Marco Cuturi
@marcocuturi.bsky.social
740 followers
58 following
21 posts
machine learning researcher @ Apple machine learning research
Posts
Media
Videos
Starter Packs
Reposted by Marco Cuturi

Reposted by Marco Cuturi







Reposted by Marco Cuturi

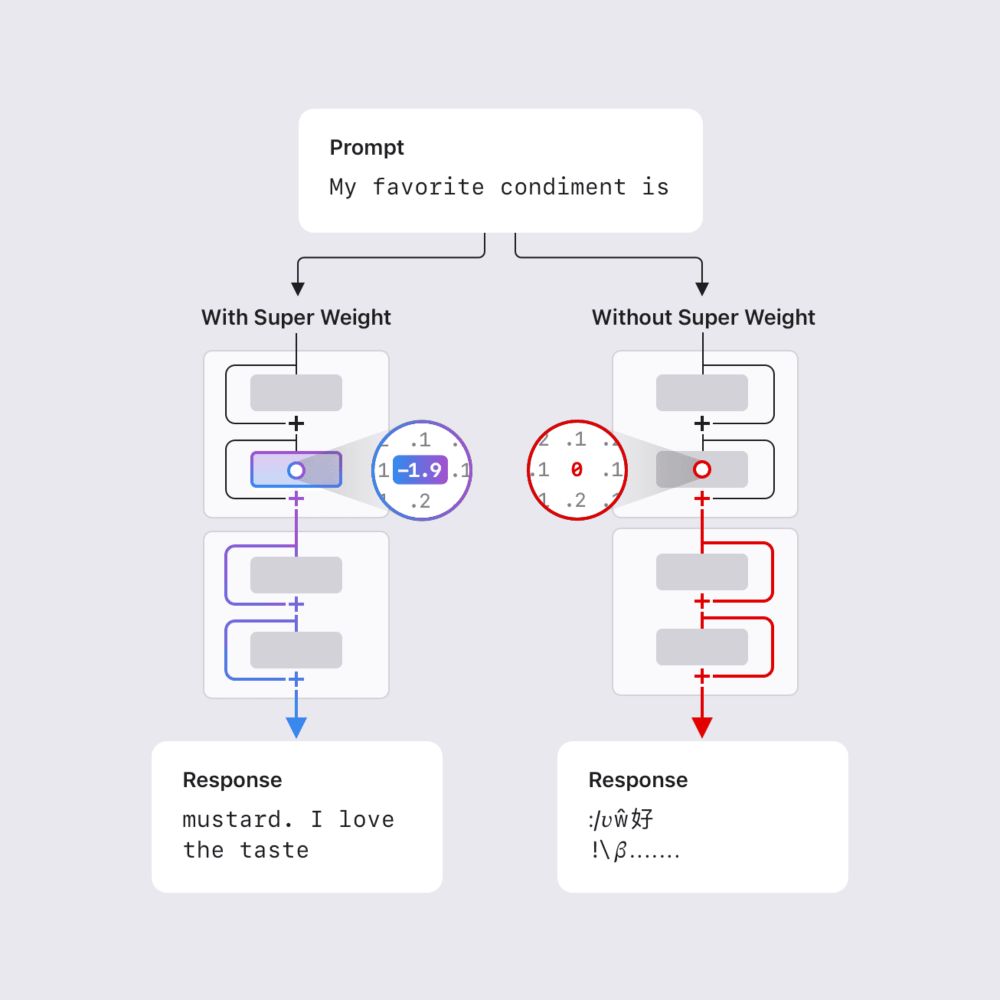

Marco Cuturi
@marcocuturi.bsky.social
· Aug 29
Marco Cuturi
@marcocuturi.bsky.social
· Aug 29
Reposted by Marco Cuturi

Reposted by Marco Cuturi



Reposted by Marco Cuturi


Reposted by Marco Cuturi
Reposted by Marco Cuturi


Reposted by Marco Cuturi



Reposted by Marco Cuturi

Reposted by Marco Cuturi

