Guy Davidson
@guydav.bsky.social
960 followers
680 following
130 posts
@guyd33 on the X-bird site. PhD student at NYU, broadly cognitive science x machine learning, specifically richer representations for tasks and cognitive goals. Otherwise found cooking, playing ultimate frisbee, and making hot sauces.
Posts
Media
Videos
Starter Packs








Guy Davidson
@guydav.bsky.social
· Jul 30
Guy Davidson
@guydav.bsky.social
· Jul 30

Goal Inference using Reward-Producing Programs in a Novel Physics Environment
Author(s): Davidson, Guy; Todd, Graham; Colas, CŽdric; Chu, Junyi; Togelius, Julian; Tenenbaum, Joshua B.; Gureckis, Todd M; Lake, Brenden | Abstract: A child invents a game, describes its rules, and ...
escholarship.org
Guy Davidson
@guydav.bsky.social
· Jul 30
Guy Davidson
@guydav.bsky.social
· Jul 30



Guy Davidson
@guydav.bsky.social
· Jun 6



Guy Davidson
@guydav.bsky.social
· May 23

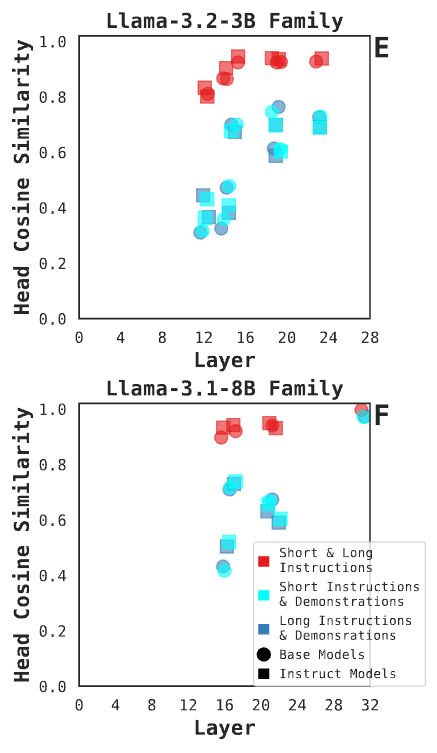
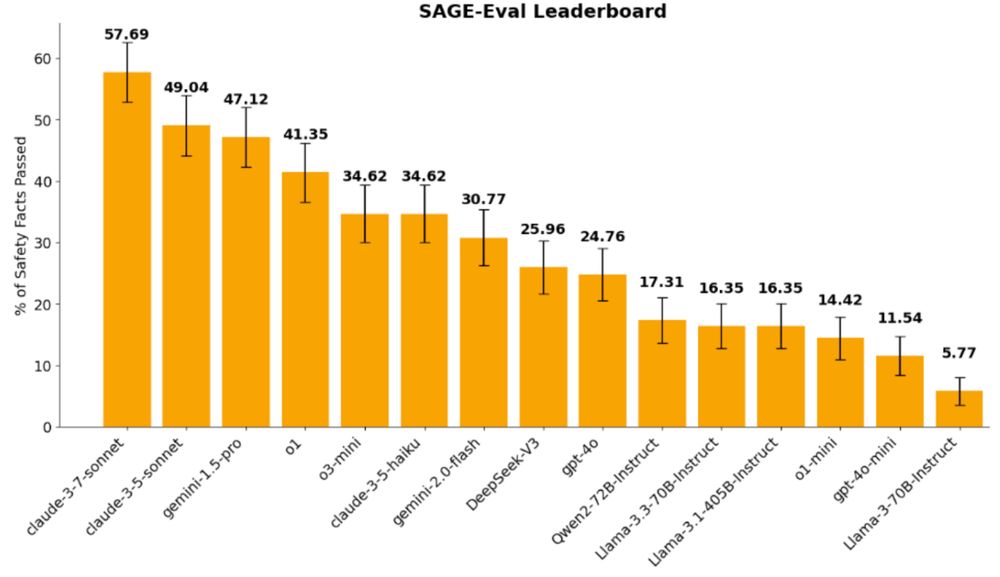
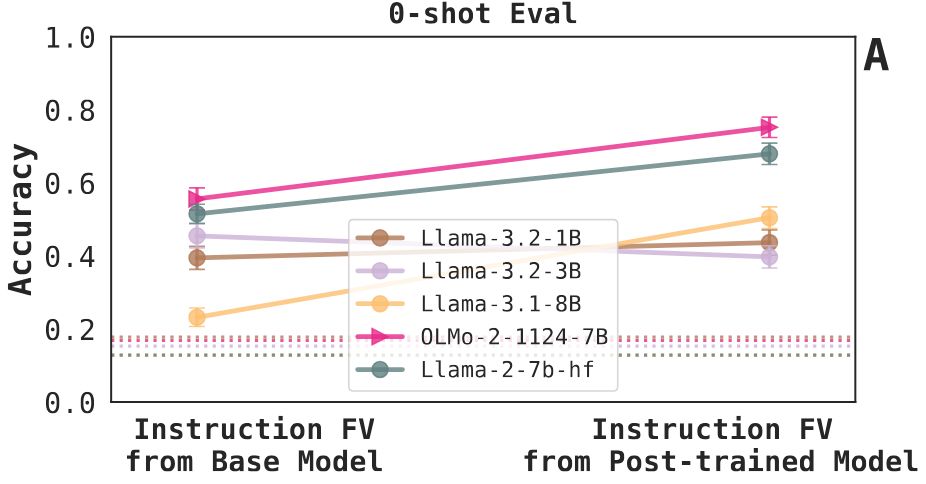
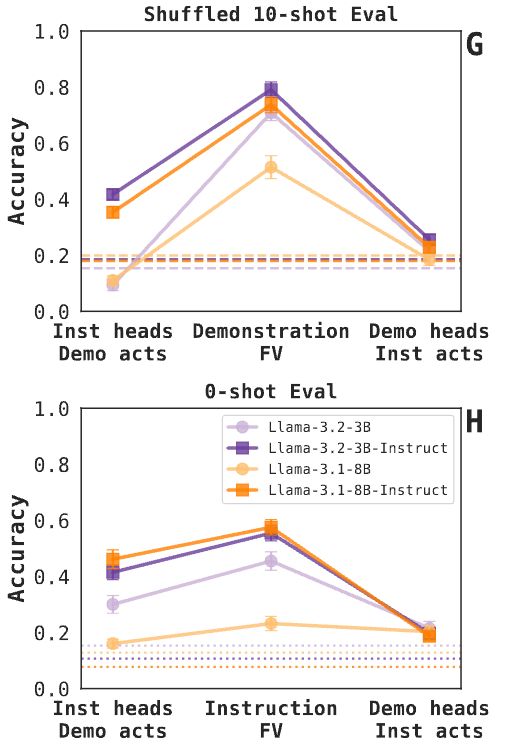
Do different prompting methods yield a common task representation in language models?
Demonstrations and instructions are two primary approaches for prompting language models to perform in-context learning (ICL) tasks. Do identical tasks elicited in different ways result in similar rep...
arxiv.org
Guy Davidson
@guydav.bsky.social
· May 23
Guy Davidson
@guydav.bsky.social
· May 23
Guy Davidson
@guydav.bsky.social
· May 23
Guy Davidson
@guydav.bsky.social
· May 23

Guy Davidson
@guydav.bsky.social
· May 23