
Jacob Morrison
@jacobcares.bsky.social
540 followers
380 following
12 posts
PhD student @ UW, research @ Ai2
Posts
Media
Videos
Starter Packs
Reposted by Jacob Morrison




Reposted by Jacob Morrison


Reposted by Jacob Morrison



Jacob Morrison
@jacobcares.bsky.social
· Apr 28
Reposted by Jacob Morrison

Jacob Morrison
@jacobcares.bsky.social
· Apr 26
Jacob Morrison
@jacobcares.bsky.social
· Apr 23

Holistically Evaluating the Environmental Impact of Creating Language Models
As the performance of artificial intelligence systems has dramatically increased, so too has the environmental impact of creating these systems. While many model developers release estimates of the po...
arxiv.org
Jacob Morrison
@jacobcares.bsky.social
· Apr 23
Reposted by Jacob Morrison
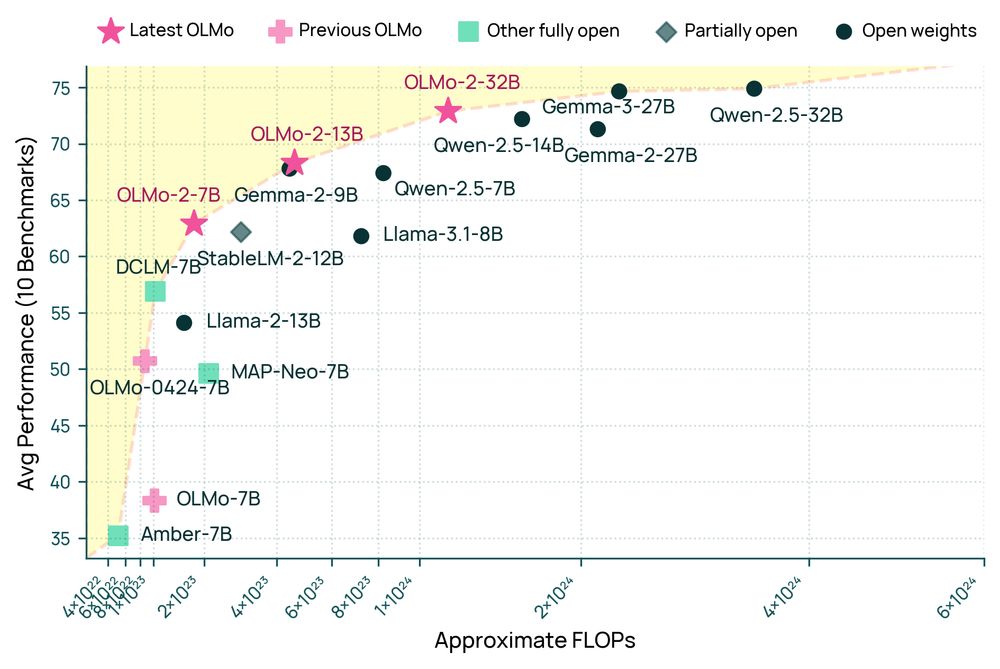
Reposted by Jacob Morrison


Jacob Morrison
@jacobcares.bsky.social
· Jan 30
Jacob Morrison
@jacobcares.bsky.social
· Jan 30

Reposted by Jacob Morrison
Reposted by Jacob Morrison


Reposted by Jacob Morrison
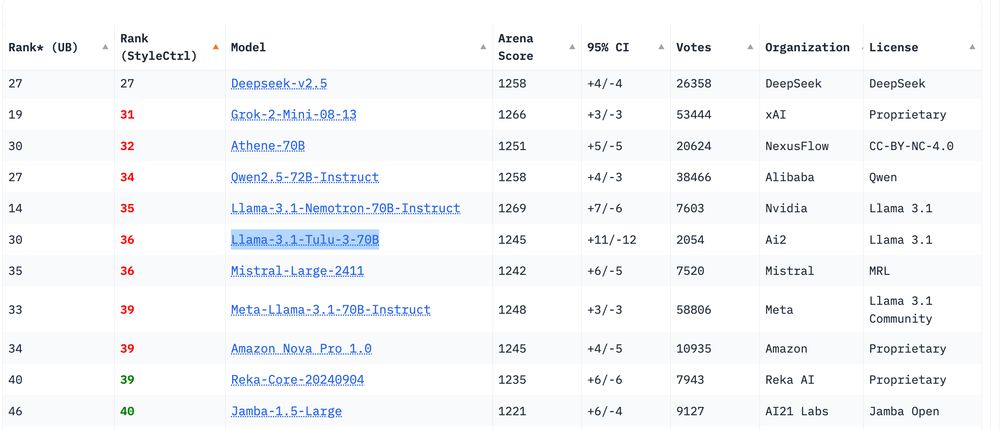
Reposted by Jacob Morrison

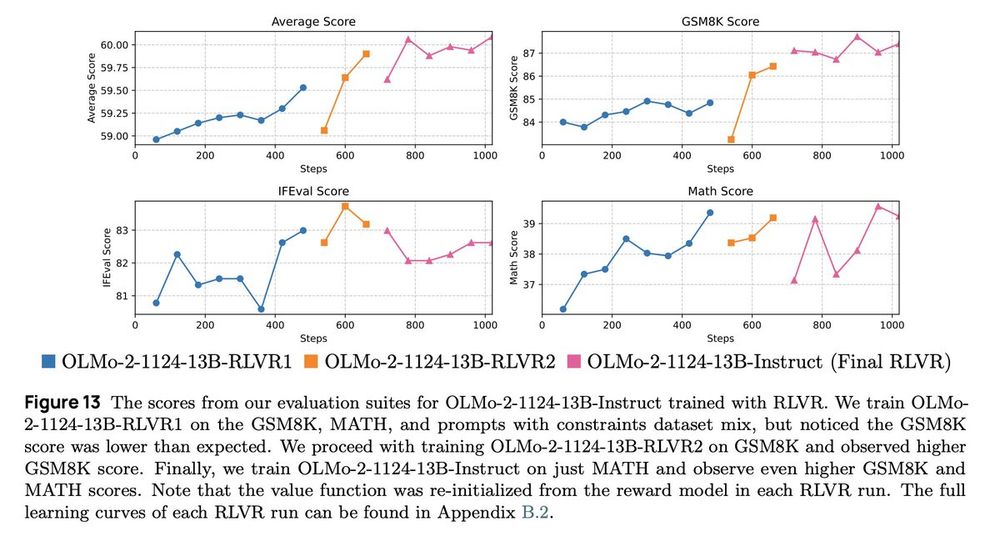
Reposted by Jacob Morrison


Reposted by Jacob Morrison

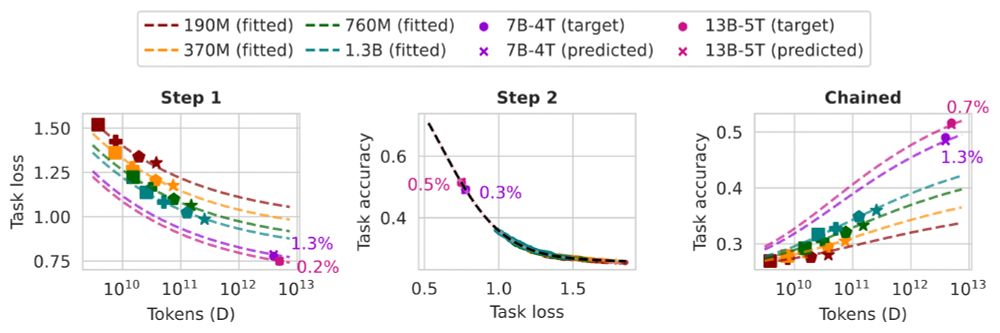
Reposted by Jacob Morrison

Reposted by Jacob Morrison

Luca Soldaini 🎀
@soldaini.net
· Nov 26

Reposted by Jacob Morrison
Jacob Morrison
@jacobcares.bsky.social
· Nov 21