




Sam Harsimony
@harsimony.bsky.social
I write about opportunities in science, space, and policy here: https://splittinginfinity.substack.com/
Pinned
Sam Harsimony
@harsimony.bsky.social
· Jan 26
Thread of my new posts in the replies (and some summaries of old ones).
This is exactly what you'd do if you were trying to sell everyone a laptop with AI on it.
With 128x compression English Wikipedia fits in 0.2 GB.
With 128x compression English Wikipedia fits in 0.2 GB.

Apple's CLaRa-7B-Instruct (Compression-16 & 128)
The CLaRa-7B-Instruct model is Apple's instruction-tuned unified RAG model with built-in semantic document compression (16× & 128x). It supports instruction-following QA directly from compressed document representations.
The CLaRa-7B-Instruct model is Apple's instruction-tuned unified RAG model with built-in semantic document compression (16× & 128x). It supports instruction-following QA directly from compressed document representations.

December 3, 2025 at 9:37 PM
This is exactly what you'd do if you were trying to sell everyone a laptop with AI on it.
With 128x compression English Wikipedia fits in 0.2 GB.
With 128x compression English Wikipedia fits in 0.2 GB.
Reposted by Sam Harsimony

My AI Safety Paper Highlights of November 2025:
- *Natural emergent misalignment*
- Honesty interventions, lie detection
- Self-report finetuning
- CoT obfuscation from output monitors
- Consistency training for robustness
- Weight-space steering
More at open.substack.com/pub/aisafety...
- *Natural emergent misalignment*
- Honesty interventions, lie detection
- Self-report finetuning
- CoT obfuscation from output monitors
- Consistency training for robustness
- Weight-space steering
More at open.substack.com/pub/aisafety...

Paper Highlights of November 2025
Natural emergent misalignment, honesty interventions, self-report finetuning, CoT obfuscation from output monitors, consistency training for robustness, and weight-space steering
open.substack.com
December 2, 2025 at 9:05 PM
My AI Safety Paper Highlights of November 2025:
- *Natural emergent misalignment*
- Honesty interventions, lie detection
- Self-report finetuning
- CoT obfuscation from output monitors
- Consistency training for robustness
- Weight-space steering
More at open.substack.com/pub/aisafety...
- *Natural emergent misalignment*
- Honesty interventions, lie detection
- Self-report finetuning
- CoT obfuscation from output monitors
- Consistency training for robustness
- Weight-space steering
More at open.substack.com/pub/aisafety...
Reposted by Sam Harsimony

Wow.
"It gives me no pleasure to say what I’m about to say because I worked with Pete Hegseth for seven or eight years at Fox News. This is an act of a war crime .... There’s absolutely no legal basis for it.”
- Newsmax's Judge Napolitano
"It gives me no pleasure to say what I’m about to say because I worked with Pete Hegseth for seven or eight years at Fox News. This is an act of a war crime .... There’s absolutely no legal basis for it.”
- Newsmax's Judge Napolitano

Woah. Newsmax’s legal analyst just said Pete Hegseth and everyone involved in the illegal boat strike should be “prosecuted for a war crime.”
They’ve even lost Newsmax on this one.
They’ve even lost Newsmax on this one.
December 3, 2025 at 2:06 AM
Wow.
"It gives me no pleasure to say what I’m about to say because I worked with Pete Hegseth for seven or eight years at Fox News. This is an act of a war crime .... There’s absolutely no legal basis for it.”
- Newsmax's Judge Napolitano
"It gives me no pleasure to say what I’m about to say because I worked with Pete Hegseth for seven or eight years at Fox News. This is an act of a war crime .... There’s absolutely no legal basis for it.”
- Newsmax's Judge Napolitano
More on the Pivotal eVTOL. Main barrier for use in cities new seems to be noise. At altitude it's not bad, but sounds like weed wackers at landing.
Larger propellers with optimized shape and soundproofed landing areas might work.
www.youtube.com/watch?v=oT80...
Larger propellers with optimized shape and soundproofed landing areas might work.
www.youtube.com/watch?v=oT80...

Going UP!!! Flying A VTOL For Real - Pivotal's Unique Take on Accessible Aviation
YouTube video by Scott Manley
www.youtube.com
December 2, 2025 at 8:04 PM
More on the Pivotal eVTOL. Main barrier for use in cities new seems to be noise. At altitude it's not bad, but sounds like weed wackers at landing.
Larger propellers with optimized shape and soundproofed landing areas might work.
www.youtube.com/watch?v=oT80...
Larger propellers with optimized shape and soundproofed landing areas might work.
www.youtube.com/watch?v=oT80...
You can run a 7B model on your laptop. Leading open-weight models are ~700B params.
People's hardware will get better and models of constant capability will shrink. Perhaps every laptop will run models with capability equal to today's frontier.
People's hardware will get better and models of constant capability will shrink. Perhaps every laptop will run models with capability equal to today's frontier.
December 2, 2025 at 6:25 PM
You can run a 7B model on your laptop. Leading open-weight models are ~700B params.
People's hardware will get better and models of constant capability will shrink. Perhaps every laptop will run models with capability equal to today's frontier.
People's hardware will get better and models of constant capability will shrink. Perhaps every laptop will run models with capability equal to today's frontier.
Reposted by Sam Harsimony

“I will die on the hill that population coding is the relevant level of encoding information in the brain.” In the latest “This paper changed my life,” Nancy Padilla-Coreano discusses a paper on mixed selectivity neurons.
#neuroskyence
www.thetransmitter.org/this-paper-c...
#neuroskyence
www.thetransmitter.org/this-paper-c...

This paper changed my life: Nancy Padilla-Coreano on learning the value of population coding
The 2013 Nature paper by Mattia Rigotti and his colleagues revealed how mixed selectivity neurons—cells that are not selectively tuned to a stimulus—play a key role in cognition.
www.thetransmitter.org
December 1, 2025 at 2:23 PM
“I will die on the hill that population coding is the relevant level of encoding information in the brain.” In the latest “This paper changed my life,” Nancy Padilla-Coreano discusses a paper on mixed selectivity neurons.
#neuroskyence
www.thetransmitter.org/this-paper-c...
#neuroskyence
www.thetransmitter.org/this-paper-c...
Reposted by Sam Harsimony

DeepSeek released V3.2 (and V3.2 Speciale, a math-oriented model).
New model, new benchmarks!
The biggest jump for DeepSeek V3.2 is on agentic coding, where it seems poised to erase a lot of models on the Pareto frontier, including Sonnet 4.5, Minimax M2, and K2 Thinking.
New model, new benchmarks!
The biggest jump for DeepSeek V3.2 is on agentic coding, where it seems poised to erase a lot of models on the Pareto frontier, including Sonnet 4.5, Minimax M2, and K2 Thinking.

December 1, 2025 at 6:28 PM
DeepSeek released V3.2 (and V3.2 Speciale, a math-oriented model).
New model, new benchmarks!
The biggest jump for DeepSeek V3.2 is on agentic coding, where it seems poised to erase a lot of models on the Pareto frontier, including Sonnet 4.5, Minimax M2, and K2 Thinking.
New model, new benchmarks!
The biggest jump for DeepSeek V3.2 is on agentic coding, where it seems poised to erase a lot of models on the Pareto frontier, including Sonnet 4.5, Minimax M2, and K2 Thinking.
Brain emulation is quietly getting better. Important to keep an eye on.
arxiv.org/abs/2510.15745
arxiv.org/abs/2510.15745

State of Brain Emulation Report 2025
The State of Brain Emulation Report 2025 provides a comprehensive reassessment of the field's progress since Sandberg and Bostrom's 2008 Whole Brain Emulation roadmap. The report is organized around t...
arxiv.org
November 30, 2025 at 4:25 PM
Brain emulation is quietly getting better. Important to keep an eye on.
arxiv.org/abs/2510.15745
arxiv.org/abs/2510.15745
Reposted by Sam Harsimony

Just when I put out a linkpost Tensor Economics blog puts up another Banger.
Appears to be a more rigorous look at RL-as-a-Service, among other things
www.tensoreconomics.com/p/ai-infrast...
Appears to be a more rigorous look at RL-as-a-Service, among other things
www.tensoreconomics.com/p/ai-infrast...

AI infrastructure in the "Era of experience"
Intelligence involution, economies of scale in RL, everything async and multi-turn.
www.tensoreconomics.com
November 26, 2025 at 9:44 PM
Just when I put out a linkpost Tensor Economics blog puts up another Banger.
Appears to be a more rigorous look at RL-as-a-Service, among other things
www.tensoreconomics.com/p/ai-infrast...
Appears to be a more rigorous look at RL-as-a-Service, among other things
www.tensoreconomics.com/p/ai-infrast...
Evidence for my view that next phase of AI is drilling down on different domains. This is The Way.
bsky.app/profile/hars...
bsky.app/profile/hars...

Gemini 3 Pro set a new record on GPQA Diamond: 93% vs. the previous record of 88%. What you can’t tell from the headline: almost all of this gain came in organic chemistry. 🧬🧵

November 26, 2025 at 3:46 PM
Evidence for my view that next phase of AI is drilling down on different domains. This is The Way.
bsky.app/profile/hars...
bsky.app/profile/hars...
Hopefully the left will return to being the party of progress and liberalism will mean classical liberalism again.

Learning that Annemarie Gray (no relation) of Open New York, NYC's YIMBY group, has been appointed to Mayor-elect Mamdani's housing transition team. This is FANTASTIC news!

November 24, 2025 at 11:25 PM
Hopefully the left will return to being the party of progress and liberalism will mean classical liberalism again.
I'm not familiar with this field/debate but it seems to me that in the absence of evidence we should study (and try to falsify) the simplest hypothesis. "Only spikes matter" seems like a simple hypothesis. Shouldn't it be the default?

As we are having a discussion on neural codes: @earlkmiller.bsky.social is entirely right that the "only spike rates matter" idea that is so prominent in neuroscience has no credible evidence. We simply do not currently know how neurons code relevant information. Oscillations are likely part of it.
November 24, 2025 at 11:17 PM
I'm not familiar with this field/debate but it seems to me that in the absence of evidence we should study (and try to falsify) the simplest hypothesis. "Only spikes matter" seems like a simple hypothesis. Shouldn't it be the default?
They only get 500 Wh/kg in ideal conditions, but still crazy good. Increases the range of flying cars by ~2x.
If this scales, no technical barriers to flying for your daily commute.
www.youtube.com/watch?v=P4rZ...
If this scales, no technical barriers to flying for your daily commute.
www.youtube.com/watch?v=P4rZ...

CATL’s 500 Wh/kg Golden Battery Is Official — What You Need to Know
YouTube video by Ben Alexxander
www.youtube.com
November 24, 2025 at 6:25 PM
They only get 500 Wh/kg in ideal conditions, but still crazy good. Increases the range of flying cars by ~2x.
If this scales, no technical barriers to flying for your daily commute.
www.youtube.com/watch?v=P4rZ...
If this scales, no technical barriers to flying for your daily commute.
www.youtube.com/watch?v=P4rZ...
@danabra.mov states this vision more clearly than I:
overreacted.io/open-social/
I'd add that cryptography and LLM's compliment these ideas a lot.
overreacted.io/open-social/
I'd add that cryptography and LLM's compliment these ideas a lot.
November 24, 2025 at 5:17 PM
@danabra.mov states this vision more clearly than I:
overreacted.io/open-social/
I'd add that cryptography and LLM's compliment these ideas a lot.
overreacted.io/open-social/
I'd add that cryptography and LLM's compliment these ideas a lot.
LLM's can already code up basic websites. Look to the future and they become a universal interface; stream any data in any format to your screen.
That changes something fundamental about how we use the internet ...
That changes something fundamental about how we use the internet ...

once we get the culture to figure out that atproto means you can adopt new apps without selling your soul to their creators we're going to see an *explosion* of new (and old!) forms of doing shit together on the internet
it's insane how we've been held back by feudal technocratic architectures
it's insane how we've been held back by feudal technocratic architectures
November 23, 2025 at 7:49 PM
LLM's can already code up basic websites. Look to the future and they become a universal interface; stream any data in any format to your screen.
That changes something fundamental about how we use the internet ...
That changes something fundamental about how we use the internet ...
Reposted by Sam Harsimony

anyways, if you're disillusioned by Bernie's increasing red-brownism, there's a place for you in LGBTESCREAL, where our position on borders is that they are generally bad and we should have fewer of them

Elon Musk is wrong.
The main function of the H-1B visa program is not to hire “the best and the brightest,” but rather to replace good-paying American jobs with low-wage indentured servants from abroad.
The cheaper the labor they hire, the more money the billionaires make.
The main function of the H-1B visa program is not to hire “the best and the brightest,” but rather to replace good-paying American jobs with low-wage indentured servants from abroad.
The cheaper the labor they hire, the more money the billionaires make.



January 3, 2025 at 12:10 AM
anyways, if you're disillusioned by Bernie's increasing red-brownism, there's a place for you in LGBTESCREAL, where our position on borders is that they are generally bad and we should have fewer of them
This is a really excellent find.
Set aside your judgement and read the blogpost as being purely about how dating apps work. You can learn so much about people!
Set aside your judgement and read the blogpost as being purely about how dating apps work. You can learn so much about people!

Someone pointed me to this post from someone supposedly working on a dating app. I think you'll find that it confirms most of your suspicions...
blog.luap.info/what-really-...
blog.luap.info/what-really-...
November 22, 2025 at 8:05 PM
This is a really excellent find.
Set aside your judgement and read the blogpost as being purely about how dating apps work. You can learn so much about people!
Set aside your judgement and read the blogpost as being purely about how dating apps work. You can learn so much about people!
I'd guess that e-beams are the economic limit* of our ability to make computer chips.
Eventually the semiconductor industry will reach the end of history and that will have implications for ~everything.
Eventually the semiconductor industry will reach the end of history and that will have implications for ~everything.

2 nanometer feature size and 5 nanometer half-pitch resolution with electron-beam lithography using 200 keV+ with aberration correction:
pubs.acs.org/doi/10.1021/...
EB-induced deposition can achieve similar resolution but it's 1000x slower than direct EB lithography.
pubs.acs.org/doi/10.1021/...
EB-induced deposition can achieve similar resolution but it's 1000x slower than direct EB lithography.


November 22, 2025 at 5:18 PM
I'd guess that e-beams are the economic limit* of our ability to make computer chips.
Eventually the semiconductor industry will reach the end of history and that will have implications for ~everything.
Eventually the semiconductor industry will reach the end of history and that will have implications for ~everything.

Reposted by Sam Harsimony

Introducing 🥚EGGROLL 🥚(Evolution Guided General Optimization via Low-rank Learning)! 🚀 Scaling backprop-free Evolution Strategies (ES) for billion-parameter models at large population sizes
⚡100x Training Throughput
🎯Fast Convergence
🔢Pure Int8 Pretraining of RNN LLMs
⚡100x Training Throughput
🎯Fast Convergence
🔢Pure Int8 Pretraining of RNN LLMs

November 21, 2025 at 5:56 PM
Introducing 🥚EGGROLL 🥚(Evolution Guided General Optimization via Low-rank Learning)! 🚀 Scaling backprop-free Evolution Strategies (ES) for billion-parameter models at large population sizes
⚡100x Training Throughput
🎯Fast Convergence
🔢Pure Int8 Pretraining of RNN LLMs
⚡100x Training Throughput
🎯Fast Convergence
🔢Pure Int8 Pretraining of RNN LLMs
Reposted by Sam Harsimony

The future is going to be very jaggedly distributed. Flat frictionless software generating spherical cows at exponentially increasing rates while we poke around the robo greenhouse trying to figure out how algae keeps getting into the irrigation lines.

Analytical chemistry has become extremely automated in the last 25 years, and yet shit continues to break in new and befuddling ways that AI can’t possibly parse. The “datasets” for it to learn instrument repairs from exist in the minds of experts and are significantly vibes-based.

A fair question is how much of a day's work could be outsourced to a machine? As I've become proficient with AI tools, I find that much of what takes me time (but not deep cognitive effort) can be automated. PhDs are hired, at least in part, for their thinking skills. Not all jobs require them.
November 20, 2025 at 5:59 AM
The future is going to be very jaggedly distributed. Flat frictionless software generating spherical cows at exponentially increasing rates while we poke around the robo greenhouse trying to figure out how algae keeps getting into the irrigation lines.
Reposted by Sam Harsimony

We present Olmo 3, our next family of fully open, leading language models.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.


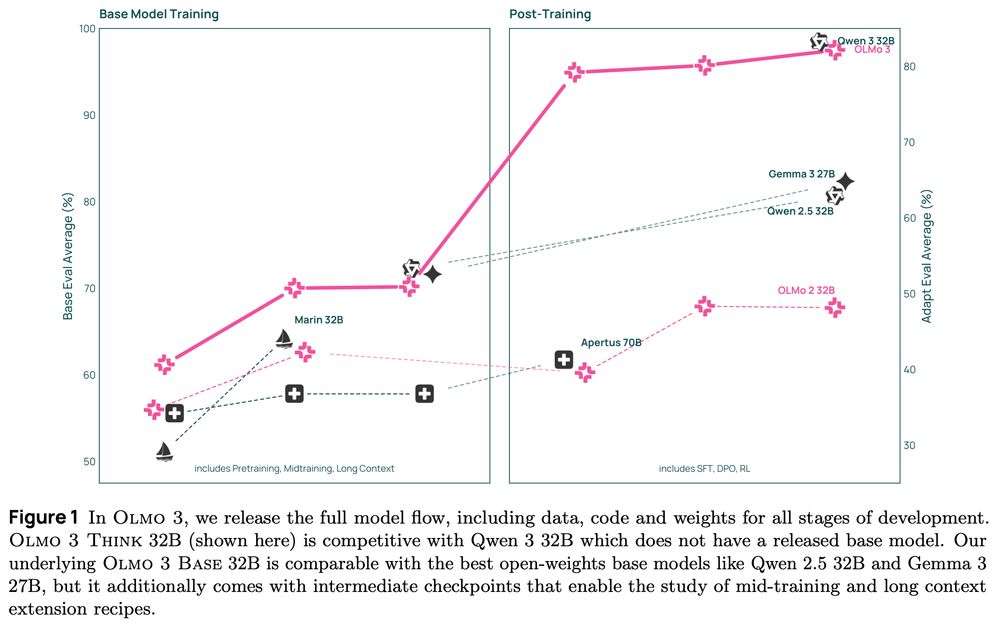
November 20, 2025 at 2:32 PM
We present Olmo 3, our next family of fully open, leading language models.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
Good point. Repeating my comment here:
(link from the end: www.sympatheticopposition.com/p/hyperstimu...)
(link from the end: www.sympatheticopposition.com/p/hyperstimu...)

November 20, 2025 at 5:58 PM
Good point. Repeating my comment here:
(link from the end: www.sympatheticopposition.com/p/hyperstimu...)
(link from the end: www.sympatheticopposition.com/p/hyperstimu...)