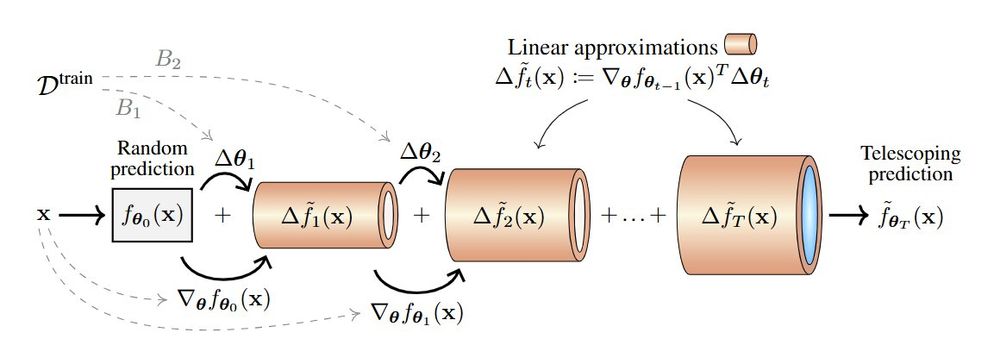
Simone Scardapane
@sscardapane.bsky.social
470 followers
35 following
42 posts
I fall in love with a new #machinelearning topic every month 🙄
Ass. Prof. Sapienza (Rome) | Author: Alice in a differentiable wonderland (https://www.sscardapane.it/alice-book/)
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Simone Scardapane

Nathan Godey
@nthngdy.bsky.social
· Mar 6
Reposted by Simone Scardapane

Reposted by Simone Scardapane


Reposted by Simone Scardapane
Reposted by Simone Scardapane















Reposted by Simone Scardapane

Fabio Montello
@zioictus.bsky.social
· Jan 15

A Survey on Dynamic Neural Networks: from Computer Vision to Multi-modal Sensor Fusion
Model compression is essential in the deployment of large Computer Vision models on embedded devices. However, static optimization techniques (e.g. pruning, quantization, etc.) neglect the fact that d...
arxiv.org

Reposted by Simone Scardapane