Paul Medvedev
@pashadag.bsky.social
1.8K followers
160 following
80 posts
Algorithmic Bioinformatics Researcher and Teacher. Posts about research results and educational/mentorship topics (for details, see http://bit.ly/380vX22).
Posts
Media
Videos
Starter Packs




Reposted by Paul Medvedev

Reposted by Paul Medvedev


Reposted by Paul Medvedev


Reposted by Paul Medvedev

Paul Medvedev
@pashadag.bsky.social
· Sep 7
Reposted by Paul Medvedev


Reposted by Paul Medvedev

Tobias Marschall
@tobiasmar.bsky.social
· Jul 23
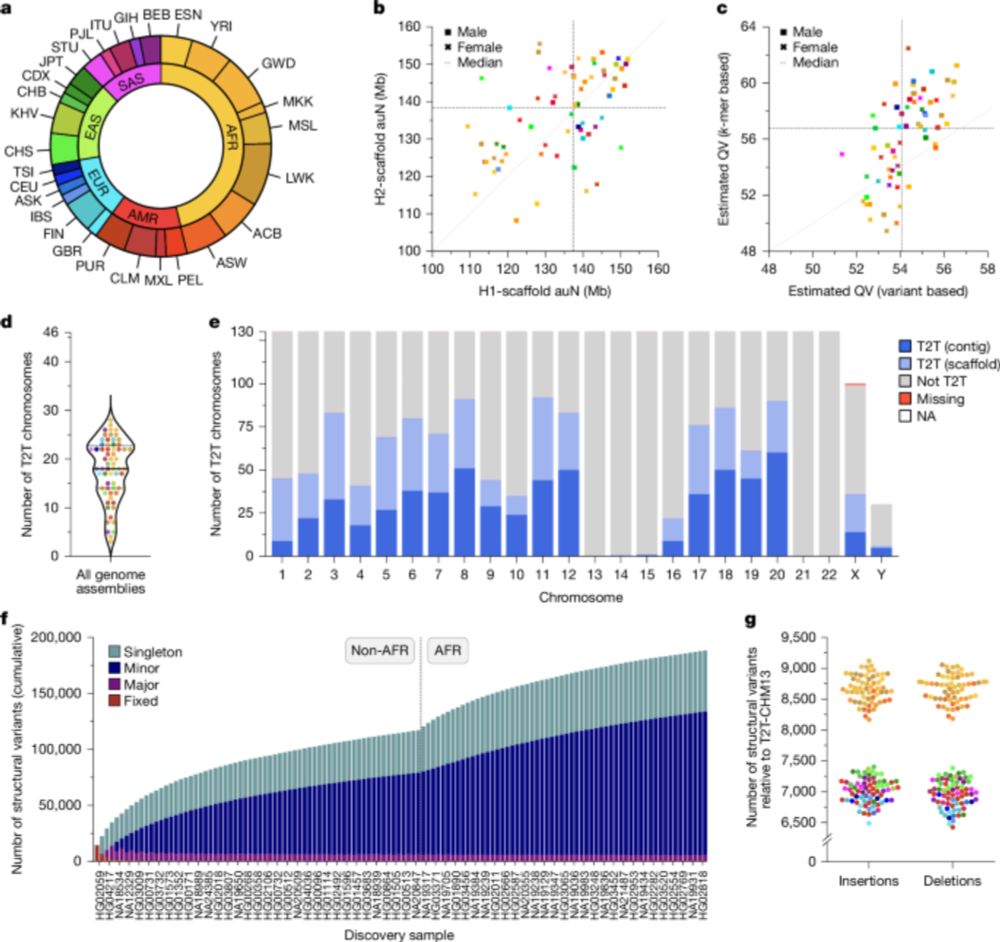
Complex genetic variation in nearly complete human genomes - Nature
Using sequencing and haplotype-resolved assembly of 65 diverse human genomes, complex regions including the major histocompatibility complex and centromeres are analysed.
tinyurl.com

