Michael Tschannen
@mtschannen.bsky.social
870 followers
380 following
17 posts
Research Scientist @GoogleDeepMind. Representation learning for multimodal understanding and generation.
mitscha.github.io
Posts
Media
Videos
Starter Packs


Michael Tschannen
@mtschannen.bsky.social
· Feb 22

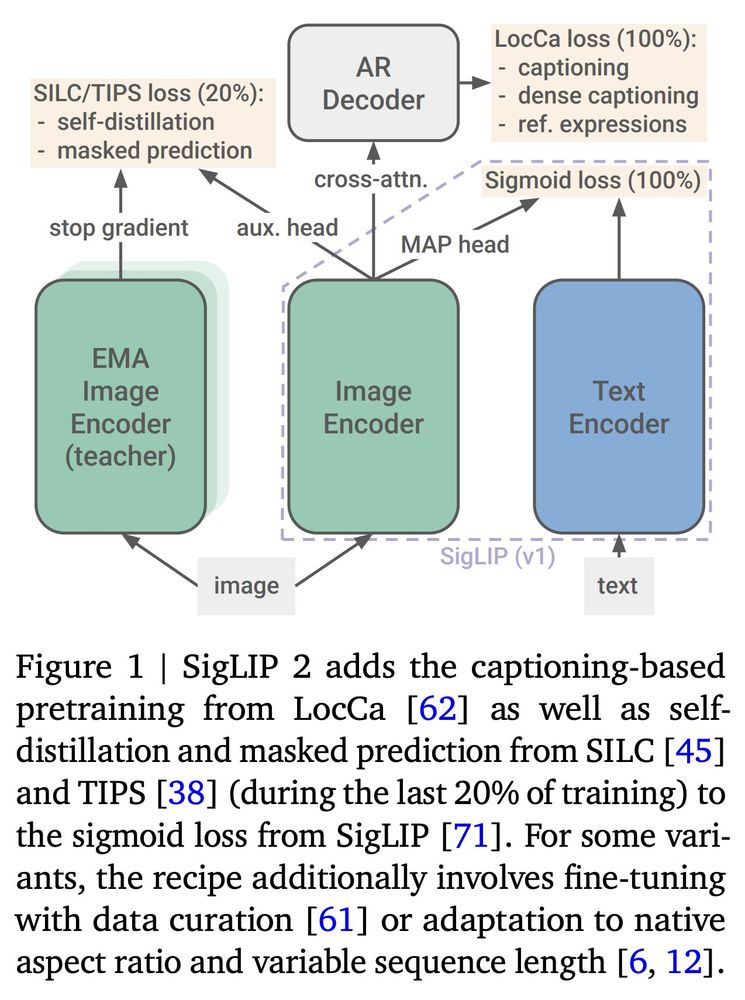
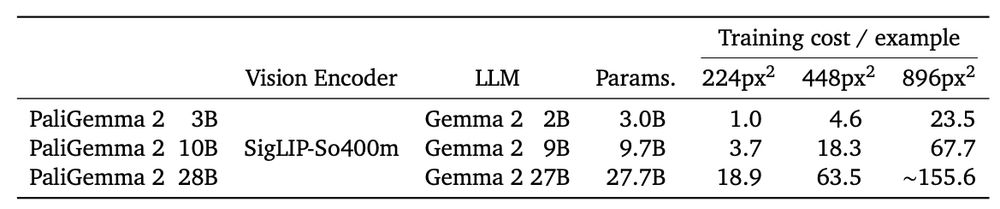
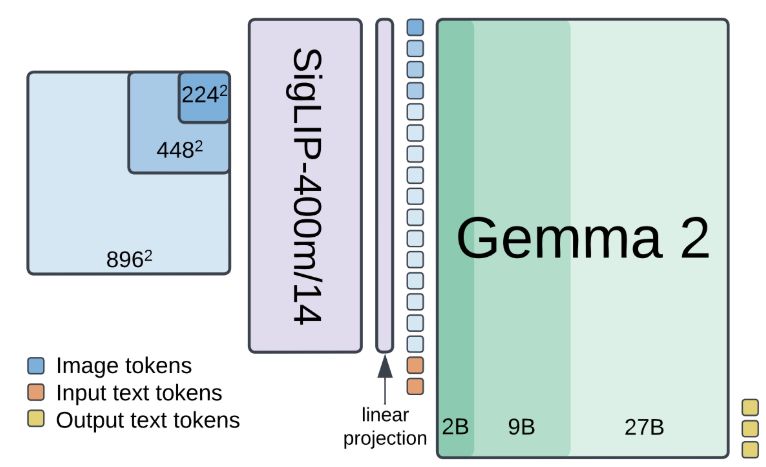
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training obje...
arxiv.org
Reposted by Michael Tschannen


Reposted by Michael Tschannen

Reposted by Michael Tschannen
Reposted by Michael Tschannen

Sander Dieleman
@sedielem.bsky.social
· Dec 2
Reposted by Michael Tschannen


Reposted by Michael Tschannen

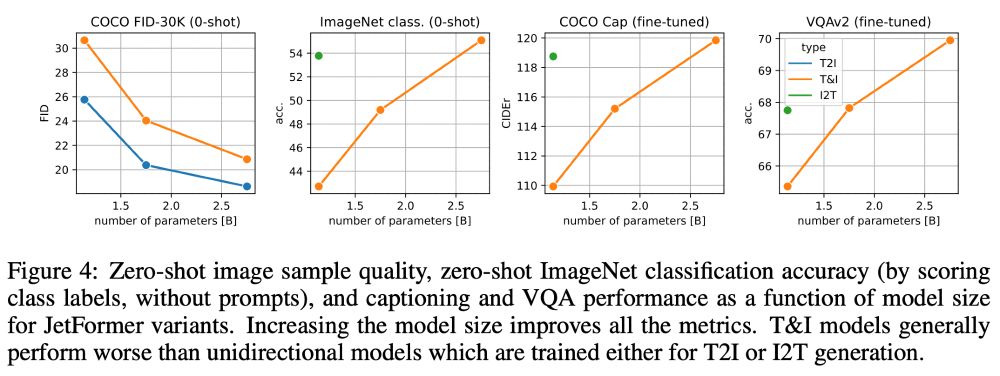
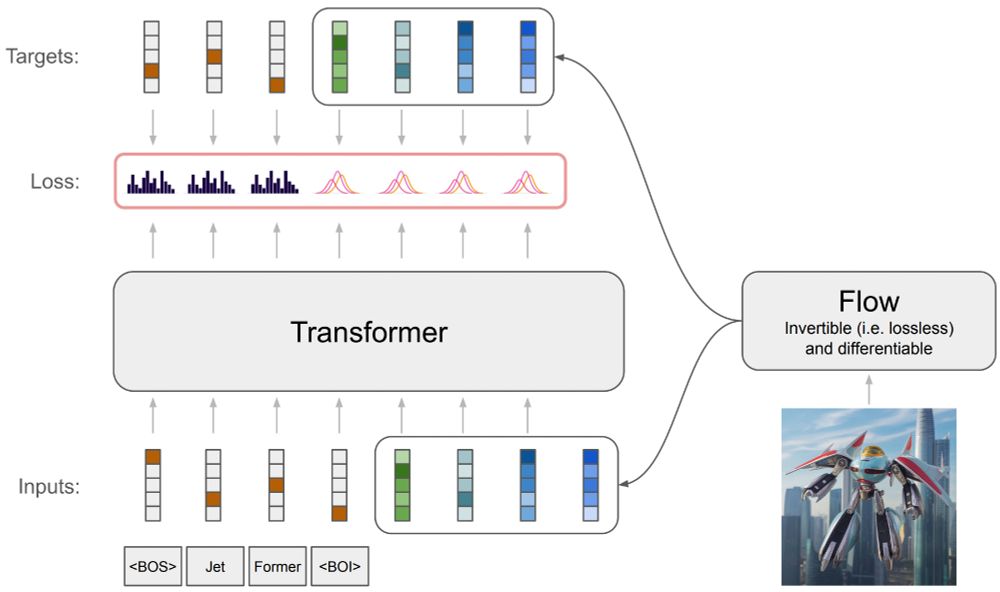
Michael Tschannen
@mtschannen.bsky.social
· Nov 25
Michael Tschannen
@mtschannen.bsky.social
· Nov 24