




Jacob Morrison
@jacobcares.bsky.social
PhD student @ UW, research @ Ai2
Reposted by Jacob Morrison

Forget modeling every belief and goal! What if we represented people as following simple scripts instead (i.e "cross the crosswalk")?
Our new paper shows AI which models others’ minds as Python code 💻 can quickly and accurately predict human behavior!
shorturl.at/siUYI%F0%9F%...
Our new paper shows AI which models others’ minds as Python code 💻 can quickly and accurately predict human behavior!
shorturl.at/siUYI%F0%9F%...

October 3, 2025 at 2:24 AM
Forget modeling every belief and goal! What if we represented people as following simple scripts instead (i.e "cross the crosswalk")?
Our new paper shows AI which models others’ minds as Python code 💻 can quickly and accurately predict human behavior!
shorturl.at/siUYI%F0%9F%...
Our new paper shows AI which models others’ minds as Python code 💻 can quickly and accurately predict human behavior!
shorturl.at/siUYI%F0%9F%...
Reposted by Jacob Morrison

Thank you to co-authors @natolambert.bsky.social, @valentinapy.bsky.social, @jacobcares.bsky.social, Sander Land, @nlpnoah.bsky.social, @hanna-nlp.bsky.social!
Read more in the paper here (ArXiv soon!): github.com/allenai/rewa...
Dataset, leaderboard, and models here: huggingface.co/collections/...
Read more in the paper here (ArXiv soon!): github.com/allenai/rewa...
Dataset, leaderboard, and models here: huggingface.co/collections/...

Reward Bench 2 - a allenai Collection
Datasets, spaces, and models for Reward Bench 2 benchmark and paper!
huggingface.co
June 2, 2025 at 11:41 PM
Thank you to co-authors @natolambert.bsky.social, @valentinapy.bsky.social, @jacobcares.bsky.social, Sander Land, @nlpnoah.bsky.social, @hanna-nlp.bsky.social!
Read more in the paper here (ArXiv soon!): github.com/allenai/rewa...
Dataset, leaderboard, and models here: huggingface.co/collections/...
Read more in the paper here (ArXiv soon!): github.com/allenai/rewa...
Dataset, leaderboard, and models here: huggingface.co/collections/...
Reposted by Jacob Morrison

RewardBench 2 is here! We took a long time to learn from our first reward model evaluation tool to make one that is substantially harder and more correlated with both downstream RLHF and inference-time scaling.

June 2, 2025 at 4:31 PM
RewardBench 2 is here! We took a long time to learn from our first reward model evaluation tool to make one that is substantially harder and more correlated with both downstream RLHF and inference-time scaling.
Reposted by Jacob Morrison

Heading to NAACL? With "verification being the key to AI" you should go to the poster session Friday, 9-10:30am to chat with my star colleagues @valentinapy.bsky.social + @jacobcares.bsky.social about RewardBench (and really RewardBench 2, evaluation, and reward models in post-training).

April 29, 2025 at 4:07 PM
Heading to NAACL? With "verification being the key to AI" you should go to the poster session Friday, 9-10:30am to chat with my star colleagues @valentinapy.bsky.social + @jacobcares.bsky.social about RewardBench (and really RewardBench 2, evaluation, and reward models in post-training).
Valentina and I will be presenting RewardBench at NAACL! Come say hi at the poster session on Friday and we can chat about reward models, staying up for 30 hours straight to rapidly reset from Singapore time, and more 🏜️
I'll be at #NAACL2025:
🖇️To present my paper "Superlatives in Context", showing how the interpretation of superlatives is very context dependent and often implicit, and how LLMs handle such semantic underspecification
🖇️And we will present RewardBench on Friday
Reach out if you want to chat!
🖇️To present my paper "Superlatives in Context", showing how the interpretation of superlatives is very context dependent and often implicit, and how LLMs handle such semantic underspecification
🖇️And we will present RewardBench on Friday
Reach out if you want to chat!
April 28, 2025 at 3:15 PM
Valentina and I will be presenting RewardBench at NAACL! Come say hi at the poster session on Friday and we can chat about reward models, staying up for 30 hours straight to rapidly reset from Singapore time, and more 🏜️
Reposted by Jacob Morrison

I'll be at #NAACL2025:
🖇️To present my paper "Superlatives in Context", showing how the interpretation of superlatives is very context dependent and often implicit, and how LLMs handle such semantic underspecification
🖇️And we will present RewardBench on Friday
Reach out if you want to chat!
🖇️To present my paper "Superlatives in Context", showing how the interpretation of superlatives is very context dependent and often implicit, and how LLMs handle such semantic underspecification
🖇️And we will present RewardBench on Friday
Reach out if you want to chat!
April 27, 2025 at 8:00 PM
I'll be at #NAACL2025:
🖇️To present my paper "Superlatives in Context", showing how the interpretation of superlatives is very context dependent and often implicit, and how LLMs handle such semantic underspecification
🖇️And we will present RewardBench on Friday
Reach out if you want to chat!
🖇️To present my paper "Superlatives in Context", showing how the interpretation of superlatives is very context dependent and often implicit, and how LLMs handle such semantic underspecification
🖇️And we will present RewardBench on Friday
Reach out if you want to chat!
I'm in Singapore for @iclr-conf.bsky.social ! Come check out our spotlight paper on the environmental impact of training OLMo (link in next tweet) during the Saturday morning poster session from 10-12:30 -- happy to chat about this or anything else! DMs should be open, email works too
April 23, 2025 at 3:22 PM
I'm in Singapore for @iclr-conf.bsky.social ! Come check out our spotlight paper on the environmental impact of training OLMo (link in next tweet) during the Saturday morning poster session from 10-12:30 -- happy to chat about this or anything else! DMs should be open, email works too
Reposted by Jacob Morrison
Announcing OLMo 2 32B: the first fully open model to beat GPT 3.5 & GPT-4o mini on a suite of popular, multi-skill benchmarks.
Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!
Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!
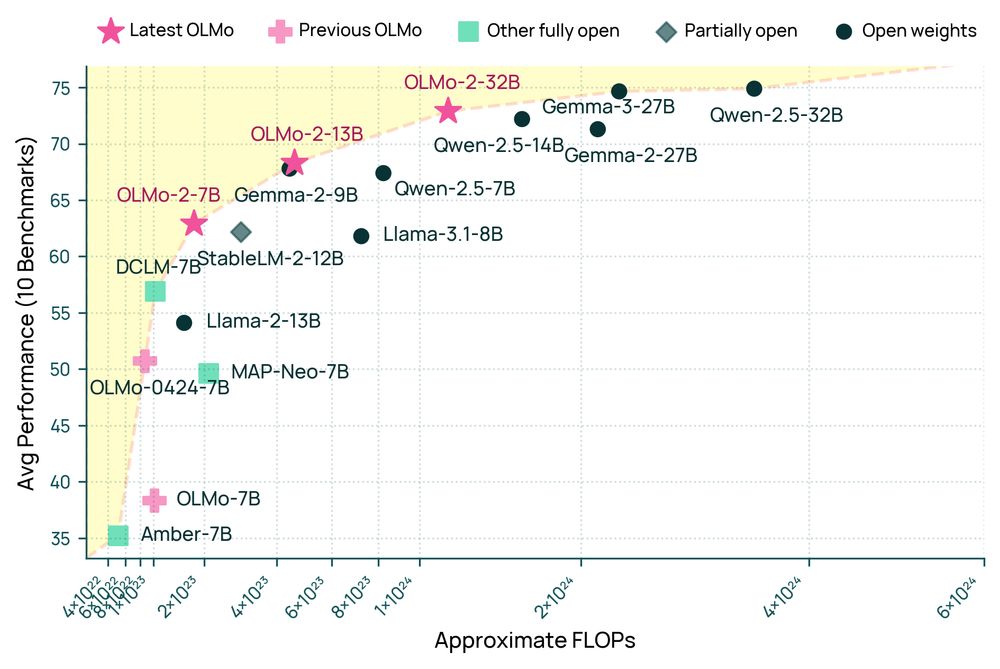
March 13, 2025 at 6:36 PM
Announcing OLMo 2 32B: the first fully open model to beat GPT 3.5 & GPT-4o mini on a suite of popular, multi-skill benchmarks.
Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!
Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!
Reposted by Jacob Morrison

There are no proven benefits to raw feeding yet plenty of serious, well-documented risks. It has never been a good idea but ESPECIALLY NOW. washingtonstatestandard.com/briefs/two-w...

Two Washington cats infected with bird flu • Washington State Standard
Two domestic cats in Washington state have been infected with bird flu after eating raw pet food, according to the department of agriculture.
washingtonstatestandard.com
February 26, 2025 at 11:36 PM
There are no proven benefits to raw feeding yet plenty of serious, well-documented risks. It has never been a good idea but ESPECIALLY NOW. washingtonstatestandard.com/briefs/two-w...
big tülu is here! can't wait for everyone to try it, it's been a lot of fun seeing how RL performs at this scale thanks to @hamishivi.bsky.social
and @vwxyzjn.bsky.social, and preference data from @ljvmiranda.bsky.social
on an unrelated note, I'm applying to phd programs this year 👀
and @vwxyzjn.bsky.social, and preference data from @ljvmiranda.bsky.social
on an unrelated note, I'm applying to phd programs this year 👀
Here is Tülu 3 405B 🐫 our open-source post-training model that surpasses the performance of DeepSeek-V3! It demonstrates that our recipe, which includes RVLR scales to 405B - with performance on par with GPT-4o, & surpassing prior open-weight post-trained models of the same size including Llama 3.1.

January 30, 2025 at 7:25 PM
big tülu is here! can't wait for everyone to try it, it's been a lot of fun seeing how RL performs at this scale thanks to @hamishivi.bsky.social
and @vwxyzjn.bsky.social, and preference data from @ljvmiranda.bsky.social
on an unrelated note, I'm applying to phd programs this year 👀
and @vwxyzjn.bsky.social, and preference data from @ljvmiranda.bsky.social
on an unrelated note, I'm applying to phd programs this year 👀
Reposted by Jacob Morrison
Here is Tülu 3 405B 🐫 our open-source post-training model that surpasses the performance of DeepSeek-V3! It demonstrates that our recipe, which includes RVLR scales to 405B - with performance on par with GPT-4o, & surpassing prior open-weight post-trained models of the same size including Llama 3.1.
January 30, 2025 at 2:28 PM
Here is Tülu 3 405B 🐫 our open-source post-training model that surpasses the performance of DeepSeek-V3! It demonstrates that our recipe, which includes RVLR scales to 405B - with performance on par with GPT-4o, & surpassing prior open-weight post-trained models of the same size including Llama 3.1.
Reposted by Jacob Morrison

Excited to see Tulu 3 sits in between Llama 3.1 and 3.3 instruct on the chatbot arena leaderboard right now!
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124

January 8, 2025 at 5:47 PM
Excited to see Tulu 3 sits in between Llama 3.1 and 3.3 instruct on the chatbot arena leaderboard right now!
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
Reposted by Jacob Morrison
Very pleased to see Tulu 3 70B more or less tied with Llama 3.1 70B Instruct on style controlled ChatBotArena. The only model anywhere close to that with open code and data for post-training! Lots of stuff people can build on.
Next looking for OLMo 2 numbers.
Next looking for OLMo 2 numbers.
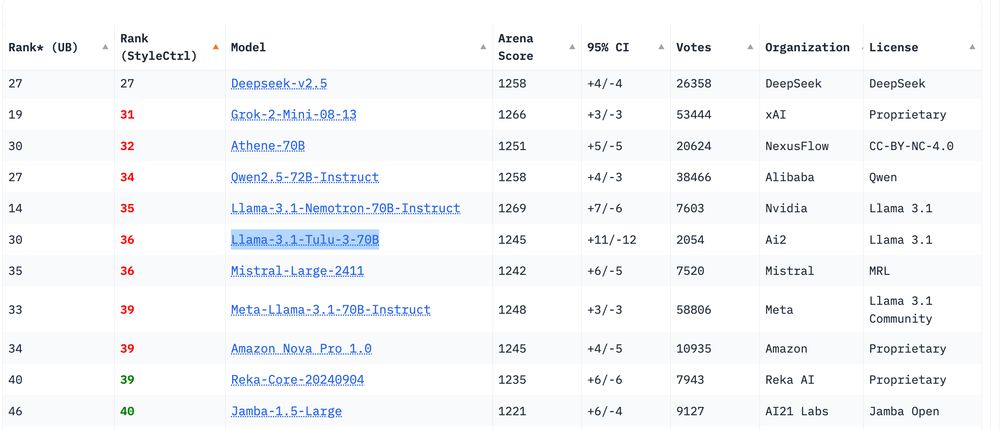
January 8, 2025 at 5:13 PM
Very pleased to see Tulu 3 70B more or less tied with Llama 3.1 70B Instruct on style controlled ChatBotArena. The only model anywhere close to that with open code and data for post-training! Lots of stuff people can build on.
Next looking for OLMo 2 numbers.
Next looking for OLMo 2 numbers.
Reposted by Jacob Morrison

We released the OLMo 2 report! Ready for some more RL curves? 😏
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
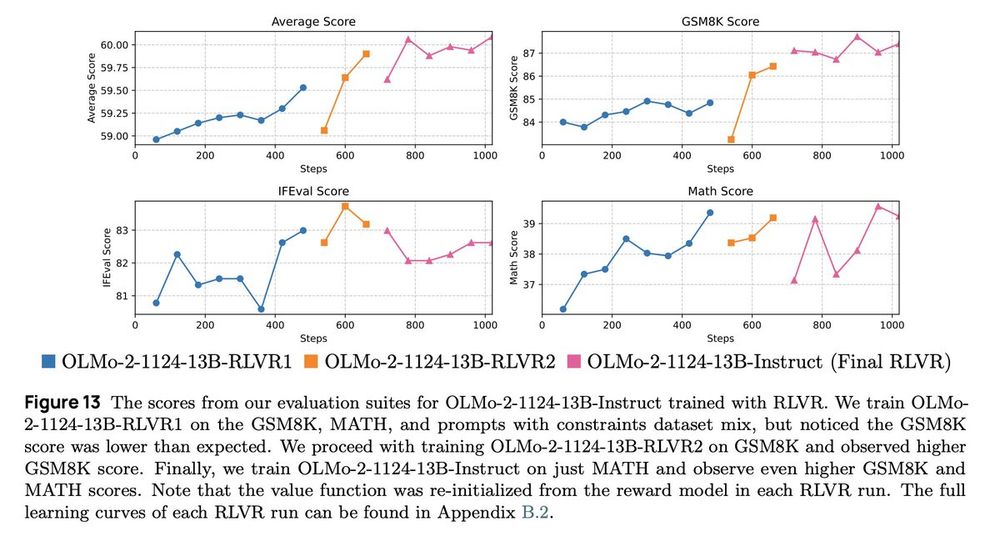
January 6, 2025 at 6:34 PM
We released the OLMo 2 report! Ready for some more RL curves? 😏
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
Reposted by Jacob Morrison

kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵

January 3, 2025 at 4:02 PM
kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
Reposted by Jacob Morrison

Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
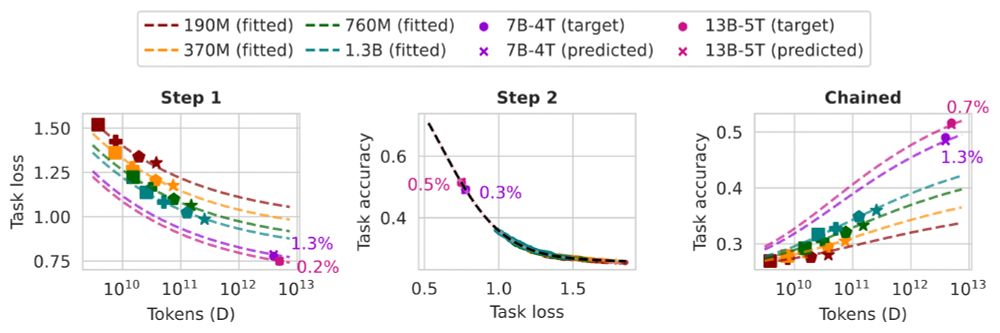
December 9, 2024 at 5:07 PM
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
Reposted by Jacob Morrison

Why is Tokyo so fashionable? Some theories. 🧵
November 27, 2024 at 6:43 AM
Why is Tokyo so fashionable? Some theories. 🧵
Reposted by Jacob Morrison

OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
November 26, 2024 at 9:12 PM
OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social

Reposted by Jacob Morrison
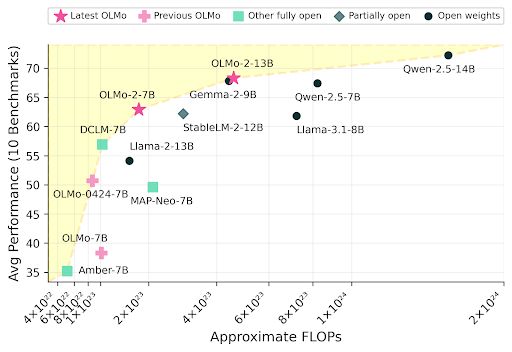
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
November 26, 2024 at 8:51 PM
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
Reposted by Jacob Morrison
yeah language models are great, but which Tulu 3 are you
- brat tulu, a @jacobcares.bsky.social favorite
- PNW tulu, don’t forget where @ai2.bsky.social is from
- dank tulu 💪
- tulu at tulu, bc tulu means sunrise in farsi
- brat tulu, a @jacobcares.bsky.social favorite
- PNW tulu, don’t forget where @ai2.bsky.social is from
- dank tulu 💪
- tulu at tulu, bc tulu means sunrise in farsi




November 21, 2024 at 9:59 PM
yeah language models are great, but which Tulu 3 are you
- brat tulu, a @jacobcares.bsky.social favorite
- PNW tulu, don’t forget where @ai2.bsky.social is from
- dank tulu 💪
- tulu at tulu, bc tulu means sunrise in farsi
- brat tulu, a @jacobcares.bsky.social favorite
- PNW tulu, don’t forget where @ai2.bsky.social is from
- dank tulu 💪
- tulu at tulu, bc tulu means sunrise in farsi
Reposted by Jacob Morrison
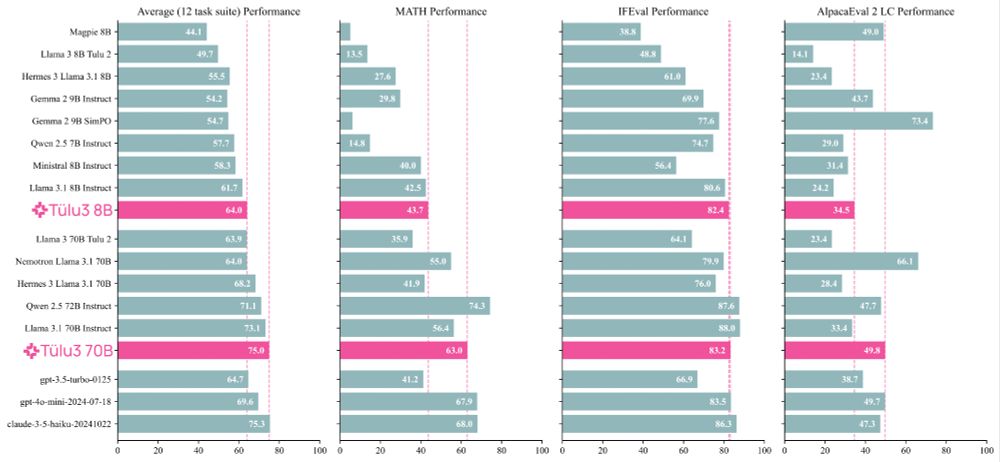
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
November 21, 2024 at 5:15 PM
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
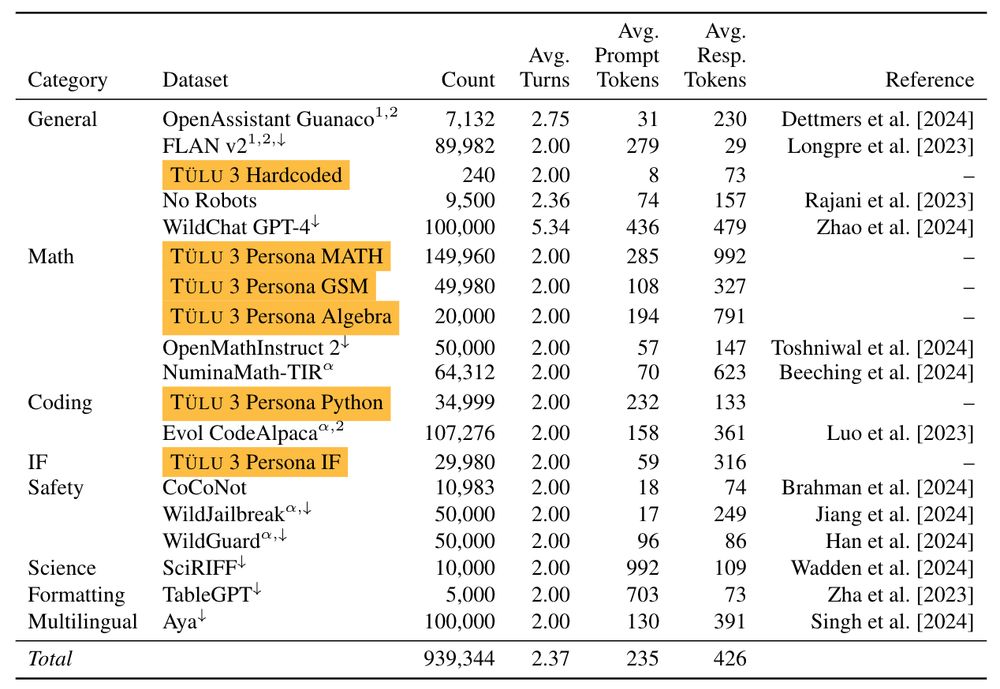
I'm so excited that we're finally releasing Tülu 3, our new post-training recipe! We're releasing models built on top of Llama 3.1 base (OLMo coming soon!), all of our datasets, a (73 page!) paper, new evaluations, and all of our code.

November 21, 2024 at 7:33 PM
I'm so excited that we're finally releasing Tülu 3, our new post-training recipe! We're releasing models built on top of Llama 3.1 base (OLMo coming soon!), all of our datasets, a (73 page!) paper, new evaluations, and all of our code.
Reposted by Jacob Morrison
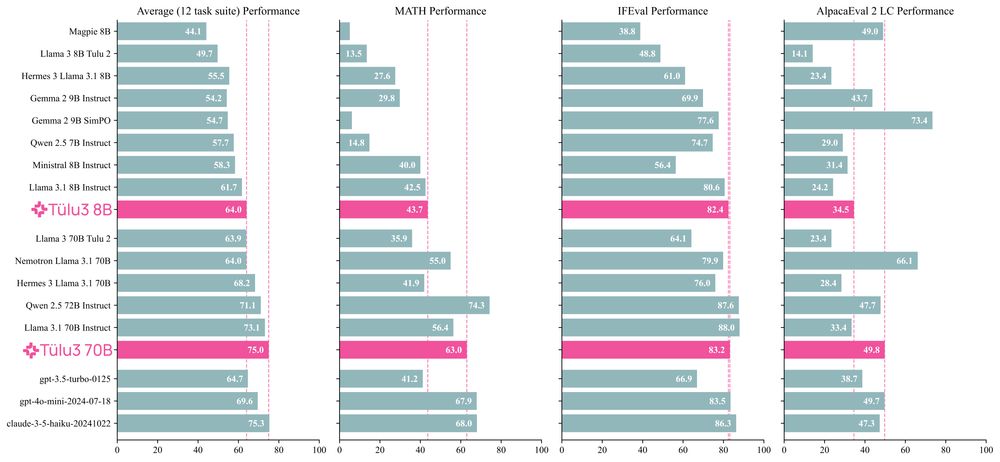
I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
Thread.
November 21, 2024 at 5:01 PM
I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
Thread.