



Mustafa Fanaswala
@mfanaswala.bsky.social
Computer vision | SLAM | AR/VR | Robotics | Self-driving cars | CrossFit | Salsero/Bachatero. MSFT, Ex-Nvidia
Reposted by Mustafa Fanaswala

Loft🆙 Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models. We achieve SotA upsampling results for DINOv2. Paper and code:
andrehuang.github.io/loftup-site/
andrehuang.github.io/loftup-site/
April 26, 2025 at 2:47 PM
Loft🆙 Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models. We achieve SotA upsampling results for DINOv2. Paper and code:
andrehuang.github.io/loftup-site/
andrehuang.github.io/loftup-site/
Reposted by Mustafa Fanaswala

I really like this code review article from Jack Kennedy that @nrennie.bsky.social shared in her talk yesterday.
jcken95.github.io/projects/cod...
jcken95.github.io/projects/cod...
Code review for statisticians, data scientists & modellers – Jack Kennedy
Software developers have some really good approaches to code review. Here’s a data scientist’s plea to listen to the software developers!
jcken95.github.io
April 24, 2025 at 1:08 PM
I really like this code review article from Jack Kennedy that @nrennie.bsky.social shared in her talk yesterday.
jcken95.github.io/projects/cod...
jcken95.github.io/projects/cod...
Reposted by Mustafa Fanaswala

Roboverse: unified simulation + dataset + benchmarking that supports many different robotics simulators including nvidia omniverse. One step closer to robotics getting its mmlu, maybe.

April 8, 2025 at 2:05 AM
Roboverse: unified simulation + dataset + benchmarking that supports many different robotics simulators including nvidia omniverse. One step closer to robotics getting its mmlu, maybe.
Reposted by Mustafa Fanaswala

We have made some post-conference improvements of our CVPR'25 paper on end-to-end trained navigation. The agent has similar success rate but is more efficient, faster, less hesitant. Will be presented at CVPR in June.
arxiv.org/abs/2503.08306
Work by @steevenj7.bsky.social et al.
arxiv.org/abs/2503.08306
Work by @steevenj7.bsky.social et al.
April 5, 2025 at 2:38 PM
We have made some post-conference improvements of our CVPR'25 paper on end-to-end trained navigation. The agent has similar success rate but is more efficient, faster, less hesitant. Will be presented at CVPR in June.
arxiv.org/abs/2503.08306
Work by @steevenj7.bsky.social et al.
arxiv.org/abs/2503.08306
Work by @steevenj7.bsky.social et al.
Reposted by Mustafa Fanaswala

🔍Looking for a multi-view depth method that just works?
We're excited to share MVSAnywhere, which we will present at #CVPR2025. MVSAnywhere produces sharp depths, generalizes and is robust to all kind of scenes, and it's scale agnostic.
More info:
nianticlabs.github.io/mvsanywhere/
We're excited to share MVSAnywhere, which we will present at #CVPR2025. MVSAnywhere produces sharp depths, generalizes and is robust to all kind of scenes, and it's scale agnostic.
More info:
nianticlabs.github.io/mvsanywhere/
March 31, 2025 at 12:52 PM
🔍Looking for a multi-view depth method that just works?
We're excited to share MVSAnywhere, which we will present at #CVPR2025. MVSAnywhere produces sharp depths, generalizes and is robust to all kind of scenes, and it's scale agnostic.
More info:
nianticlabs.github.io/mvsanywhere/
We're excited to share MVSAnywhere, which we will present at #CVPR2025. MVSAnywhere produces sharp depths, generalizes and is robust to all kind of scenes, and it's scale agnostic.
More info:
nianticlabs.github.io/mvsanywhere/
Reposted by Mustafa Fanaswala

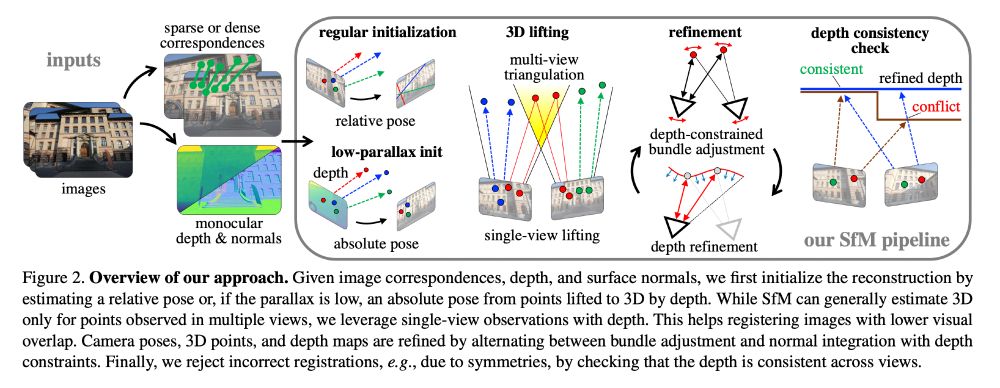
MP-SfM: Monocular Surface Priors for Robust Structure-from-Motion
Zador Pataki, @pesarlin.bsky.social Johannes L. Schonberger, @marcpollefeys.bsky.social
tl;dr: using monodepth to reconstruct w/o co-visible triplets. Many ablations and details. M3Dv2 FTW
demuc.de/papers/patak...
Zador Pataki, @pesarlin.bsky.social Johannes L. Schonberger, @marcpollefeys.bsky.social
tl;dr: using monodepth to reconstruct w/o co-visible triplets. Many ablations and details. M3Dv2 FTW
demuc.de/papers/patak...


March 31, 2025 at 6:38 AM
MP-SfM: Monocular Surface Priors for Robust Structure-from-Motion
Zador Pataki, @pesarlin.bsky.social Johannes L. Schonberger, @marcpollefeys.bsky.social
tl;dr: using monodepth to reconstruct w/o co-visible triplets. Many ablations and details. M3Dv2 FTW
demuc.de/papers/patak...
Zador Pataki, @pesarlin.bsky.social Johannes L. Schonberger, @marcpollefeys.bsky.social
tl;dr: using monodepth to reconstruct w/o co-visible triplets. Many ablations and details. M3Dv2 FTW
demuc.de/papers/patak...
Reposted by Mustafa Fanaswala
Image as an IMU: Estimating Camera Motion from a Single Motion-Blurred Image
Jerred Chen, Ronald Clark
tl;dr:predict flow from blurred image -> solve for velocity, use as IMU information.
arxiv.org/abs/2503.17358
Jerred Chen, Ronald Clark
tl;dr:predict flow from blurred image -> solve for velocity, use as IMU information.
arxiv.org/abs/2503.17358




March 24, 2025 at 9:38 AM
Image as an IMU: Estimating Camera Motion from a Single Motion-Blurred Image
Jerred Chen, Ronald Clark
tl;dr:predict flow from blurred image -> solve for velocity, use as IMU information.
arxiv.org/abs/2503.17358
Jerred Chen, Ronald Clark
tl;dr:predict flow from blurred image -> solve for velocity, use as IMU information.
arxiv.org/abs/2503.17358
Reposted by Mustafa Fanaswala
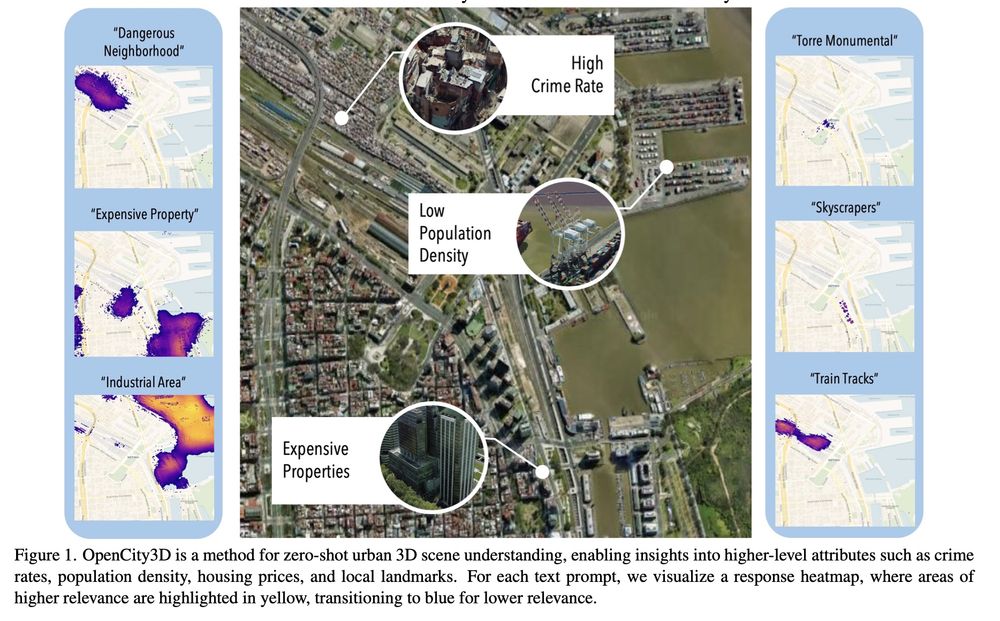
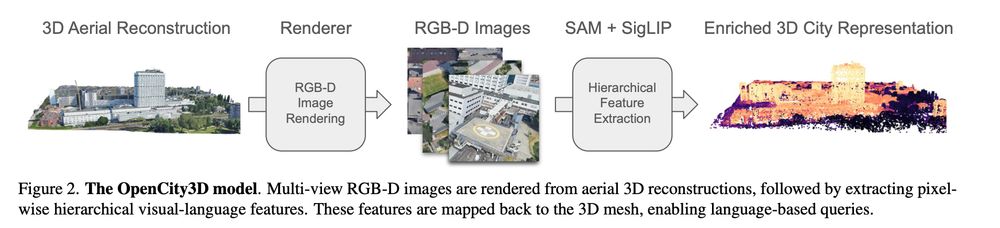
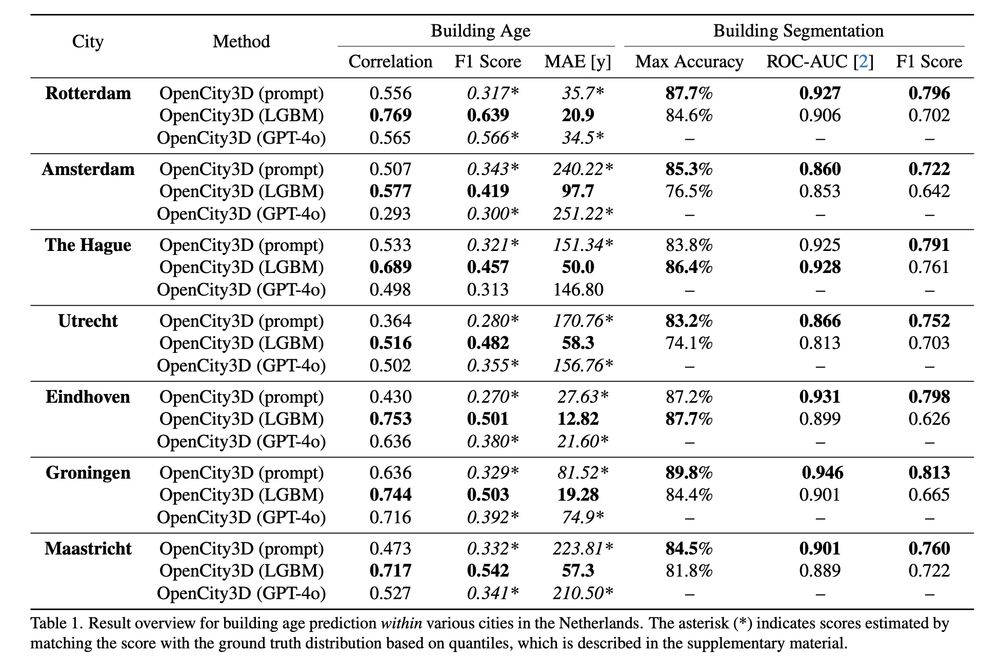
OpenCity3D: What do Vision-Language Models know about Urban Environments?
Valentin Bieri, Marco Zamboni, Nicolas S. Blumer, Qingxuan Chen, Francis Engelmann
tl;dr: if you have aerial 3D reconstruction, use SigLIP to be happy.
arxiv.org/abs/2503.16776
Valentin Bieri, Marco Zamboni, Nicolas S. Blumer, Qingxuan Chen, Francis Engelmann
tl;dr: if you have aerial 3D reconstruction, use SigLIP to be happy.
arxiv.org/abs/2503.16776
March 24, 2025 at 10:21 AM
OpenCity3D: What do Vision-Language Models know about Urban Environments?
Valentin Bieri, Marco Zamboni, Nicolas S. Blumer, Qingxuan Chen, Francis Engelmann
tl;dr: if you have aerial 3D reconstruction, use SigLIP to be happy.
arxiv.org/abs/2503.16776
Valentin Bieri, Marco Zamboni, Nicolas S. Blumer, Qingxuan Chen, Francis Engelmann
tl;dr: if you have aerial 3D reconstruction, use SigLIP to be happy.
arxiv.org/abs/2503.16776
Reposted by Mustafa Fanaswala

'We Are Eating the Earth' author Michael Grunwald, explores an important question, "How should writers like me approach four years of drill-baby-drill hostility to climate progress, and how should readers like you think about it?" @mikegrunwald.bsky.social
www.canarymedia.com/articles/foo...
www.canarymedia.com/articles/foo...

March 20, 2025 at 7:26 PM
'We Are Eating the Earth' author Michael Grunwald, explores an important question, "How should writers like me approach four years of drill-baby-drill hostility to climate progress, and how should readers like you think about it?" @mikegrunwald.bsky.social
www.canarymedia.com/articles/foo...
www.canarymedia.com/articles/foo...
Reposted by Mustafa Fanaswala

Multi-view Reconstruction via SfM-guided Monocular Depth Estimation
Haoyu Guo, He Zhu, Sida Peng, Haotong Lin, Yunzhi Yan, Tao Xie, Wenguan Wang, Xiaowei Zhou, Hujun Bao
arxiv.org/abs/2503.14483
Haoyu Guo, He Zhu, Sida Peng, Haotong Lin, Yunzhi Yan, Tao Xie, Wenguan Wang, Xiaowei Zhou, Hujun Bao
arxiv.org/abs/2503.14483




March 20, 2025 at 9:28 AM
Multi-view Reconstruction via SfM-guided Monocular Depth Estimation
Haoyu Guo, He Zhu, Sida Peng, Haotong Lin, Yunzhi Yan, Tao Xie, Wenguan Wang, Xiaowei Zhou, Hujun Bao
arxiv.org/abs/2503.14483
Haoyu Guo, He Zhu, Sida Peng, Haotong Lin, Yunzhi Yan, Tao Xie, Wenguan Wang, Xiaowei Zhou, Hujun Bao
arxiv.org/abs/2503.14483
Reposted by Mustafa Fanaswala
Bolt3D: Generating 3D Scenes in Seconds
Stanislaw Szymanowicz, Jason Y. Zhang, Pratul Srinivasan, Ruiqi Gao, Arthur Brussee, @holynski.bsky.social, Ricardo Martin-Brualla, @jonbarron.bsky.social, Philipp Henzler
arxiv.org/abs/2503.14445
Stanislaw Szymanowicz, Jason Y. Zhang, Pratul Srinivasan, Ruiqi Gao, Arthur Brussee, @holynski.bsky.social, Ricardo Martin-Brualla, @jonbarron.bsky.social, Philipp Henzler
arxiv.org/abs/2503.14445




March 20, 2025 at 9:30 AM
Bolt3D: Generating 3D Scenes in Seconds
Stanislaw Szymanowicz, Jason Y. Zhang, Pratul Srinivasan, Ruiqi Gao, Arthur Brussee, @holynski.bsky.social, Ricardo Martin-Brualla, @jonbarron.bsky.social, Philipp Henzler
arxiv.org/abs/2503.14445
Stanislaw Szymanowicz, Jason Y. Zhang, Pratul Srinivasan, Ruiqi Gao, Arthur Brussee, @holynski.bsky.social, Ricardo Martin-Brualla, @jonbarron.bsky.social, Philipp Henzler
arxiv.org/abs/2503.14445
Reposted by Mustafa Fanaswala

Transformers, but without normalization layers
A simple alternative to normalization layers: the scaled tanh function, which they call Dynamic Tanh, or DyT.
A simple alternative to normalization layers: the scaled tanh function, which they call Dynamic Tanh, or DyT.

March 14, 2025 at 5:41 AM
Transformers, but without normalization layers
A simple alternative to normalization layers: the scaled tanh function, which they call Dynamic Tanh, or DyT.
A simple alternative to normalization layers: the scaled tanh function, which they call Dynamic Tanh, or DyT.
Reposted by Mustafa Fanaswala
Fixing the RANSAC Stopping Criterion
Johannes Schönberger, Viktor Larsson, @marcpollefeys.bsky.social
tl;dr: original RANSAC formula for number of iterations underestimates for hard cases and overestimates for easy. Here is corrected one -> better results
arxiv.org/abs/2503.07829
Johannes Schönberger, Viktor Larsson, @marcpollefeys.bsky.social
tl;dr: original RANSAC formula for number of iterations underestimates for hard cases and overestimates for easy. Here is corrected one -> better results
arxiv.org/abs/2503.07829


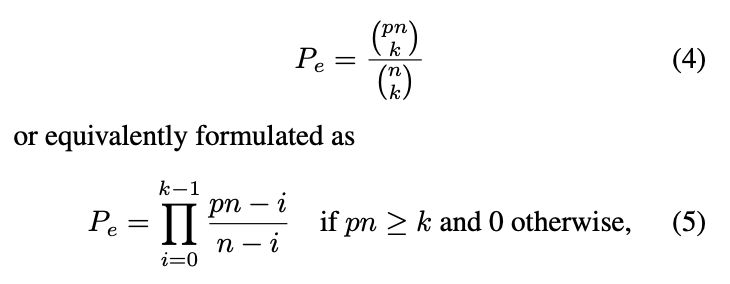

March 12, 2025 at 7:37 AM
Fixing the RANSAC Stopping Criterion
Johannes Schönberger, Viktor Larsson, @marcpollefeys.bsky.social
tl;dr: original RANSAC formula for number of iterations underestimates for hard cases and overestimates for easy. Here is corrected one -> better results
arxiv.org/abs/2503.07829
Johannes Schönberger, Viktor Larsson, @marcpollefeys.bsky.social
tl;dr: original RANSAC formula for number of iterations underestimates for hard cases and overestimates for easy. Here is corrected one -> better results
arxiv.org/abs/2503.07829
Reposted by Mustafa Fanaswala

Another grad school RL friend on the pod! Lot's of non-reasoning RL talk here!
Interviewing Eugene Vinitsky (@eugenevinitsky.bsky.social) on self-play for self-driving and what else people do with RL
#13. Reinforcement learning fundamentals and scaling.
Post: buff.ly/8fLBJA6
YouTube: buff.ly/eJ6heSI
Interviewing Eugene Vinitsky (@eugenevinitsky.bsky.social) on self-play for self-driving and what else people do with RL
#13. Reinforcement learning fundamentals and scaling.
Post: buff.ly/8fLBJA6
YouTube: buff.ly/eJ6heSI

Interviewing Eugene Vinitsky on self-play for self-driving and what else people do with RL
#13. Reinforcement learning fundamentals and scaling.
buff.ly
March 12, 2025 at 2:09 PM
Another grad school RL friend on the pod! Lot's of non-reasoning RL talk here!
Interviewing Eugene Vinitsky (@eugenevinitsky.bsky.social) on self-play for self-driving and what else people do with RL
#13. Reinforcement learning fundamentals and scaling.
Post: buff.ly/8fLBJA6
YouTube: buff.ly/eJ6heSI
Interviewing Eugene Vinitsky (@eugenevinitsky.bsky.social) on self-play for self-driving and what else people do with RL
#13. Reinforcement learning fundamentals and scaling.
Post: buff.ly/8fLBJA6
YouTube: buff.ly/eJ6heSI
Reposted by Mustafa Fanaswala
Amazing threads!
I wish to read more papers like this! Envying the reviewers
I wish to read more papers like this! Envying the reviewers
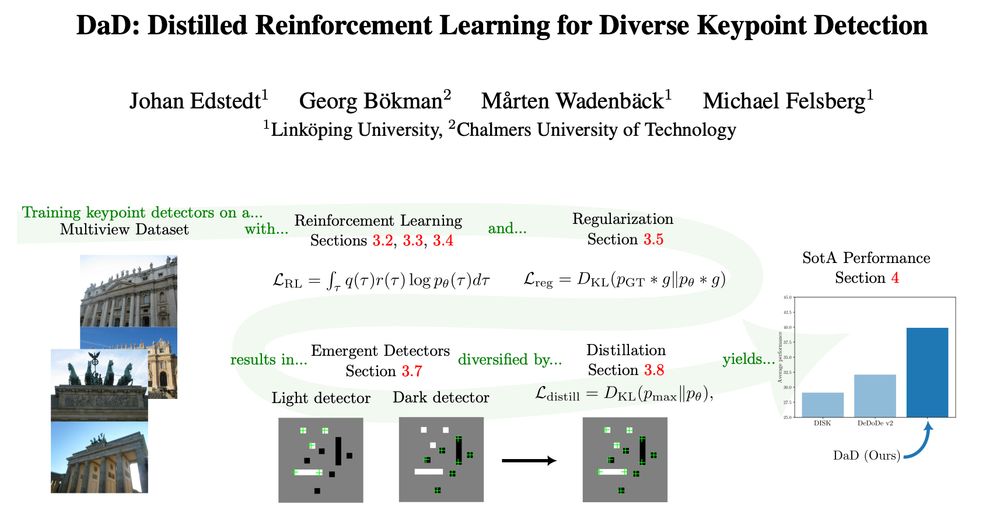
Introducing DaD (arxiv.org/abs/2503.07347), a pretty cool keypoint detector.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
March 11, 2025 at 6:39 AM
Amazing threads!
I wish to read more papers like this! Envying the reviewers
I wish to read more papers like this! Envying the reviewers
Reposted by Mustafa Fanaswala
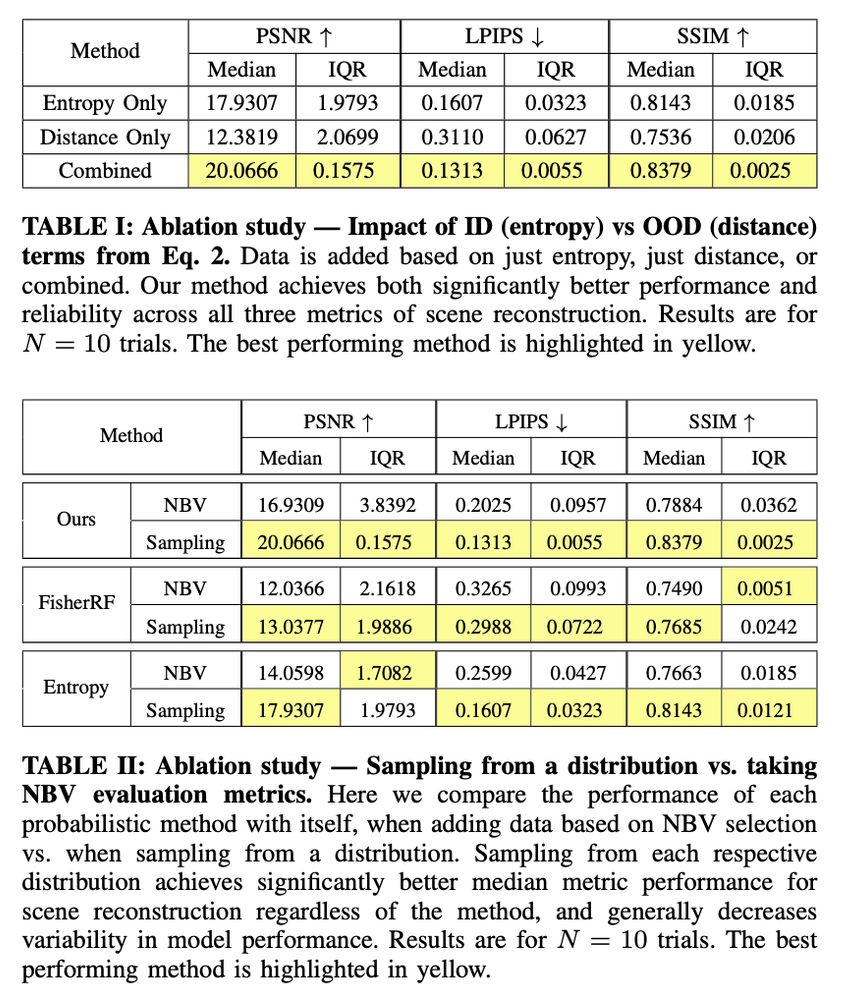
Data Augmentation for NeRFs in the Low Data Limit
Ayush Gaggar, Todd D. Murphey
tl;dr: any uncertainty-based view sampling is better than next-best-view sampling.
I didn't get where the "augmentation" comes from though
arxiv.org/abs/2503.02092
Ayush Gaggar, Todd D. Murphey
tl;dr: any uncertainty-based view sampling is better than next-best-view sampling.
I didn't get where the "augmentation" comes from though
arxiv.org/abs/2503.02092



March 10, 2025 at 11:21 AM
Data Augmentation for NeRFs in the Low Data Limit
Ayush Gaggar, Todd D. Murphey
tl;dr: any uncertainty-based view sampling is better than next-best-view sampling.
I didn't get where the "augmentation" comes from though
arxiv.org/abs/2503.02092
Ayush Gaggar, Todd D. Murphey
tl;dr: any uncertainty-based view sampling is better than next-best-view sampling.
I didn't get where the "augmentation" comes from though
arxiv.org/abs/2503.02092
Reposted by Mustafa Fanaswala

Introducing DaD (arxiv.org/abs/2503.07347), a pretty cool keypoint detector.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
March 11, 2025 at 3:05 AM
Introducing DaD (arxiv.org/abs/2503.07347), a pretty cool keypoint detector.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
Reposted by Mustafa Fanaswala
Image-Based Relocalization and Alignment for Long-Term Monitoring of Dynamic Underwater Environments
Beverley Gorry, Tobias Fischer, Michael Milford, Alejandro Fontan
tl;dr: SuperPoint +LightGlue can breath underwater.
arxiv.org/abs/2503.04096
Beverley Gorry, Tobias Fischer, Michael Milford, Alejandro Fontan
tl;dr: SuperPoint +LightGlue can breath underwater.
arxiv.org/abs/2503.04096




March 10, 2025 at 11:12 AM
Image-Based Relocalization and Alignment for Long-Term Monitoring of Dynamic Underwater Environments
Beverley Gorry, Tobias Fischer, Michael Milford, Alejandro Fontan
tl;dr: SuperPoint +LightGlue can breath underwater.
arxiv.org/abs/2503.04096
Beverley Gorry, Tobias Fischer, Michael Milford, Alejandro Fontan
tl;dr: SuperPoint +LightGlue can breath underwater.
arxiv.org/abs/2503.04096
Reposted by Mustafa Fanaswala
We made a new keypoint detector named DaD, paper isn't up yet, but code and weights are:
github.com/Parskatt/dad
github.com/Parskatt/dad

March 10, 2025 at 7:53 AM
We made a new keypoint detector named DaD, paper isn't up yet, but code and weights are:
github.com/Parskatt/dad
github.com/Parskatt/dad
Reposted by Mustafa Fanaswala
JamMa: Ultra-lightweight Local Feature Matching with Joint Mamba
Xiaoyong Lu, Songlin Du
tl;dr: replace Transformer in LoFTR with Mamba
Mamba takes the torch in local feature matching
no eval on IMC
github.com/leoluxxx/JamMa
arxiv.org/abs/2503.03437
Xiaoyong Lu, Songlin Du
tl;dr: replace Transformer in LoFTR with Mamba
Mamba takes the torch in local feature matching
no eval on IMC
github.com/leoluxxx/JamMa
arxiv.org/abs/2503.03437




March 6, 2025 at 4:57 AM
JamMa: Ultra-lightweight Local Feature Matching with Joint Mamba
Xiaoyong Lu, Songlin Du
tl;dr: replace Transformer in LoFTR with Mamba
Mamba takes the torch in local feature matching
no eval on IMC
github.com/leoluxxx/JamMa
arxiv.org/abs/2503.03437
Xiaoyong Lu, Songlin Du
tl;dr: replace Transformer in LoFTR with Mamba
Mamba takes the torch in local feature matching
no eval on IMC
github.com/leoluxxx/JamMa
arxiv.org/abs/2503.03437
Reposted by Mustafa Fanaswala
Integral Forms in Matrix Lie Groups
Timothy D Barfoot
tl;dr: minimal polynomial->Lie algebra->compact analytic results
transfer back and forth between series form and integra
arxiv.org/abs/2503.02820
Timothy D Barfoot
tl;dr: minimal polynomial->Lie algebra->compact analytic results
transfer back and forth between series form and integra
arxiv.org/abs/2503.02820



March 5, 2025 at 4:23 AM
Integral Forms in Matrix Lie Groups
Timothy D Barfoot
tl;dr: minimal polynomial->Lie algebra->compact analytic results
transfer back and forth between series form and integra
arxiv.org/abs/2503.02820
Timothy D Barfoot
tl;dr: minimal polynomial->Lie algebra->compact analytic results
transfer back and forth between series form and integra
arxiv.org/abs/2503.02820
Reposted by Mustafa Fanaswala
Dataset Distillation (2018/2020)
They show that it is possible to compress 60,000 MNIST training images into just 10 synthetic distilled images (one per class) and achieve close to original performance with only a few gradient descent steps, given a fixed network initialization.
They show that it is possible to compress 60,000 MNIST training images into just 10 synthetic distilled images (one per class) and achieve close to original performance with only a few gradient descent steps, given a fixed network initialization.

March 5, 2025 at 12:23 AM
Dataset Distillation (2018/2020)
They show that it is possible to compress 60,000 MNIST training images into just 10 synthetic distilled images (one per class) and achieve close to original performance with only a few gradient descent steps, given a fixed network initialization.
They show that it is possible to compress 60,000 MNIST training images into just 10 synthetic distilled images (one per class) and achieve close to original performance with only a few gradient descent steps, given a fixed network initialization.
Reposted by Mustafa Fanaswala
smalldiffusion
A lightweight diffusion library for training and sampling from diffusion models. The core of this library for diffusion training and sampling is implemented in less than 100 lines of very readable pytorch code.
github.com/yuanchenyang...
A lightweight diffusion library for training and sampling from diffusion models. The core of this library for diffusion training and sampling is implemented in less than 100 lines of very readable pytorch code.
github.com/yuanchenyang...

GitHub - yuanchenyang/smalldiffusion: Simple and readable code for training and sampling from diffusion models
Simple and readable code for training and sampling from diffusion models - yuanchenyang/smalldiffusion
github.com
March 5, 2025 at 5:34 AM
smalldiffusion
A lightweight diffusion library for training and sampling from diffusion models. The core of this library for diffusion training and sampling is implemented in less than 100 lines of very readable pytorch code.
github.com/yuanchenyang...
A lightweight diffusion library for training and sampling from diffusion models. The core of this library for diffusion training and sampling is implemented in less than 100 lines of very readable pytorch code.
github.com/yuanchenyang...