Yara Kyrychenko
@yarakyrychenko.bsky.social
280 followers
100 following
15 posts
PhD candidate @Cambridge @TheAlanTuringInstitute | Hope to make human-technology interactions more constructive | intergroup conflict, AI & LLMs, misinfo, social media | yarakyrychenko.github.io
Posts
Media
Videos
Starter Packs
Reposted by Yara Kyrychenko



Reposted by Yara Kyrychenko

Reposted by Yara Kyrychenko

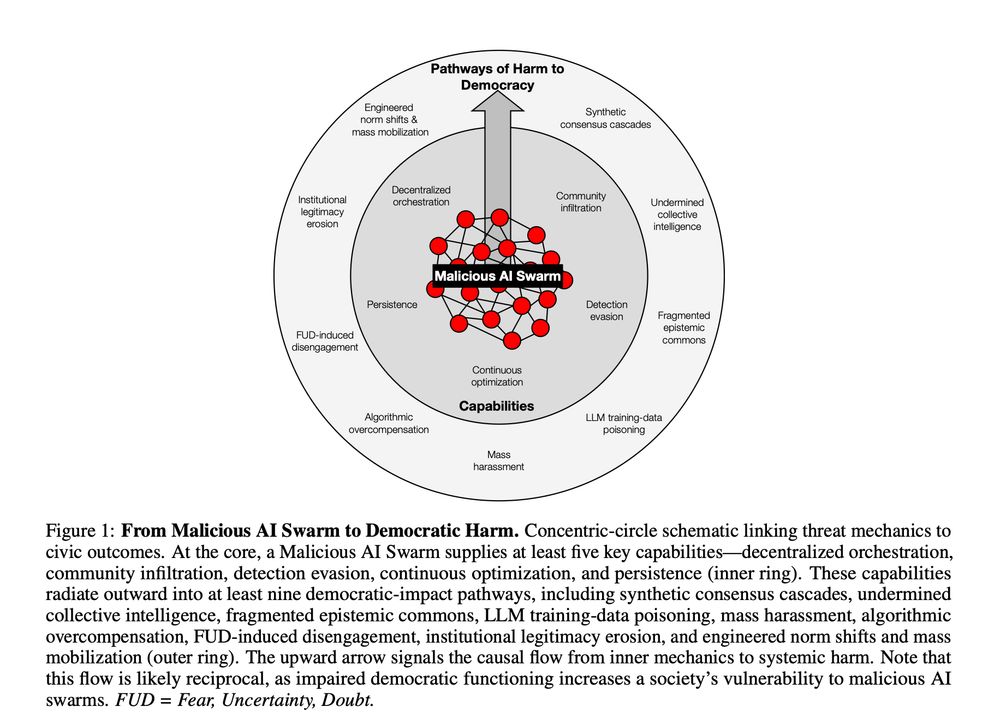



Reposted by Yara Kyrychenko


Reposted by Yara Kyrychenko


Reposted by Yara Kyrychenko

Reposted by Yara Kyrychenko

Reposted by Yara Kyrychenko

Mark Fabian
@markfabian.bsky.social
· Mar 30
Mark Fabian
@markfabian.bsky.social
· Mar 26

Would you ever trust a bot? - ePODstemology
Anyone on social media these days has encountered a bot. An algorithm-driven fake account that engages in some nefarious activity, whether it’s turning uncontroversial points into debates, repping the...
www.buzzsprout.com
Mark Fabian
@markfabian.bsky.social
· Mar 26
Would you ever trust a bot? - ePODstemology
Anyone on social media these days has encountered a bot. An algorithm-driven fake account that engages in some nefarious activity, whether it’s turning uncontroversial points into debates, repping the...
www.buzzsprout.com
Reposted by Yara Kyrychenko

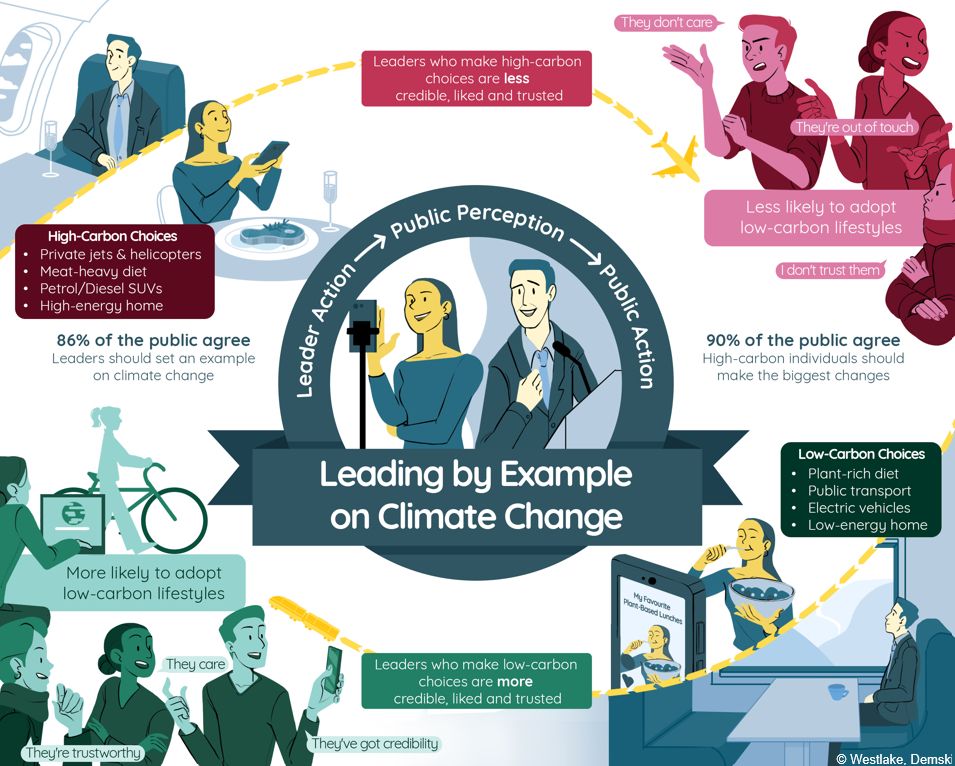
Reposted by Yara Kyrychenko


Reposted by Yara Kyrychenko


Reposted by Yara Kyrychenko


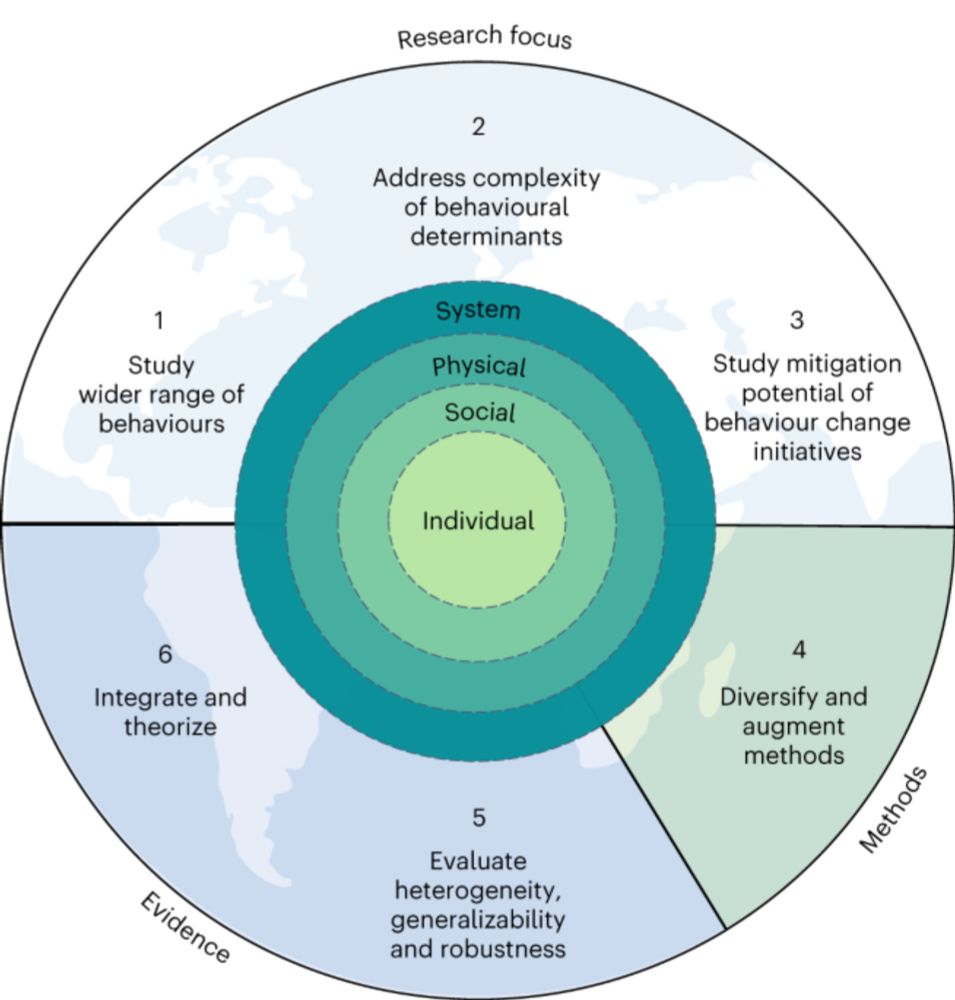
Reposted by Yara Kyrychenko

Reposted by Yara Kyrychenko


Reposted by Yara Kyrychenko

Scott McGrath
@smcgrath.phd
· Jan 23

Humanity's Last Exam
Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam, a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. The dataset consists of 3,000 challenging questions across over a hundred subjects. We publicly release these questions, while maintaining a private test set of held out questions to assess model overfitting.
lastexam.ai
Reposted by Yara Kyrychenko


Reposted by Yara Kyrychenko