
Bradley Love
@profdata.bsky.social
4.1K followers
740 following
51 posts
Senior research scientist at Los Alamos National Laboratory. Former UCL, UTexas, Alan Turing Institute, Ellis EU. CogSci, AI, Comp Neuro, AI for scientific discovery https://bradlove.org
Posts
Media
Videos
Starter Packs




Bradley Love
@profdata.bsky.social
· Jul 18
Bradley Love
@profdata.bsky.social
· Jun 13

Giving LLMs too much RoPE: A limit on Sutton’s Bitter Lesson — Bradley C. Love
Introduction Sutton’s Bitter Lesson (Sutton, 2019) argues that machine learning breakthroughs, like AlphaGo, BERT, and large-scale vision models, rely on general, computation-driven methods that prior...
bradlove.org

Bradley Love
@profdata.bsky.social
· May 14

Probability Consistency in Large Language Models: Theoretical Foundations Meet Empirical Discrepancies
Can autoregressive large language models (LLMs) learn consistent probability distributions when trained on sequences in different token orders? We prove formally that for any well-defined probability ...
arxiv.org
Bradley Love
@profdata.bsky.social
· May 14
Probability Consistency in Large Language Models: Theoretical Foundations Meet Empirical Discrepancies
Can autoregressive large language models (LLMs) learn consistent probability distributions when trained on sequences in different token orders? We prove formally that for any well-defined probability ...
arxiv.org
Bradley Love
@profdata.bsky.social
· May 14
Probability Consistency in Large Language Models: Theoretical Foundations Meet Empirical Discrepancies
Can autoregressive large language models (LLMs) learn consistent probability distributions when trained on sequences in different token orders? We prove formally that for any well-defined probability ...
arxiv.org
Bradley Love
@profdata.bsky.social
· Feb 17

Reposted by Bradley Love




Bradley Love
@profdata.bsky.social
· Nov 27
Bradley Love
@profdata.bsky.social
· Nov 27


Bradley Love
@profdata.bsky.social
· Nov 27
Confidence-weighted integration of human and machine judgments for superior decision-making
Large language models (LLMs) have emerged as powerful tools in various domains. Recent studies have shown that LLMs can surpass humans in certain tasks, such as predicting the outcomes of neuroscience...
arxiv.org
Bradley Love
@profdata.bsky.social
· Nov 27
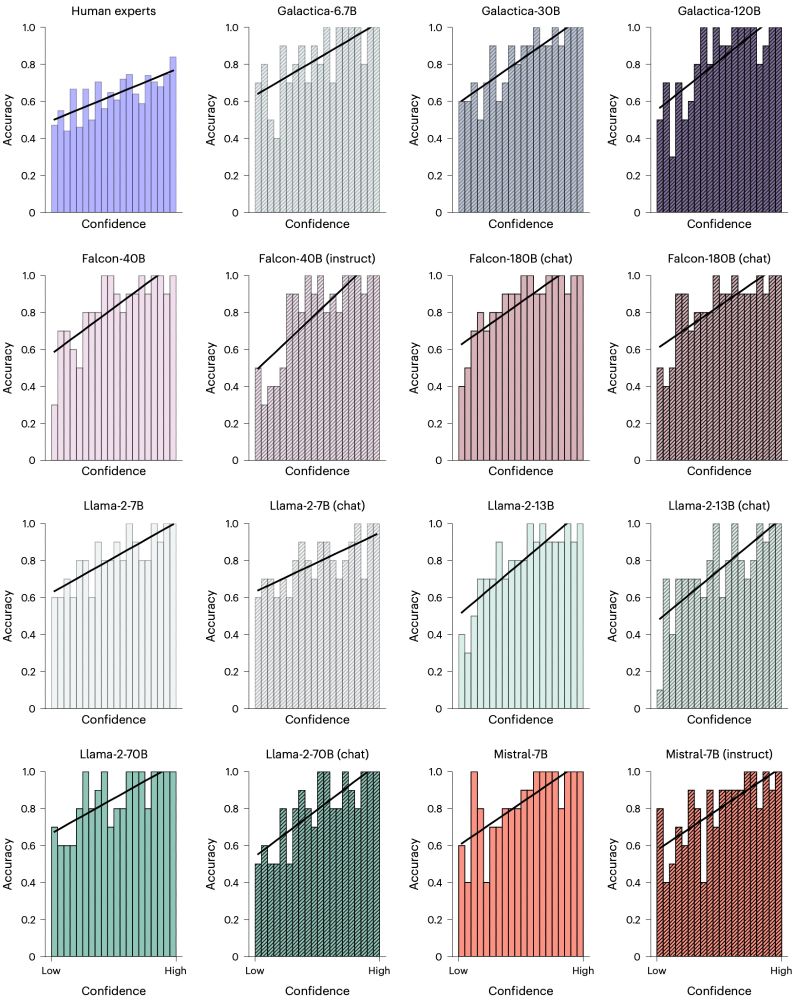
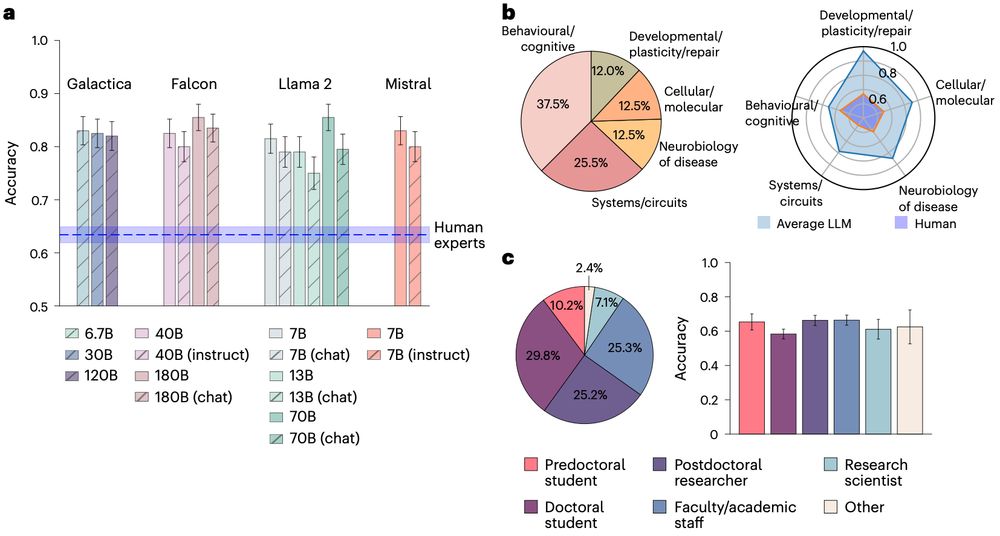
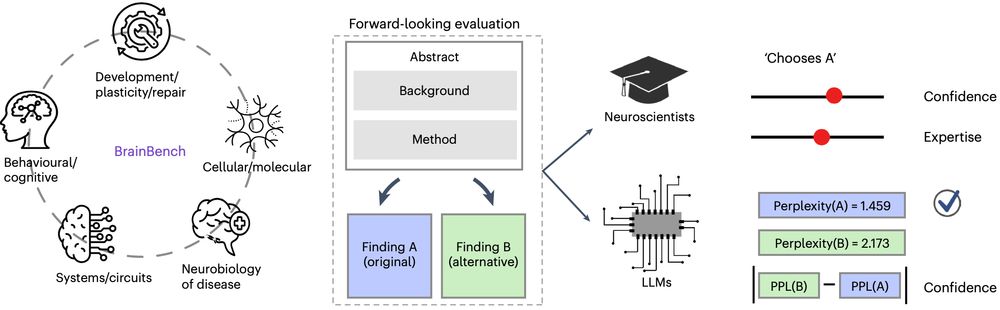
Matching domain experts by training from scratch on domain knowledge
Recently, large language models (LLMs) have outperformed human experts in predicting the results of neuroscience experiments (Luo et al., 2024). What is the basis for this performance? One possibility...
arxiv.org

Bradley Love
@profdata.bsky.social
· Nov 20
Bradley Love
@profdata.bsky.social
· Nov 19
Bradley Love
@profdata.bsky.social
· Nov 19