AM
If you were building a Q&A feature (or chatbot) based on very long documents (like books), what evals would you focus on?
Can't wait for when I can vibe code a production recommender system.
Until then, here's some system designs:
• Retrieval vs. Ranking: eugeneyan.com/writing/syst...
• Real-time retrieval: eugeneyan.com/writing/real...
• Personalization: eugeneyan.com/writing/patt...
Until then, here's some system designs:
• Retrieval vs. Ranking: eugeneyan.com/writing/syst...
• Real-time retrieval: eugeneyan.com/writing/real...
• Personalization: eugeneyan.com/writing/patt...
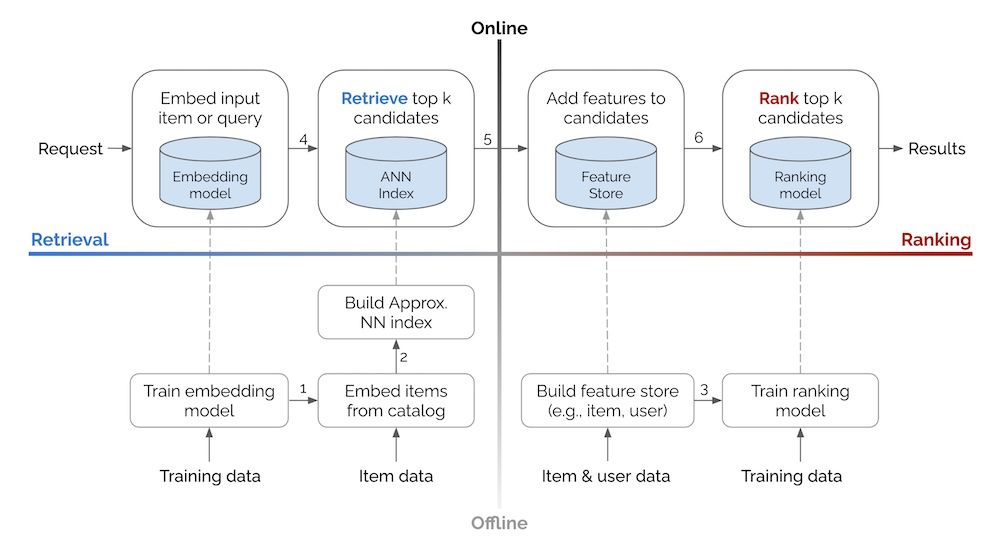
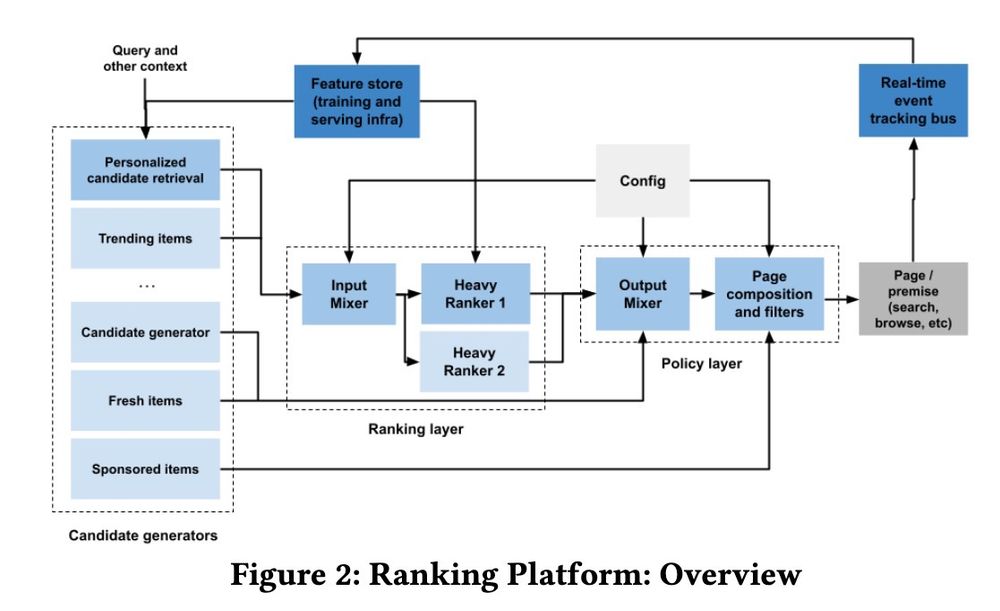
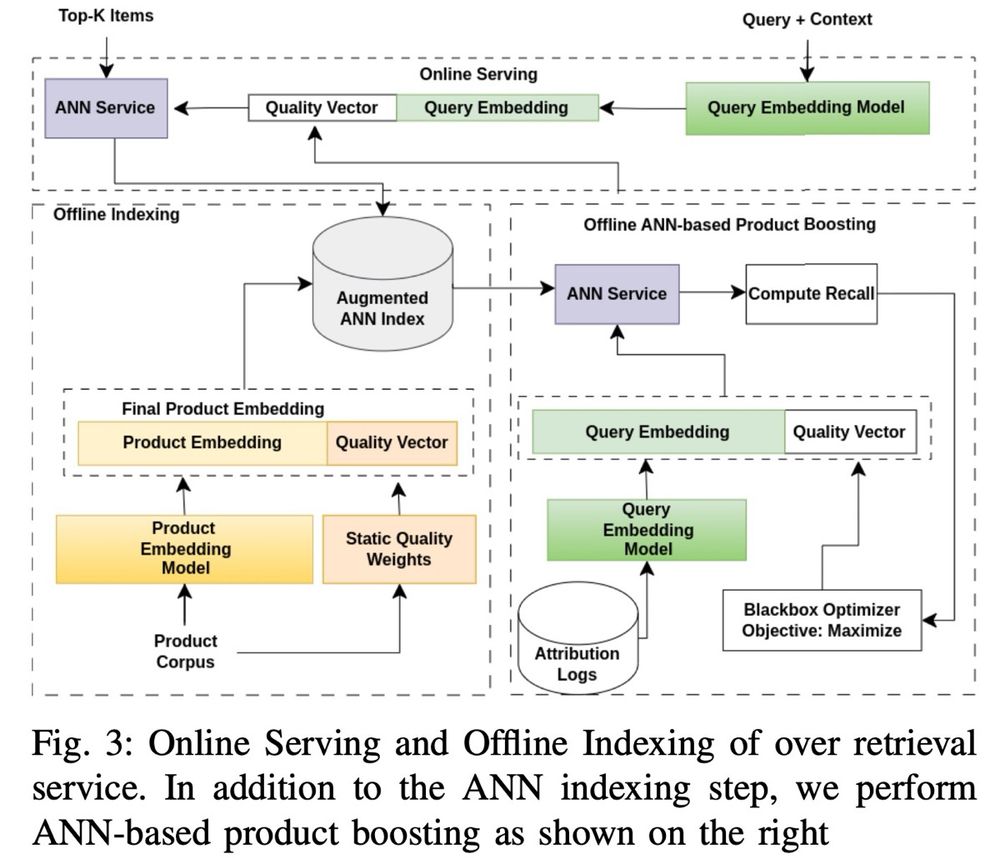
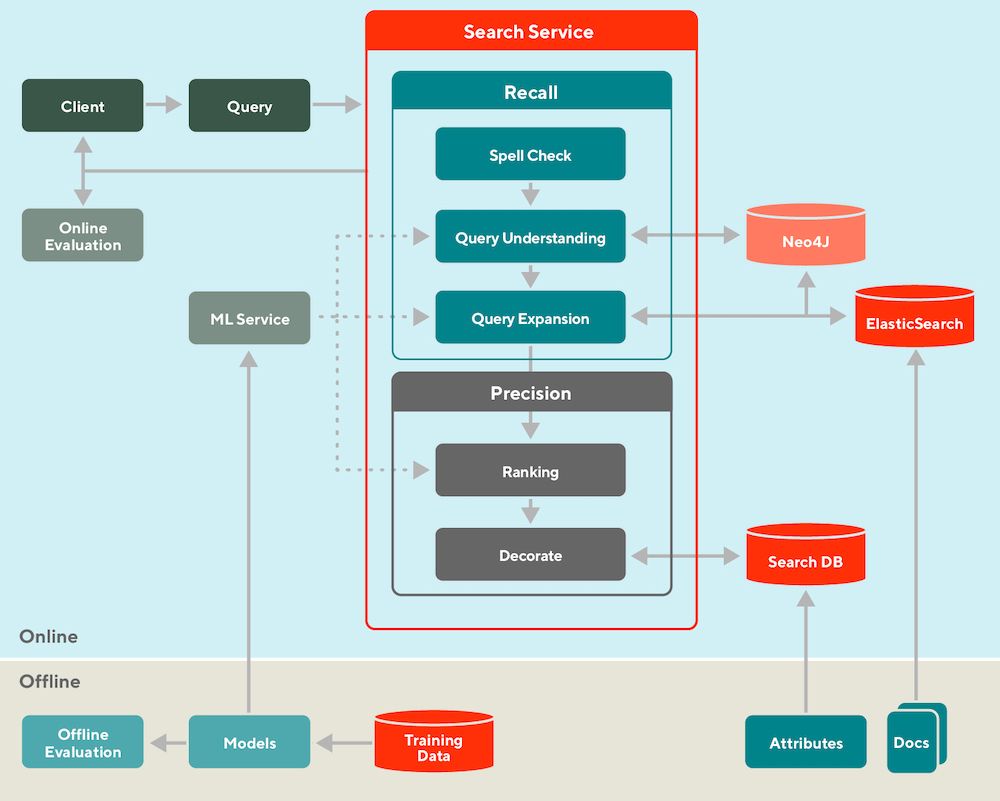
April 8, 2025 at 5:14 AM
Can't wait for when I can vibe code a production recommender system.
Until then, here's some system designs:
• Retrieval vs. Ranking: eugeneyan.com/writing/syst...
• Real-time retrieval: eugeneyan.com/writing/real...
• Personalization: eugeneyan.com/writing/patt...
Until then, here's some system designs:
• Retrieval vs. Ranking: eugeneyan.com/writing/syst...
• Real-time retrieval: eugeneyan.com/writing/real...
• Personalization: eugeneyan.com/writing/patt...