Paul Madley-Dowd
@pmadleydowd.bsky.social
98 followers
110 following
23 posts
Research Fellow in Medical Statistics and Health Data Science at the University of Bristol
Posts
Media
Videos
Starter Packs
Reposted by Paul Madley-Dowd


Reposted by Paul Madley-Dowd



Reposted by Paul Madley-Dowd

Reposted by Paul Madley-Dowd

Venexia Walker
@venexia.bsky.social
· Jul 4

Paul Madley-Dowd
@pmadleydowd.bsky.social
· May 14
Paul Madley-Dowd
@pmadleydowd.bsky.social
· Mar 27

Reposted by Paul Madley-Dowd

Lorenzo Fabbri
@epilorenzofabbri.com
· Mar 24



Reposted by Paul Madley-Dowd

Suzie Cro
@suziecro.bsky.social
· Mar 18

Paul Madley-Dowd
@pmadleydowd.bsky.social
· Feb 19
Paul Madley-Dowd
@pmadleydowd.bsky.social
· Feb 19
Paul Madley-Dowd
@pmadleydowd.bsky.social
· Feb 19
Paul Madley-Dowd
@pmadleydowd.bsky.social
· Feb 19
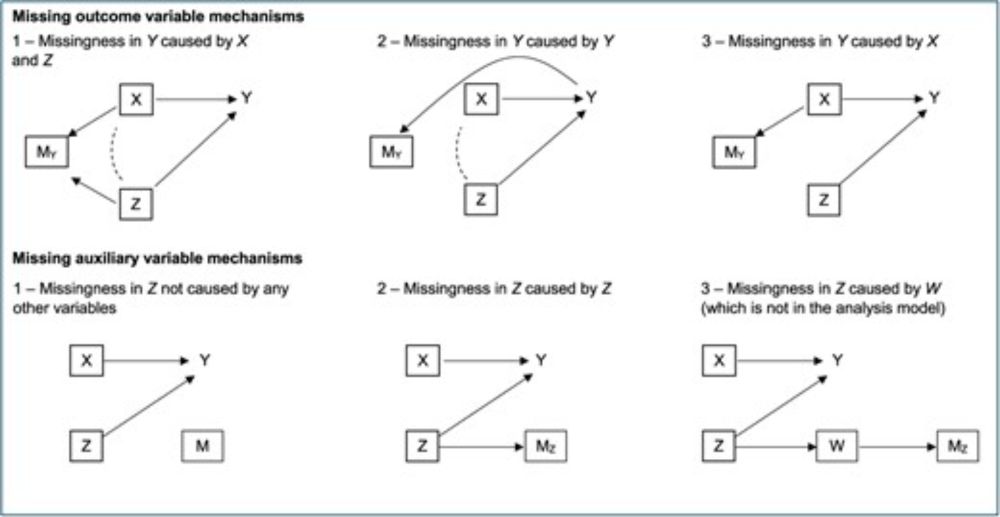
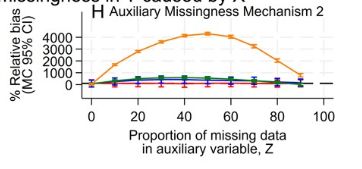
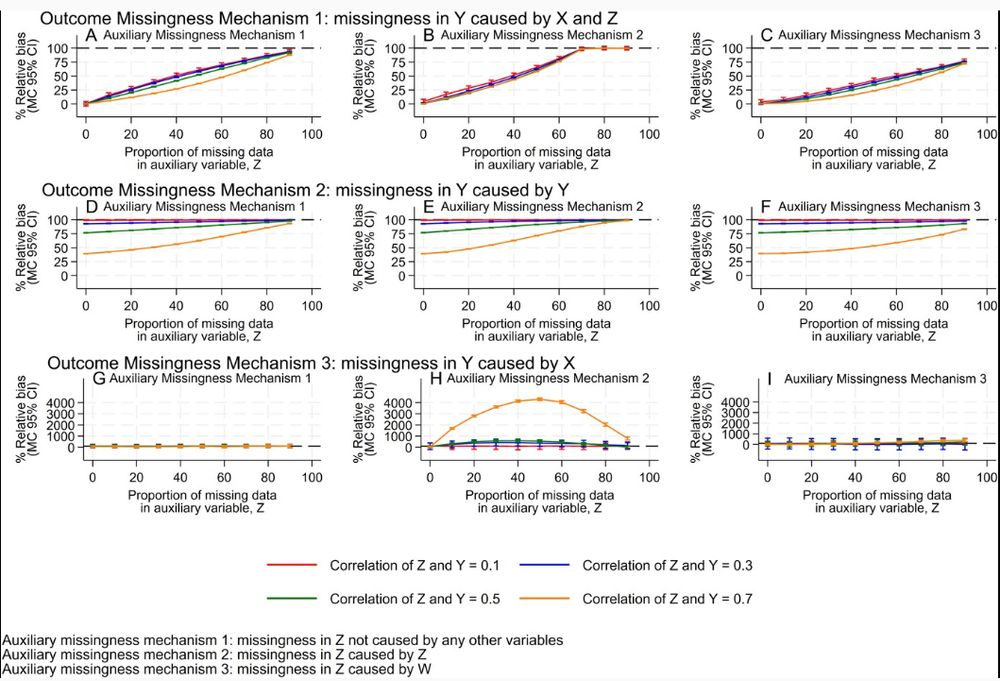
Analyses using multiple imputation need to consider missing data in auxiliary variables
Abstract. Auxiliary variables are used in multiple imputation (MI) to reduce bias and increase efficiency. These variables may often themselves be incomple
doi.org
Paul Madley-Dowd
@pmadleydowd.bsky.social
· Nov 21
Paul Madley-Dowd
@pmadleydowd.bsky.social
· Nov 21