Francois Keck
@francoiskeck.bsky.social
590 followers
260 following
24 posts
Digital community ecologist. I pursue the laws of nature on my computer.
#rstats | #eDNA | #biodiversity | #ecology | and more
https://francoiskeck.fr/
Posts
Media
Videos
Starter Packs
Pinned

Reposted by Francois Keck



Reposted by Francois Keck



Reposted by Francois Keck

Reposted by Francois Keck

Selina Baldauf
@selina-b.bsky.social
· Aug 17


Reposted by Francois Keck







Reposted by Francois Keck

Reposted by Francois Keck



Francois Keck
@francoiskeck.bsky.social
· Jul 18


Reposted by Francois Keck



Reposted by Francois Keck



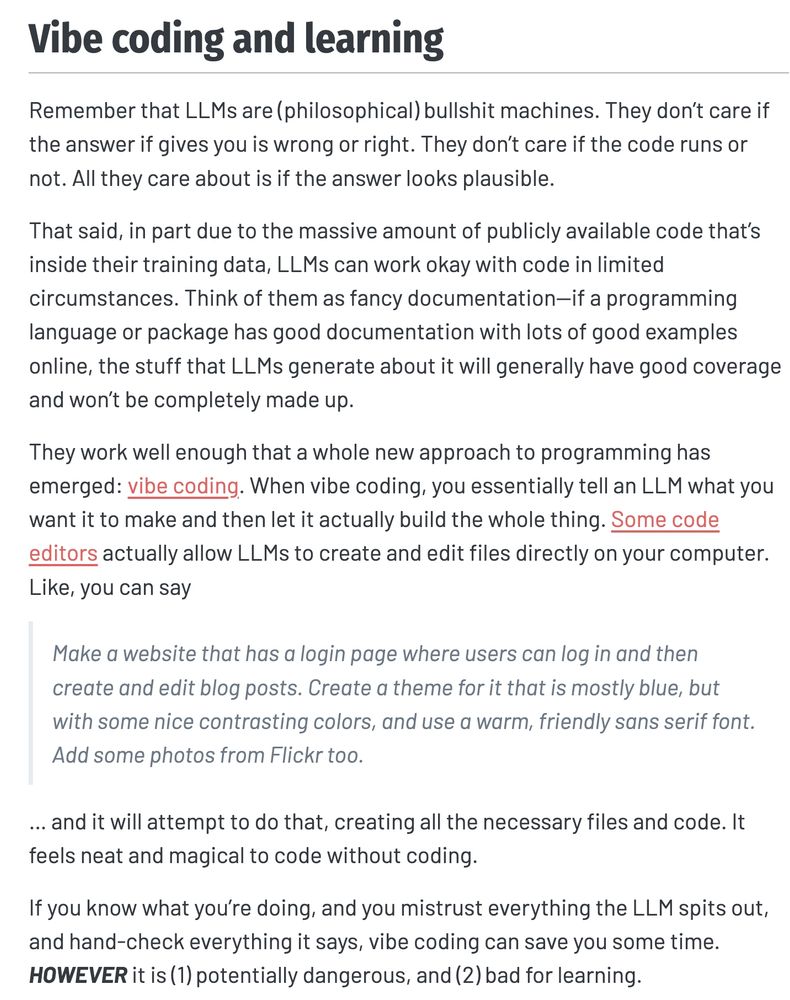
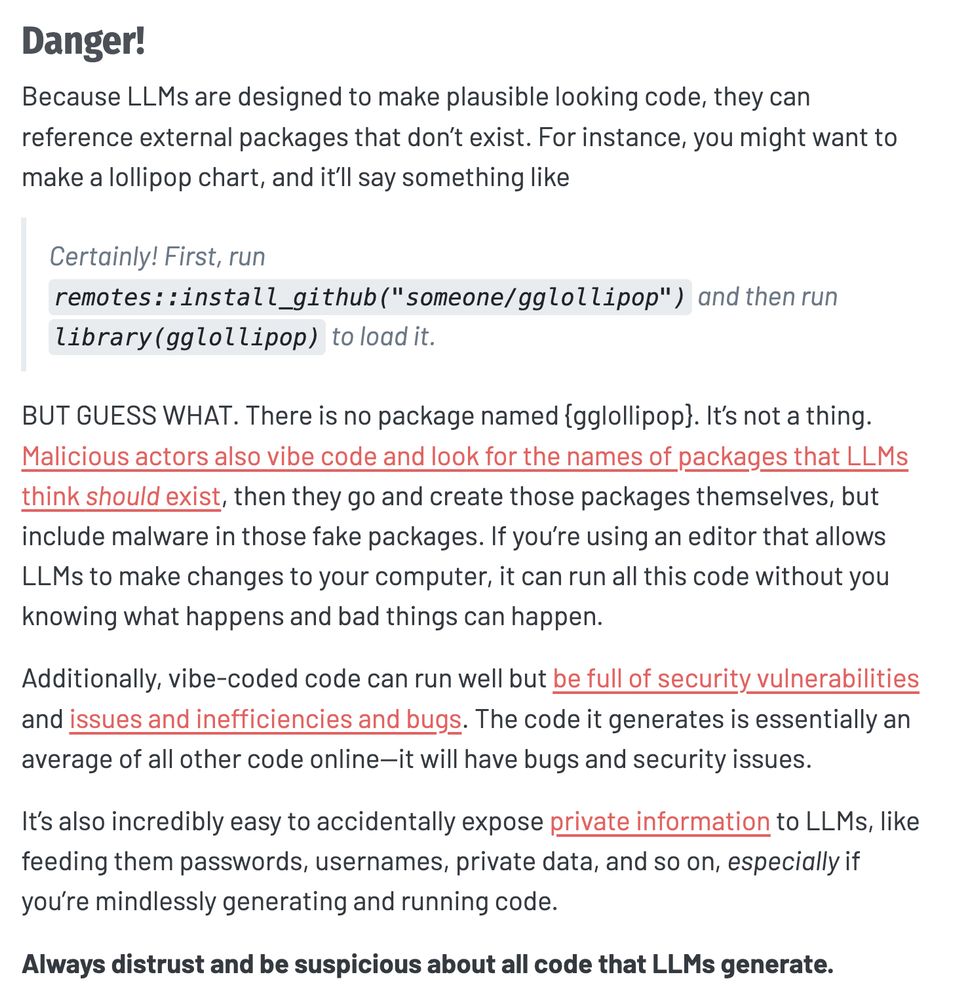
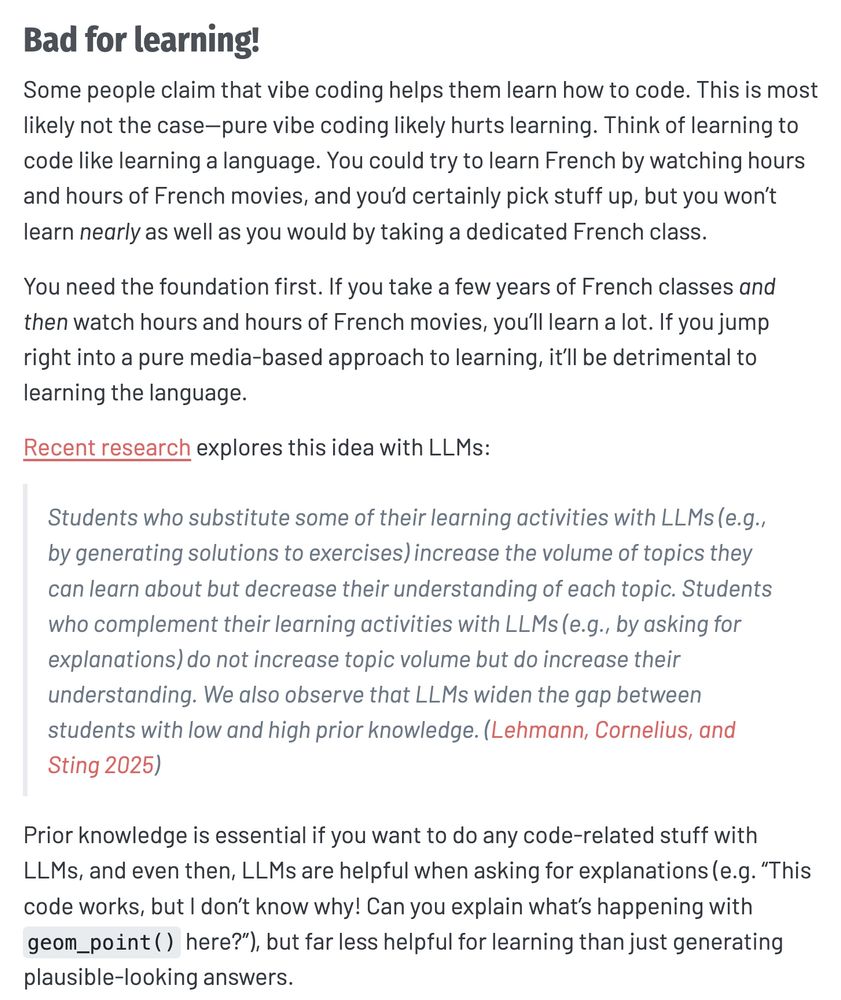
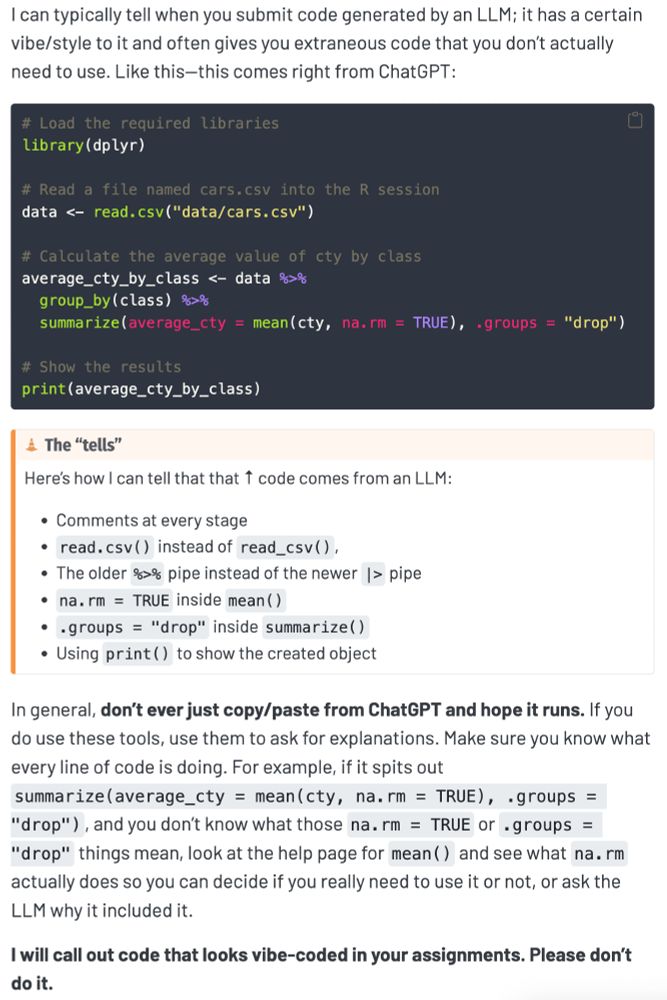
Reposted by Francois Keck

Jonathan Tonkin
@jdtonkin.bsky.social
· May 29
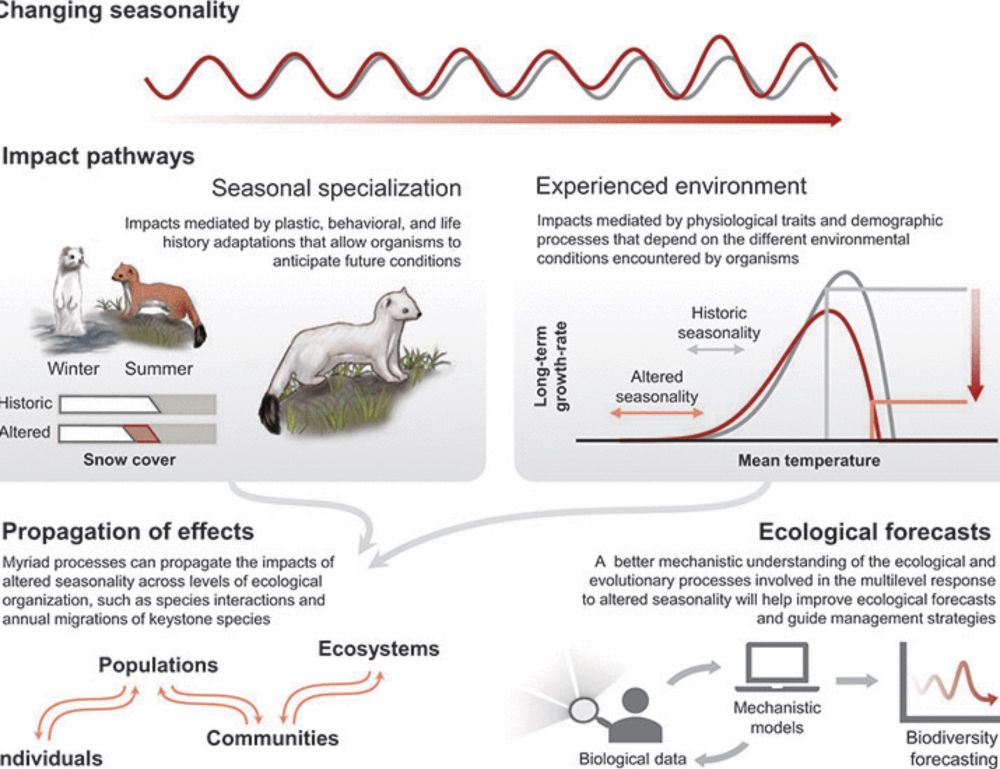
Ecological and evolutionary consequences of changing seasonality
Climate change and other anthropogenic drivers alter seasonal regimes across freshwater, terrestrial, and marine biomes. Seasonal patterns affect ecological and evolutionary processes at different eco...
www.science.org