



Gerard I. Gállego
@geiongallego.bsky.social
This is an important signal for S2TT. If large-scale pseudo-labeling continues to expand, Direct S2TT may offer a more efficient and robust path than CoT!
📄 Paper: arxiv.org/abs/2510.03093
[8/8]
📄 Paper: arxiv.org/abs/2510.03093
[8/8]

Revisiting Direct Speech-to-Text Translation with Speech LLMs: Better Scaling than CoT Prompting?
Recent work on Speech-to-Text Translation (S2TT) has focused on LLM-based models, introducing the increasingly adopted Chain-of-Thought (CoT) prompting, where the model is guided to first transcribe t...
arxiv.org
November 26, 2025 at 7:10 AM
This is an important signal for S2TT. If large-scale pseudo-labeling continues to expand, Direct S2TT may offer a more efficient and robust path than CoT!
📄 Paper: arxiv.org/abs/2510.03093
[8/8]
📄 Paper: arxiv.org/abs/2510.03093
[8/8]
We trace this behavior back to ASR. As pseudo-labeled S2TT data scales, CoT models suffer a clear degradation in ASR performance, which probably hurts the final translations. In contrast, Direct S2TT largely preserves its ASR capability.
[7/8]
[7/8]

November 26, 2025 at 7:10 AM
We trace this behavior back to ASR. As pseudo-labeled S2TT data scales, CoT models suffer a clear degradation in ASR performance, which probably hurts the final translations. In contrast, Direct S2TT largely preserves its ASR capability.
[7/8]
[7/8]
These trends hold across languages and translation directions.
[6/8]
[6/8]

November 26, 2025 at 7:10 AM
These trends hold across languages and translation directions.
[6/8]
[6/8]
Our main result: Direct S2TT keeps improving as we add more pseudo-labeled data, while CoT systems peak early and then degrade as synthetic data grows.
Direct shows a much steadier scaling, closing the initial gap with CoT.
[5/8]
Direct shows a much steadier scaling, closing the initial gap with CoT.
[5/8]

November 26, 2025 at 7:10 AM
Our main result: Direct S2TT keeps improving as we add more pseudo-labeled data, while CoT systems peak early and then degrade as synthetic data grows.
Direct shows a much steadier scaling, closing the initial gap with CoT.
[5/8]
Direct shows a much steadier scaling, closing the initial gap with CoT.
[5/8]
The S2TT data gap can be narrowed with pseudo-labeling, created by translating ASR corpora with a strong text MT system.
We follow this approach and ask: as pseudo-labeled S2TT data grows, do CoT and Direct scale in the same way?
[4/8]
We follow this approach and ask: as pseudo-labeled S2TT data grows, do CoT and Direct scale in the same way?
[4/8]

November 26, 2025 at 7:10 AM
The S2TT data gap can be narrowed with pseudo-labeling, created by translating ASR corpora with a strong text MT system.
We follow this approach and ask: as pseudo-labeled S2TT data grows, do CoT and Direct scale in the same way?
[4/8]
We follow this approach and ask: as pseudo-labeled S2TT data grows, do CoT and Direct scale in the same way?
[4/8]
CoT helps because ASR and text-to-text resources are far more abundant than S2TT data. The drawback is that CoT roughly doubles inference time, and it behaves closer to a cascade system than expected → We have a paper on that! See my previous thread for details.
[3/8]
[3/8]
November 26, 2025 at 7:10 AM
CoT helps because ASR and text-to-text resources are far more abundant than S2TT data. The drawback is that CoT roughly doubles inference time, and it behaves closer to a cascade system than expected → We have a paper on that! See my previous thread for details.
[3/8]
[3/8]
Recent work often adopts a CoT or multi-turn S2TT approach: an LLM-based model first transcribes the speech and then translates it.
This usually surpasses Direct S2TT, where the model produces a translation from speech in one step.
[2/8]
This usually surpasses Direct S2TT, where the model produces a translation from speech in one step.
[2/8]
November 26, 2025 at 7:10 AM
Recent work often adopts a CoT or multi-turn S2TT approach: an LLM-based model first transcribes the speech and then translates it.
This usually surpasses Direct S2TT, where the model produces a translation from speech in one step.
[2/8]
This usually surpasses Direct S2TT, where the model produces a translation from speech in one step.
[2/8]
Finally, we test simple training interventions. Injecting corrupted transcripts during training brings the largest improvement. This is particularly effective for increasing robustness to error propagation!
[8/9]
[8/9]

November 26, 2025 at 6:54 AM
Finally, we test simple training interventions. Injecting corrupted transcripts during training brings the largest improvement. This is particularly effective for increasing robustness to error propagation!
[8/9]
[8/9]
We also evaluate prosody with the ContraProST benchmark.
CoT scores remain close to cascade, which suggests that prosodic cues are used only minimally.
[7/9]
CoT scores remain close to cascade, which suggests that prosodic cues are used only minimally.
[7/9]
November 26, 2025 at 6:54 AM
We also evaluate prosody with the ContraProST benchmark.
CoT scores remain close to cascade, which suggests that prosodic cues are used only minimally.
[7/9]
CoT scores remain close to cascade, which suggests that prosodic cues are used only minimally.
[7/9]
We then corrupt the transcript to test whether CoT falls back to the speech signal.
Instead, translation quality drops sharply, almost identical to the cascade baseline.
[6/9]
Instead, translation quality drops sharply, almost identical to the cascade baseline.
[6/9]

November 26, 2025 at 6:54 AM
We then corrupt the transcript to test whether CoT falls back to the speech signal.
Instead, translation quality drops sharply, almost identical to the cascade baseline.
[6/9]
Instead, translation quality drops sharply, almost identical to the cascade baseline.
[6/9]
Main takeaway: CoT behaves very similarly to a cascade S2TT system.
Input attribution analysis shows that, during translation, the model uses information mainly from the transcript rather than the audio.
[5/9]
Input attribution analysis shows that, during translation, the model uses information mainly from the transcript rather than the audio.
[5/9]
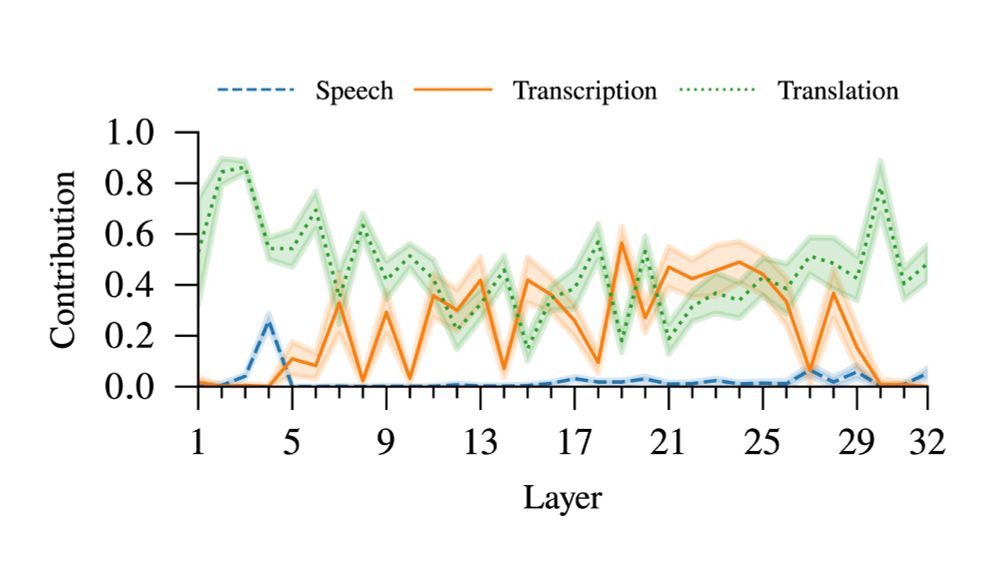
November 26, 2025 at 6:54 AM
Main takeaway: CoT behaves very similarly to a cascade S2TT system.
Input attribution analysis shows that, during translation, the model uses information mainly from the transcript rather than the audio.
[5/9]
Input attribution analysis shows that, during translation, the model uses information mainly from the transcript rather than the audio.
[5/9]
We evaluate three aspects:
- How much the model relies on speech versus text through interpretability
- How robust it is to errors in the transcript
- How well it uses prosody during translation
[4/9]
- How much the model relies on speech versus text through interpretability
- How robust it is to errors in the transcript
- How well it uses prosody during translation
[4/9]
November 26, 2025 at 6:54 AM
We evaluate three aspects:
- How much the model relies on speech versus text through interpretability
- How robust it is to errors in the transcript
- How well it uses prosody during translation
[4/9]
- How much the model relies on speech versus text through interpretability
- How robust it is to errors in the transcript
- How well it uses prosody during translation
[4/9]
But does CoT actually use acoustic information when generating the translation?
Or does it mainly rely on the transcript and ignore the speech signal?
We compare CoT directly with cascade systems to study this question.
[3/9]
Or does it mainly rely on the transcript and ignore the speech signal?
We compare CoT directly with cascade systems to study this question.
[3/9]
November 26, 2025 at 6:54 AM
But does CoT actually use acoustic information when generating the translation?
Or does it mainly rely on the transcript and ignore the speech signal?
We compare CoT directly with cascade systems to study this question.
[3/9]
Or does it mainly rely on the transcript and ignore the speech signal?
We compare CoT directly with cascade systems to study this question.
[3/9]
CoT S2TT (or multi-turn) has become common. The model first transcribes the speech input and then translates it.
This is often assumed to help, because it has access to both speech and transcript. This should reduce error propagation and allow the use of acoustic cues.
[2/9]
This is often assumed to help, because it has access to both speech and transcript. This should reduce error propagation and allow the use of acoustic cues.
[2/9]
November 26, 2025 at 6:54 AM
CoT S2TT (or multi-turn) has become common. The model first transcribes the speech input and then translates it.
This is often assumed to help, because it has access to both speech and transcript. This should reduce error propagation and allow the use of acoustic cues.
[2/9]
This is often assumed to help, because it has access to both speech and transcript. This should reduce error propagation and allow the use of acoustic cues.
[2/9]
Excited to share that this work was accepted to Interspeech 2025. See you in Rotterdam!
Preprint: arxiv.org/abs/2505.24691
Preprint: arxiv.org/abs/2505.24691
Speech-to-Text Translation with Phoneme-Augmented CoT: Enhancing Cross-Lingual Transfer in Low-Resource Scenarios
We propose a Speech-to-Text Translation (S2TT) approach that integrates phoneme representations into a Chain-of-Thought (CoT) framework to improve translation in low-resource and zero-resource setting...
arxiv.org
June 3, 2025 at 8:53 PM
Excited to share that this work was accepted to Interspeech 2025. See you in Rotterdam!
Preprint: arxiv.org/abs/2505.24691
Preprint: arxiv.org/abs/2505.24691
By adding phoneme recognition as an intermediate step, we improve cross-lingual transfer, even for languages with no labeled speech. The method boosts low-resource performance, with only a slight drop in high-resource scenarios.
June 3, 2025 at 8:53 PM
By adding phoneme recognition as an intermediate step, we improve cross-lingual transfer, even for languages with no labeled speech. The method boosts low-resource performance, with only a slight drop in high-resource scenarios.
In my first project at BSC, we worked on improving speech-to-text translation for low-resource languages. Our paper, "Speech-to-Text Translation with Phoneme-Augmented CoT", presents an LLM-based model that integrates phoneme recognition into the CoT approach.
June 3, 2025 at 8:53 PM
In my first project at BSC, we worked on improving speech-to-text translation for low-resource languages. Our paper, "Speech-to-Text Translation with Phoneme-Augmented CoT", presents an LLM-based model that integrates phoneme recognition into the CoT approach.
Wishing everyone a Happy New Year! Stay tuned for this work to be presented at #ICASSP2025.
arxiv.org/abs/2409.11003
arxiv.org/abs/2409.11003
Single-stage TTS with Masked Audio Token Modeling and Semantic Knowledge Distillation
Audio token modeling has become a powerful framework for speech synthesis, with two-stage approaches employing semantic tokens remaining prevalent. In this paper, we aim to simplify this process by in...
arxiv.org
December 31, 2024 at 7:48 PM
Wishing everyone a Happy New Year! Stay tuned for this work to be presented at #ICASSP2025.
arxiv.org/abs/2409.11003
arxiv.org/abs/2409.11003
This research was conducted during my internship at Dolby Labs. A special thanks to Roy Fejgin, Chunghsin Yeh, Xiaoyu Liu, and Gautam Bhattacharya for their mentorship and collaboration.
December 31, 2024 at 7:48 PM
This research was conducted during my internship at Dolby Labs. A special thanks to Roy Fejgin, Chunghsin Yeh, Xiaoyu Liu, and Gautam Bhattacharya for their mentorship and collaboration.
With this approach, we demonstrate that single-stage NAR systems can perform competitively compared to more complex two-stage models, narrowing the gap in quality and intelligibility.
December 31, 2024 at 7:48 PM
With this approach, we demonstrate that single-stage NAR systems can perform competitively compared to more complex two-stage models, narrowing the gap in quality and intelligibility.