Vladan Stojnić
@stojnicv.xyz
630 followers
220 following
36 posts
Ph.D. student at Visual Recognition Group, Czech Technical University in Prague
🔗 https://stojnicv.xyz
Posts
Media
Videos
Starter Packs
Reposted by Vladan Stojnić

Reposted by Vladan Stojnić


Reposted by Vladan Stojnić

Giorgos Tolias
@gtolias.bsky.social
· Sep 8

Reposted by Vladan Stojnić

Reposted by Vladan Stojnić

David Picard
@davidpicard.bsky.social
· Sep 3

Category-level Text-to-Image Retrieval Improved: Bridging the Domain Gap with Diffusion Models and Vision Encoders
This work explores text-to-image retrieval for queries that specify or describe a semantic category. While vision-and-language models (VLMs) like CLIP offer a straightforward open-vocabulary solution,...
arxiv.org
Reposted by Vladan Stojnić

Reposted by Vladan Stojnić








Vladan Stojnić
@stojnicv.xyz
· Aug 18
Vladan Stojnić
@stojnicv.xyz
· Aug 18

Processing and acquisition traces in visual encoders: What does CLIP know about your camera?
Prior work has analyzed the robustness of visual encoders to image transformations and corruptions, particularly in cases where such alterations are not seen during training. When this occurs, they in...
arxiv.org







Reposted by Vladan Stojnić

Vladan Stojnić
@stojnicv.xyz
· Jun 13
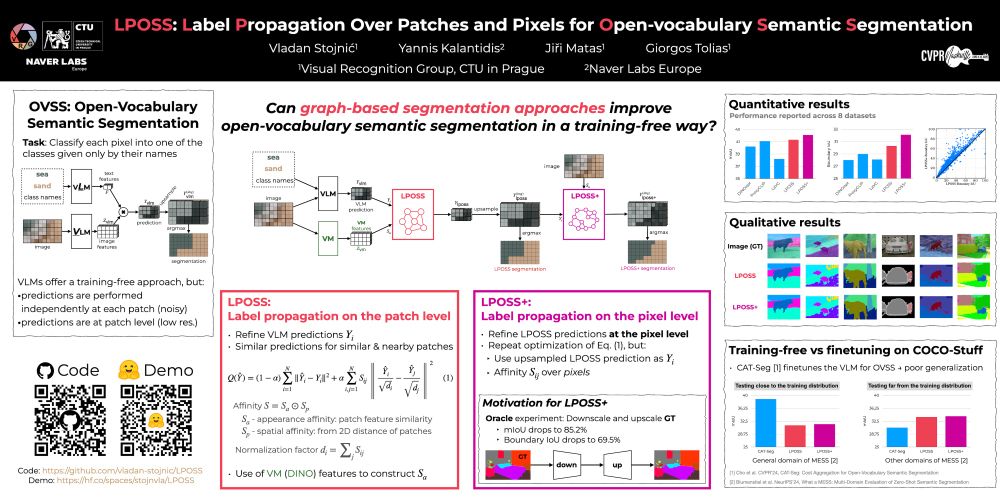
Reposted by Vladan Stojnić

Reposted by Vladan Stojnić

Reposted by Vladan Stojnić

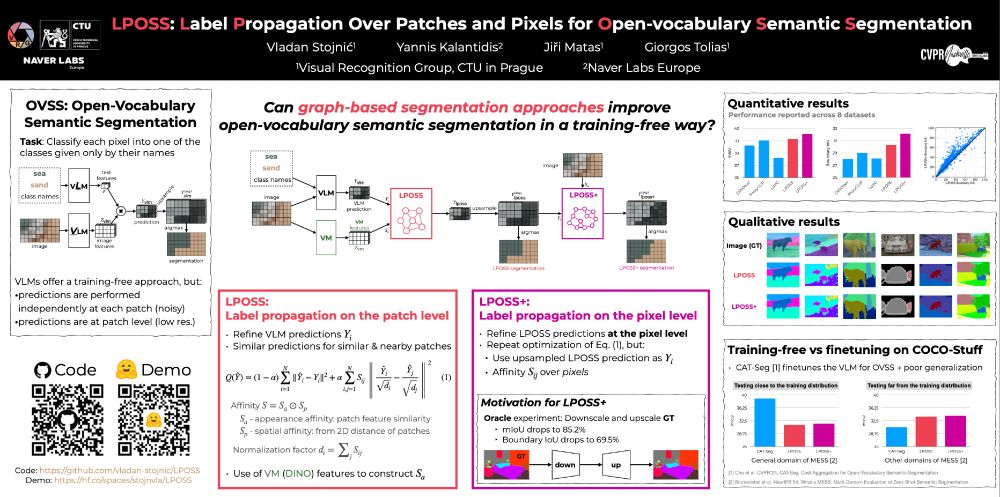
Reposted by Vladan Stojnić

