Jesse Geerts
@jessegeerts.bsky.social
86 followers
55 following
14 posts
Cognitive neuroscientist and AI researcher
Posts
Media
Videos
Starter Packs
Pinned

Jesse Geerts
@jessegeerts.bsky.social
· Jun 6
Reposted by Jesse Geerts


Reposted by Jesse Geerts


Reposted by Jesse Geerts

Reposted by Jesse Geerts

Ching Fang
@chingfang.bsky.social
· Jun 26

From memories to maps: Mechanisms of in context reinforcement learning in transformers
Humans and animals show remarkable learning efficiency, adapting to new environments with minimal experience. This capability is not well captured by standard reinforcement learning algorithms that re...
arxiv.org
Jesse Geerts
@jessegeerts.bsky.social
· Jun 17
Reposted by Jesse Geerts



Jesse Geerts
@jessegeerts.bsky.social
· Jun 6

Reposted by Jesse Geerts

Andrew MacAskill
@macaskillaf.bsky.social
· May 29
Jesse Geerts
@jessegeerts.bsky.social
· Jun 6

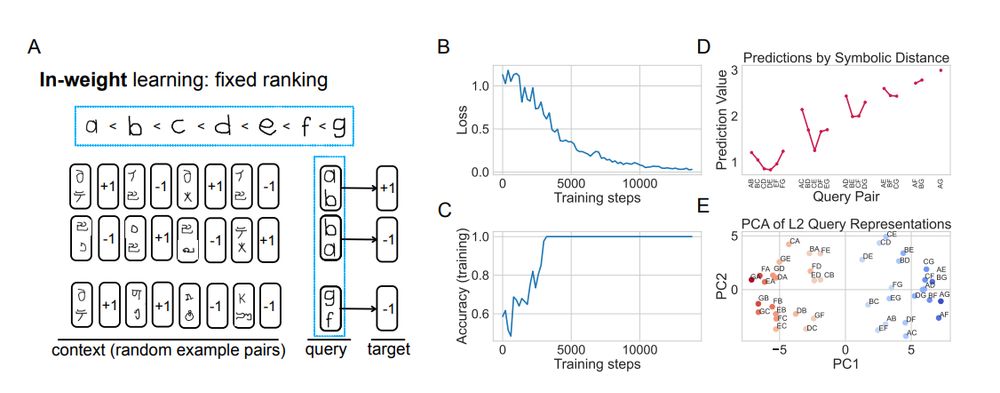
Relational reasoning and inductive bias in transformers trained on a transitive inference task
Transformer-based models have demonstrated remarkable reasoning abilities, but the mechanisms underlying relational reasoning in different learning regimes remain poorly understood. In this work, we i...
arxiv.org
Jesse Geerts
@jessegeerts.bsky.social
· Jun 6
Jesse Geerts
@jessegeerts.bsky.social
· Jun 6
Jesse Geerts
@jessegeerts.bsky.social
· Jun 6



Jesse Geerts
@jessegeerts.bsky.social
· Jun 6
Jesse Geerts
@jessegeerts.bsky.social
· Jun 6
Jesse Geerts
@jessegeerts.bsky.social
· Jun 6
Hugo Spiers
@hugospiers.bsky.social
· May 15
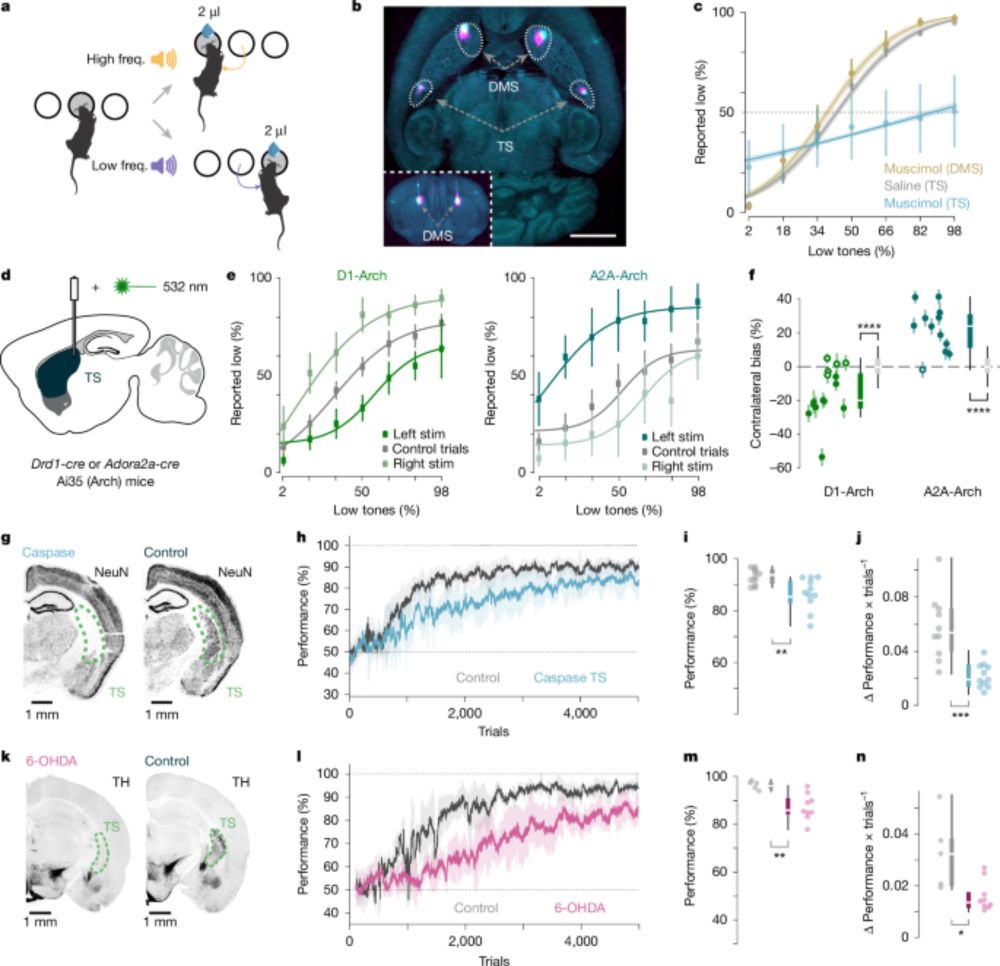
Dopaminergic action prediction errors serve as a value-free teaching signal - Nature
Dopaminergic action prediction error signals are used by mice as a value-free teaching signal to reinforce stable sound–action associations in the tail of the striatum.
www.nature.com
Reposted by Jesse Geerts
Hugo Spiers
@hugospiers.bsky.social
· May 15
Dopaminergic action prediction errors serve as a value-free teaching signal - Nature
Dopaminergic action prediction error signals are used by mice as a value-free teaching signal to reinforce stable sound–action associations in the tail of the striatum.
www.nature.com