



Gerard I. Gállego
@geiongallego.bsky.social
We trace this behavior back to ASR. As pseudo-labeled S2TT data scales, CoT models suffer a clear degradation in ASR performance, which probably hurts the final translations. In contrast, Direct S2TT largely preserves its ASR capability.
[7/8]
[7/8]

November 26, 2025 at 7:10 AM
We trace this behavior back to ASR. As pseudo-labeled S2TT data scales, CoT models suffer a clear degradation in ASR performance, which probably hurts the final translations. In contrast, Direct S2TT largely preserves its ASR capability.
[7/8]
[7/8]
These trends hold across languages and translation directions.
[6/8]
[6/8]

November 26, 2025 at 7:10 AM
These trends hold across languages and translation directions.
[6/8]
[6/8]
Our main result: Direct S2TT keeps improving as we add more pseudo-labeled data, while CoT systems peak early and then degrade as synthetic data grows.
Direct shows a much steadier scaling, closing the initial gap with CoT.
[5/8]
Direct shows a much steadier scaling, closing the initial gap with CoT.
[5/8]

November 26, 2025 at 7:10 AM
Our main result: Direct S2TT keeps improving as we add more pseudo-labeled data, while CoT systems peak early and then degrade as synthetic data grows.
Direct shows a much steadier scaling, closing the initial gap with CoT.
[5/8]
Direct shows a much steadier scaling, closing the initial gap with CoT.
[5/8]
The S2TT data gap can be narrowed with pseudo-labeling, created by translating ASR corpora with a strong text MT system.
We follow this approach and ask: as pseudo-labeled S2TT data grows, do CoT and Direct scale in the same way?
[4/8]
We follow this approach and ask: as pseudo-labeled S2TT data grows, do CoT and Direct scale in the same way?
[4/8]

November 26, 2025 at 7:10 AM
The S2TT data gap can be narrowed with pseudo-labeling, created by translating ASR corpora with a strong text MT system.
We follow this approach and ask: as pseudo-labeled S2TT data grows, do CoT and Direct scale in the same way?
[4/8]
We follow this approach and ask: as pseudo-labeled S2TT data grows, do CoT and Direct scale in the same way?
[4/8]
Lately we have been studying how Speech-to-Text Translation (S2TT) systems scale with more data. 🚀
We find that Direct S2TT scales more reliably than Chain of Thought (CoT) prompting when trained on pseudo-labeled data.
[1/8]
We find that Direct S2TT scales more reliably than Chain of Thought (CoT) prompting when trained on pseudo-labeled data.
[1/8]

November 26, 2025 at 7:10 AM
Lately we have been studying how Speech-to-Text Translation (S2TT) systems scale with more data. 🚀
We find that Direct S2TT scales more reliably than Chain of Thought (CoT) prompting when trained on pseudo-labeled data.
[1/8]
We find that Direct S2TT scales more reliably than Chain of Thought (CoT) prompting when trained on pseudo-labeled data.
[1/8]
Finally, we test simple training interventions. Injecting corrupted transcripts during training brings the largest improvement. This is particularly effective for increasing robustness to error propagation!
[8/9]
[8/9]

November 26, 2025 at 6:54 AM
Finally, we test simple training interventions. Injecting corrupted transcripts during training brings the largest improvement. This is particularly effective for increasing robustness to error propagation!
[8/9]
[8/9]
We then corrupt the transcript to test whether CoT falls back to the speech signal.
Instead, translation quality drops sharply, almost identical to the cascade baseline.
[6/9]
Instead, translation quality drops sharply, almost identical to the cascade baseline.
[6/9]

November 26, 2025 at 6:54 AM
We then corrupt the transcript to test whether CoT falls back to the speech signal.
Instead, translation quality drops sharply, almost identical to the cascade baseline.
[6/9]
Instead, translation quality drops sharply, almost identical to the cascade baseline.
[6/9]
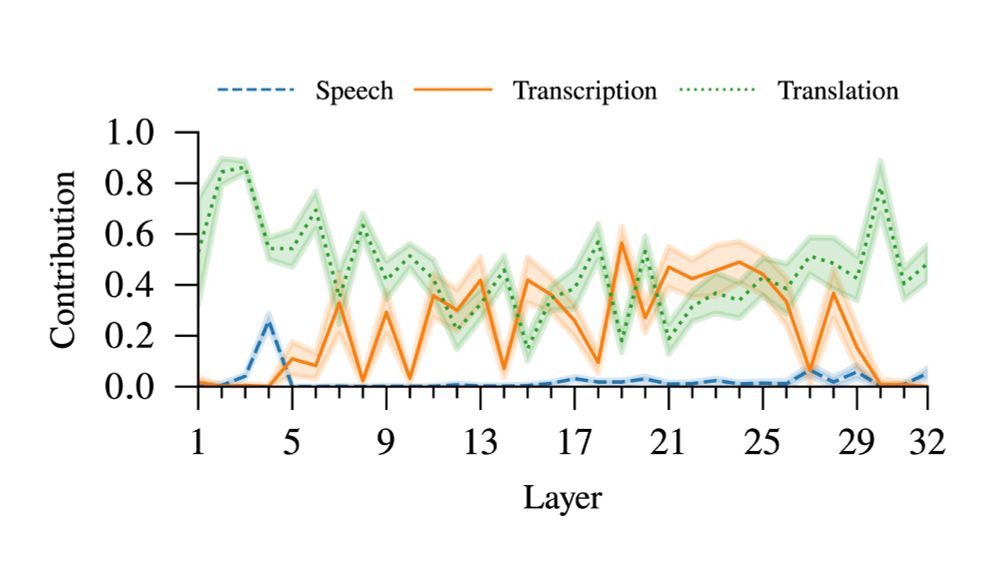
Main takeaway: CoT behaves very similarly to a cascade S2TT system.
Input attribution analysis shows that, during translation, the model uses information mainly from the transcript rather than the audio.
[5/9]
Input attribution analysis shows that, during translation, the model uses information mainly from the transcript rather than the audio.
[5/9]
November 26, 2025 at 6:54 AM
Main takeaway: CoT behaves very similarly to a cascade S2TT system.
Input attribution analysis shows that, during translation, the model uses information mainly from the transcript rather than the audio.
[5/9]
Input attribution analysis shows that, during translation, the model uses information mainly from the transcript rather than the audio.
[5/9]
During the last months we have been curious whether Chain-of-Thought (CoT) Speech-to-Text Translation (S2TT) systems truly use the spoken input during translation.
We find that they rely more on the transcript and behave closer to cascade systems than expected.
[1/9]
We find that they rely more on the transcript and behave closer to cascade systems than expected.
[1/9]

November 26, 2025 at 6:54 AM
During the last months we have been curious whether Chain-of-Thought (CoT) Speech-to-Text Translation (S2TT) systems truly use the spoken input during translation.
We find that they rely more on the transcript and behave closer to cascade systems than expected.
[1/9]
We find that they rely more on the transcript and behave closer to cascade systems than expected.
[1/9]