



The 1.5B in this thing's name is how many parameters the model has - 1.5 billion
DeepSeek R1 comes in various sizes, but the 1.5B model is crap - you need to at least use the 7B to get reasonable results
GPT4 & 5 are estimated to have over a trillion
I've run 7B models locally on an 8Gb GPU btw
DeepSeek R1 comes in various sizes, but the 1.5B model is crap - you need to at least use the 7B to get reasonable results
GPT4 & 5 are estimated to have over a trillion
I've run 7B models locally on an 8Gb GPU btw

ICYMI: “.. rivaling or surpassing models hundreds of times its size, even outperforming Chinese rival DeepSeek's famed R1 that went viral at the start of this year ..”
(via @deanbaker13.bsky.social)
venturebeat.com/ai/weibos-ne...
(via @deanbaker13.bsky.social)
venturebeat.com/ai/weibos-ne...

November 19, 2025 at 2:02 PM
The 1.5B in this thing's name is how many parameters the model has - 1.5 billion
DeepSeek R1 comes in various sizes, but the 1.5B model is crap - you need to at least use the 7B to get reasonable results
GPT4 & 5 are estimated to have over a trillion
I've run 7B models locally on an 8Gb GPU btw
DeepSeek R1 comes in various sizes, but the 1.5B model is crap - you need to at least use the 7B to get reasonable results
GPT4 & 5 are estimated to have over a trillion
I've run 7B models locally on an 8Gb GPU btw

Instruct v0.2、Qwen 2.5 7B Instruct、Gemma 3 4B Instruct、DeepSeek-R1-Distill-Llama-8B 和 Apertus-8B-2509,发现他们开发的分类器能以 70%-80% 的准确率识别出 AI 生成的回复。
November 9, 2025 at 2:31 PM
Instruct v0.2、Qwen 2.5 7B Instruct、Gemma 3 4B Instruct、DeepSeek-R1-Distill-Llama-8B 和 Apertus-8B-2509,发现他们开发的分类器能以 70%-80% 的准确率识别出 AI 生成的回复。

Origin
ostatus.taiyolab.com
November 6, 2025 at 9:13 AM

deepseek-r1:7bはローカルと思えないほどの品質だけど、推論モデルの待ち時間はこの手のスニップレットに向かない。
November 6, 2025 at 9:08 AM
deepseek-r1:7bはローカルと思えないほどの品質だけど、推論モデルの待ち時間はこの手のスニップレットに向かない。

深度优化DeepSeek-R1-Distill-Qwen-7B模型:打造高效推理的生产力工具
https://qian.cx/posts/AA5F6A19-FE5B-42B1-9AB2-87DFA7D7FD8C
https://qian.cx/posts/AA5F6A19-FE5B-42B1-9AB2-87DFA7D7FD8C
October 28, 2025 at 7:35 PM
深度优化DeepSeek-R1-Distill-Qwen-7B模型:打造高效推理的生产力工具
https://qian.cx/posts/AA5F6A19-FE5B-42B1-9AB2-87DFA7D7FD8C
https://qian.cx/posts/AA5F6A19-FE5B-42B1-9AB2-87DFA7D7FD8C

Frustrating responses from my self-hosted #ai this morning. Still need to tune and figure out what model works best on my limited GPU. I use SearXNG for my web search, I think I should switch to Kagi since I pay for it.

October 20, 2025 at 3:15 PM
Frustrating responses from my self-hosted #ai this morning. Still need to tune and figure out what model works best on my limited GPU. I use SearXNG for my web search, I think I should switch to Kagi since I pay for it.

R‑Stitch, a training‑free hybrid decoding framework, routes tokens by entropy and achieves up to 4.10× speed‑up on QWQ‑32B and 3.00× on DeepSeek‑R1‑Distill‑Qwen‑7B. Read more: https://getnews.me/r-stitch-hybrid-decoding-speeds-up-large-language-model-reasoning/ #rstitch #llm

September 29, 2025 at 11:38 PM
R‑Stitch, a training‑free hybrid decoding framework, routes tokens by entropy and achieves up to 4.10× speed‑up on QWQ‑32B and 3.00× on DeepSeek‑R1‑Distill‑Qwen‑7B. Read more: https://getnews.me/r-stitch-hybrid-decoding-speeds-up-large-language-model-reasoning/ #rstitch #llm
Table‑R1 uses inference‑time scaling via DeepSeek‑R1 distillation and RL rewards. Its 7B‑parameter Table‑R1‑Zero matches or exceeds GPT‑4.1 on table reasoning, per EMNLP 2025. https://getnews.me/table-r1-advances-inference-time-scaling-for-table-reasoning/ #tablereasoning #llm #emnlp2025

September 29, 2025 at 10:12 PM
Table‑R1 uses inference‑time scaling via DeepSeek‑R1 distillation and RL rewards. Its 7B‑parameter Table‑R1‑Zero matches or exceeds GPT‑4.1 on table reasoning, per EMNLP 2025. https://getnews.me/table-r1-advances-inference-time-scaling-for-table-reasoning/ #tablereasoning #llm #emnlp2025

3/ The amount of energy and water used for every prompt increases with the size of the model, including higher pollution. Added to it,“reasoning” models increase accuracy, but use more tokens.
The industry logic is “more data = better AI”. This is unsustainable.
www.frontiersin.org/journals/com...
The industry logic is “more data = better AI”. This is unsustainable.
www.frontiersin.org/journals/com...

August 11, 2025 at 2:29 AM
3/ The amount of energy and water used for every prompt increases with the size of the model, including higher pollution. Added to it,“reasoning” models increase accuracy, but use more tokens.
The industry logic is “more data = better AI”. This is unsustainable.
www.frontiersin.org/journals/com...
The industry logic is “more data = better AI”. This is unsustainable.
www.frontiersin.org/journals/com...

🔥 LLM REVOLUTION
Switzerland's diving into open-source LLMs, blending transparency, sustainability & Web3 vibes. OLMo 7B & DeepSeek R1 are here to shake up AI's status quo.
Big tech's monopoly might be on the brink. Stay tuned!
Switzerland's diving into open-source LLMs, blending transparency, sustainability & Web3 vibes. OLMo 7B & DeepSeek R1 are here to shake up AI's status quo.
Big tech's monopoly might be on the brink. Stay tuned!
August 5, 2025 at 2:13 PM
🔥 LLM REVOLUTION
Switzerland's diving into open-source LLMs, blending transparency, sustainability & Web3 vibes. OLMo 7B & DeepSeek R1 are here to shake up AI's status quo.
Big tech's monopoly might be on the brink. Stay tuned!
Switzerland's diving into open-source LLMs, blending transparency, sustainability & Web3 vibes. OLMo 7B & DeepSeek R1 are here to shake up AI's status quo.
Big tech's monopoly might be on the brink. Stay tuned!

Do #AI models perform better as they do more chain-of-thought (#CoT) reasoning?
When is more reasoning no longer worth it?
This paper finds near-optimal results when CoT reasoning terminates ... almost immediately?
More reason to think CoT's overrated?
doi.org/10.48550/arX...
When is more reasoning no longer worth it?
This paper finds near-optimal results when CoT reasoning terminates ... almost immediately?
More reason to think CoT's overrated?
doi.org/10.48550/arX...
!["Figure 4: Accuracy of DeepSeek-R1-Distill-Qwen-7B vs. position where </think> is inserted. ... even early [termination] already yield hidden states highly similar to the final one—supporting the view that most useful reasoning content is distilled early, and extended CoT traces incur diminishing returns."](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:jf4udtyuylqocyyrqdwqoxuf/bafkreiahfbtychgcilgjlu7s2ggvft66bh45u2c6xboqutnf3m6pjz2l5a@jpeg)

August 1, 2025 at 11:12 AM
Do #AI models perform better as they do more chain-of-thought (#CoT) reasoning?
When is more reasoning no longer worth it?
This paper finds near-optimal results when CoT reasoning terminates ... almost immediately?
More reason to think CoT's overrated?
doi.org/10.48550/arX...
When is more reasoning no longer worth it?
This paper finds near-optimal results when CoT reasoning terminates ... almost immediately?
More reason to think CoT's overrated?
doi.org/10.48550/arX...

A ver, necesito ayuda: DeepSeek-R1-Distill-Qwen-14B o con DeepSeek-R1-Distill-Qwen-7B tengo bastante? La tarea es bastante idiota pero necesito que piense y planifique bien. Algún super experto en LLMs que me eche una manita... 😔
July 25, 2025 at 7:06 PM
A ver, necesito ayuda: DeepSeek-R1-Distill-Qwen-14B o con DeepSeek-R1-Distill-Qwen-7B tengo bastante? La tarea es bastante idiota pero necesito que piense y planifique bien. Algún super experto en LLMs que me eche una manita... 😔

Congrats Moonshot on making a "modified X" license that's still open source.
This is also making me wonder about the list of models to hold the title "most powerful open source LLM in the world." GPT-2 > GPT-Neo > GPT-J > FairSeq Dense > GPT-NeoX-20B > MPT-7B > Falcon-40B > ??? > DeepSeek-R1
This is also making me wonder about the list of models to hold the title "most powerful open source LLM in the world." GPT-2 > GPT-Neo > GPT-J > FairSeq Dense > GPT-NeoX-20B > MPT-7B > Falcon-40B > ??? > DeepSeek-R1
July 23, 2025 at 11:15 AM
Congrats Moonshot on making a "modified X" license that's still open source.
This is also making me wonder about the list of models to hold the title "most powerful open source LLM in the world." GPT-2 > GPT-Neo > GPT-J > FairSeq Dense > GPT-NeoX-20B > MPT-7B > Falcon-40B > ??? > DeepSeek-R1
This is also making me wonder about the list of models to hold the title "most powerful open source LLM in the world." GPT-2 > GPT-Neo > GPT-J > FairSeq Dense > GPT-NeoX-20B > MPT-7B > Falcon-40B > ??? > DeepSeek-R1
英伟达推出 OpenReasoning-Nemotron 推理模型,普通游戏电脑也能玩转高级推理 IT之家 7 月 20 日消息,英伟达今日推出了全新推理模型套件 OpenReasoning-Nemotron。该套件包含四个基于 Qwen-2.5 微调的模型,参数规模分别为 1.5B、7B、14B 和 32B,全部源自 6710 亿参数的 DeepSeek R1 0528 大模型。通过“蒸馏”这一过程,英伟达成功将这一超大规模模型压缩成更轻量的推理模型,降低了部署门槛...
Interest | Match | Feed
Interest | Match | Feed
Origin
www.ithome.com
July 20, 2025 at 11:30 AM

Nvidia released a series of OpenReasoning-Nemotron models (1.5B, 7B, 14B and 32B) that set new SOTA on a wide range of reasoning benchmarks across open-weight models of corresponding size.
The models are based on Qwen2.5 architecture, trained with SFT on the data generated with DeepSeek-R1-0528.
The models are based on Qwen2.5 architecture, trained with SFT on the data generated with DeepSeek-R1-0528.

July 20, 2025 at 12:16 AM
Nvidia released a series of OpenReasoning-Nemotron models (1.5B, 7B, 14B and 32B) that set new SOTA on a wide range of reasoning benchmarks across open-weight models of corresponding size.
The models are based on Qwen2.5 architecture, trained with SFT on the data generated with DeepSeek-R1-0528.
The models are based on Qwen2.5 architecture, trained with SFT on the data generated with DeepSeek-R1-0528.

Bytedance SEED-X: a 7B that beats Gemini-2.5-pro on language translation
- reasoning model
- pre-trained on 6T tokens
- structured like a mistral
it's entire pre-training dataset is oriented around language translation, often using bilingual samples
- reasoning model
- pre-trained on 6T tokens
- structured like a mistral
it's entire pre-training dataset is oriented around language translation, often using bilingual samples

July 18, 2025 at 3:18 PM
Bytedance SEED-X: a 7B that beats Gemini-2.5-pro on language translation
- reasoning model
- pre-trained on 6T tokens
- structured like a mistral
it's entire pre-training dataset is oriented around language translation, often using bilingual samples
- reasoning model
- pre-trained on 6T tokens
- structured like a mistral
it's entire pre-training dataset is oriented around language translation, often using bilingual samples

Multi-game magic:
Single game: ~41% reasoning average
Multi-game: 42.7% - skills synergize!
Even strong models improve:
DeepSeek-R1-Distill-Qwen-7B jumps 59.7%→61.7%. AIME'25 +10 points! 📈
Single game: ~41% reasoning average
Multi-game: 42.7% - skills synergize!
Even strong models improve:
DeepSeek-R1-Distill-Qwen-7B jumps 59.7%→61.7%. AIME'25 +10 points! 📈
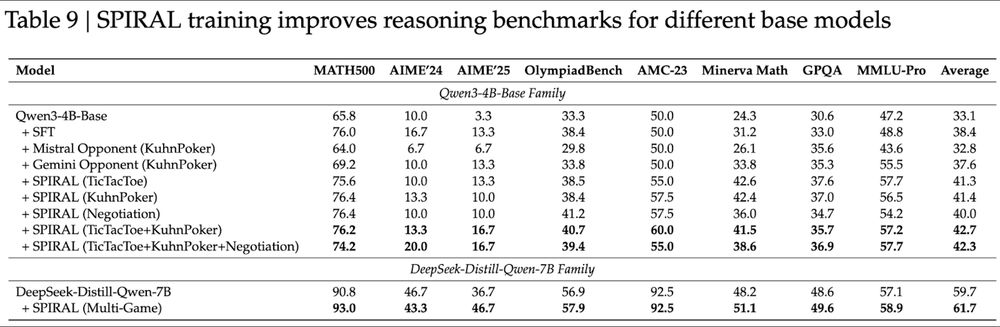
July 1, 2025 at 8:11 PM
Multi-game magic:
Single game: ~41% reasoning average
Multi-game: 42.7% - skills synergize!
Even strong models improve:
DeepSeek-R1-Distill-Qwen-7B jumps 59.7%→61.7%. AIME'25 +10 points! 📈
Single game: ~41% reasoning average
Multi-game: 42.7% - skills synergize!
Even strong models improve:
DeepSeek-R1-Distill-Qwen-7B jumps 59.7%→61.7%. AIME'25 +10 points! 📈

[30/30] 192 Likes, 2 Comments, 3 Posts
2506.04178, cs․LG, 05 Jun 2025
🆕OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, ...
2506.04178, cs․LG, 05 Jun 2025
🆕OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, ...

June 28, 2025 at 12:06 AM
[30/30] 192 Likes, 2 Comments, 3 Posts
2506.04178, cs․LG, 05 Jun 2025
🆕OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, ...
2506.04178, cs․LG, 05 Jun 2025
🆕OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, ...

Deepseek r1 running on a thinkpad p52. Couldn't believe my eyes when the 32b model not only loaded but also ran! At only 1.5 tokens tough, the 8b model is what i consider the best in speed to answer ratio at 10 token per second.



June 16, 2025 at 4:40 PM
Deepseek r1 running on a thinkpad p52. Couldn't believe my eyes when the 32b model not only loaded but also ran! At only 1.5 tokens tough, the 8b model is what i consider the best in speed to answer ratio at 10 token per second.

😭 Mais alors, pour ce qui est du modèle LLM, là, je suis à poil. Je tâtonne entre deepseek-r1, deepseek-coder, les version 1.3b, 1.5b, 7b (qui semble être la limite de mon Macbook Pro M2 Max 64Go no-GPU), codellama:7b-instruct, ollama-3.1:8b, codestral:22b, qwen2.5-coder:1.5b-base etc. 💥
Un avis ?
Un avis ?
June 14, 2025 at 5:32 PM
😭 Mais alors, pour ce qui est du modèle LLM, là, je suis à poil. Je tâtonne entre deepseek-r1, deepseek-coder, les version 1.3b, 1.5b, 7b (qui semble être la limite de mon Macbook Pro M2 Max 64Go no-GPU), codellama:7b-instruct, ollama-3.1:8b, codestral:22b, qwen2.5-coder:1.5b-base etc. 💥
Un avis ?
Un avis ?

approach across models on DeepSeek-R1-Distill-7B and DeepSeek-R1-Distill-14B and on a diverse set of benchmarks with varying difficulty levels. Our method significantly reduces the number of output tokens by nearly 40% while maintaining the accuracy [4/5 of https://arxiv.org/abs/2506.02678v1]
June 4, 2025 at 6:07 AM
approach across models on DeepSeek-R1-Distill-7B and DeepSeek-R1-Distill-14B and on a diverse set of benchmarks with varying difficulty levels. Our method significantly reduces the number of output tokens by nearly 40% while maintaining the accuracy [4/5 of https://arxiv.org/abs/2506.02678v1]

for external verifiers. We train our self-verification models based on Qwen2.5-Math-7B and DeepSeek-R1-Distill-Qwen-1.5B, demonstrating its capabilities across varying reasoning context lengths. Experiments on multiple mathematical reasoning [5/6 of https://arxiv.org/abs/2506.01369v1]
June 3, 2025 at 6:34 AM
for external verifiers. We train our self-verification models based on Qwen2.5-Math-7B and DeepSeek-R1-Distill-Qwen-1.5B, demonstrating its capabilities across varying reasoning context lengths. Experiments on multiple mathematical reasoning [5/6 of https://arxiv.org/abs/2506.01369v1]