Posts
Media
Videos
Starter Packs
Reposted by Alexander Kolesnikov


Alexander Kolesnikov
@kolesnikov.ch
· Dec 21

Knowledge distillation: A good teacher is patient and consistent
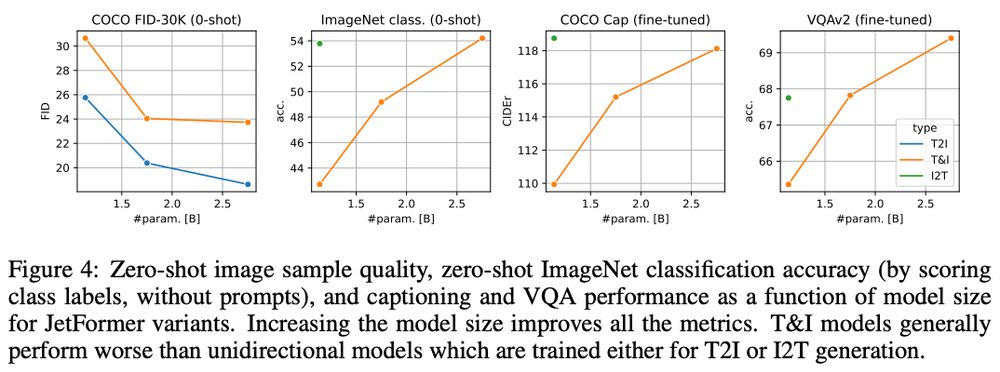
There is a growing discrepancy in computer vision between large-scale models that achieve state-of-the-art performance and models that are affordable in practical applications. In this paper we addres...
arxiv.org
Alexander Kolesnikov
@kolesnikov.ch
· Dec 21
Alexander Kolesnikov
@kolesnikov.ch
· Dec 20

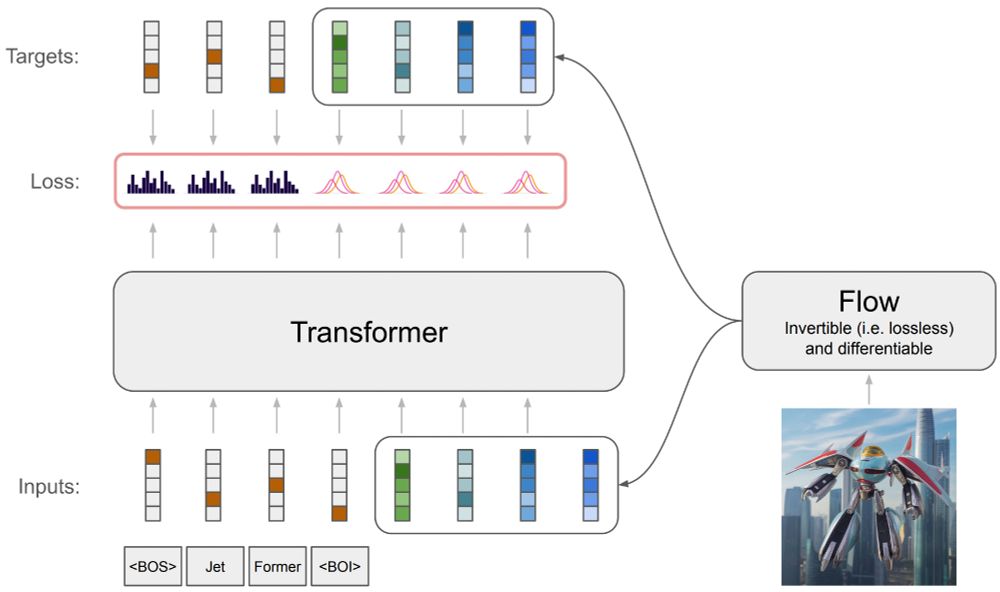
Alexander Kolesnikov
@kolesnikov.ch
· Dec 20

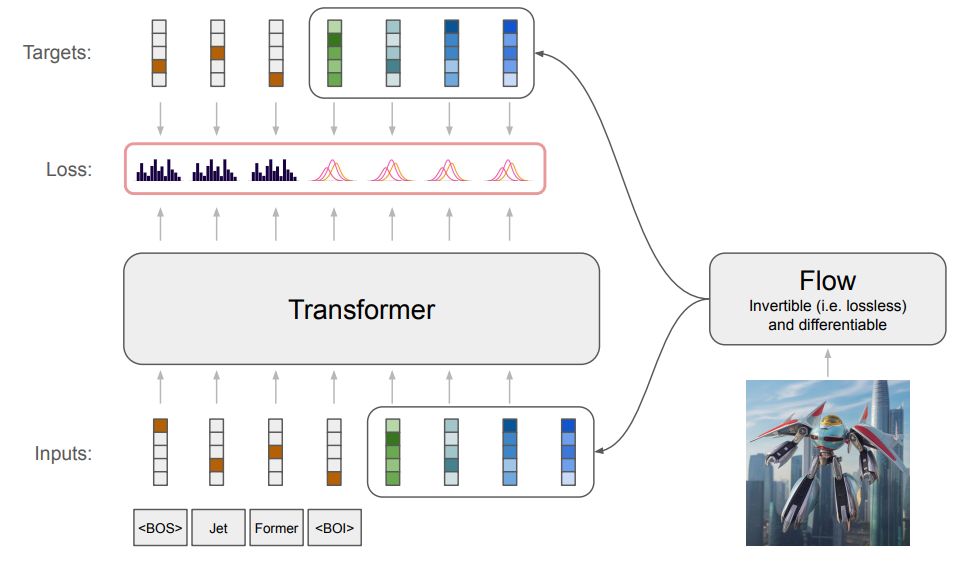
Jet: A Modern Transformer-Based Normalizing Flow
In the past, normalizing generative flows have emerged as a promising class of generative models for natural images. This type of model has many modeling advantages: the ability to efficiently compute...
arxiv.org



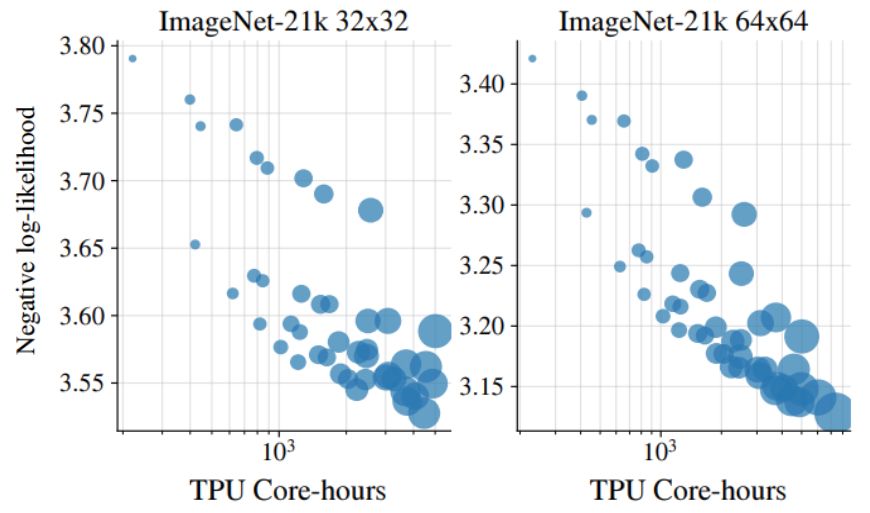


Alexander Kolesnikov
@kolesnikov.ch
· Dec 20
Jet: A Modern Transformer-Based Normalizing Flow
In the past, normalizing generative flows have emerged as a promising class of generative models for natural images. This type of model has many modeling advantages: the ability to efficiently compute...
arxiv.org
Alexander Kolesnikov
@kolesnikov.ch
· Dec 5
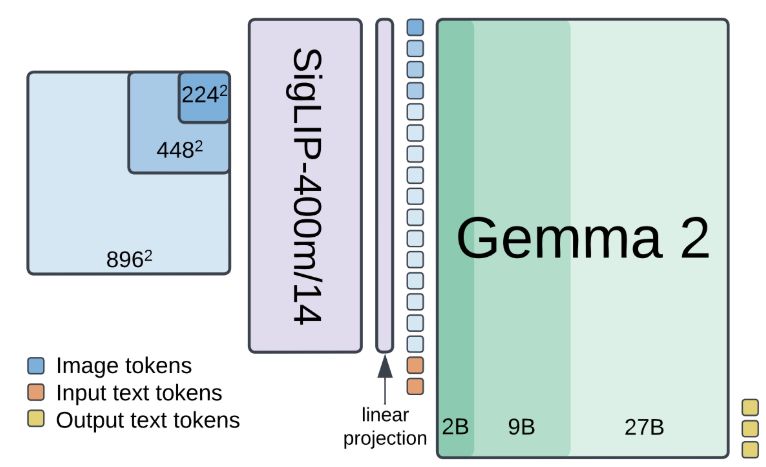
Alexander Kolesnikov
@kolesnikov.ch
· Dec 4
Reposted by Alexander Kolesnikov

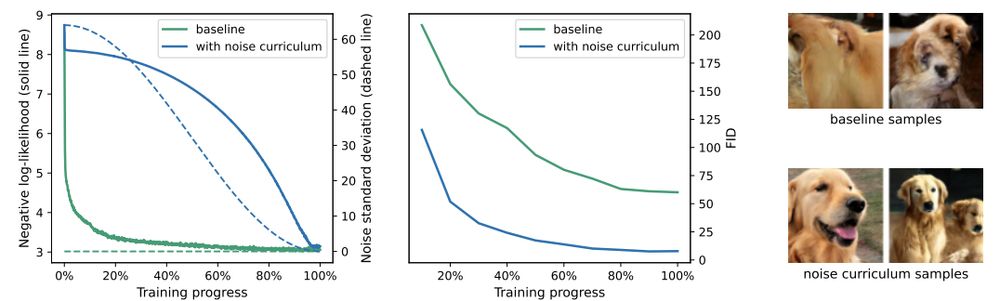
Sander Dieleman
@sedielem.bsky.social
· Dec 2

Alexander Kolesnikov
@kolesnikov.ch
· Dec 2