



ooh, that was about duckplyr vs. dbplyr, not dbi vs. dbplyr. :)
December 29, 2025 at 6:25 PM
ooh, that was about duckplyr vs. dbplyr, not dbi vs. dbplyr. :)
I did not do a deep dive into the gap between dbGetQuery and dbplyr and this was six months ago. My preference was usually to use dbplyr/duckplyr as much as possible unless I couldn't. Did not stop to do a larger analysis on the gaps.
December 29, 2025 at 6:24 PM
I did not do a deep dive into the gap between dbGetQuery and dbplyr and this was six months ago. My preference was usually to use dbplyr/duckplyr as much as possible unless I couldn't. Did not stop to do a larger analysis on the gaps.
Not sure I follow. The gist of my tips was about connection management, not DBI vs. dbplyr. Regardless of whether you use DBI methods or dplyr semantics you still have to deal with connections. I also pointed out duckplyr is available, but I did find situations I could not easily use dbplyr
December 29, 2025 at 6:23 PM
Not sure I follow. The gist of my tips was about connection management, not DBI vs. dbplyr. Regardless of whether you use DBI methods or dplyr semantics you still have to deal with connections. I also pointed out duckplyr is available, but I did find situations I could not easily use dbplyr

neat.
I notice somebody asked for a python version on the duckplyr github and they recommended ibis ibis-project.org/posts/ibis-d... which seems like it's probably the answer im looking for (!) (cc @urschrei.bsky.social , @jreades.bsky.social , @urbandemog.bsky.social )
I notice somebody asked for a python version on the duckplyr github and they recommended ibis ibis-project.org/posts/ibis-d... which seems like it's probably the answer im looking for (!) (cc @urschrei.bsky.social , @jreades.bsky.social , @urbandemog.bsky.social )

Ibis
the portable Python dataframe library
ibis-project.org
December 14, 2025 at 6:00 PM
neat.
I notice somebody asked for a python version on the duckplyr github and they recommended ibis ibis-project.org/posts/ibis-d... which seems like it's probably the answer im looking for (!) (cc @urschrei.bsky.social , @jreades.bsky.social , @urbandemog.bsky.social )
I notice somebody asked for a python version on the duckplyr github and they recommended ibis ibis-project.org/posts/ibis-d... which seems like it's probably the answer im looking for (!) (cc @urschrei.bsky.social , @jreades.bsky.social , @urbandemog.bsky.social )
yeah thats what i was thinking. sqlalchemy lets you treat sql as first-class python, but you still need to write the 'translation layer' to the DB yourself whereas duckplyr/duckspatial seems to give you that for free (if im understanding it). I can see why that's really appealing
December 14, 2025 at 5:13 PM
yeah thats what i was thinking. sqlalchemy lets you treat sql as first-class python, but you still need to write the 'translation layer' to the DB yourself whereas duckplyr/duckspatial seems to give you that for free (if im understanding it). I can see why that's really appealing

Lol. I understand you, though. There are convenient ways of using duckdb in R with {duckplyr} and {duckspatial}. I'm sure something similar should be created in Python soon
December 13, 2025 at 5:58 PM
Lol. I understand you, though. There are convenient ways of using duckdb in R with {duckplyr} and {duckspatial}. I'm sure something similar should be created in Python soon

#30DayMapChallenge Day 16: Cell
LINZ ground LIDAR point cloud data for Ōtepoti (13.64 points per m²) & showing the commonest classification in each 10 square metres (so some Duckplyr in #rstats to crunch that out). It looks like the the classification is partially sensitive to the sweep reading
LINZ ground LIDAR point cloud data for Ōtepoti (13.64 points per m²) & showing the commonest classification in each 10 square metres (so some Duckplyr in #rstats to crunch that out). It looks like the the classification is partially sensitive to the sweep reading
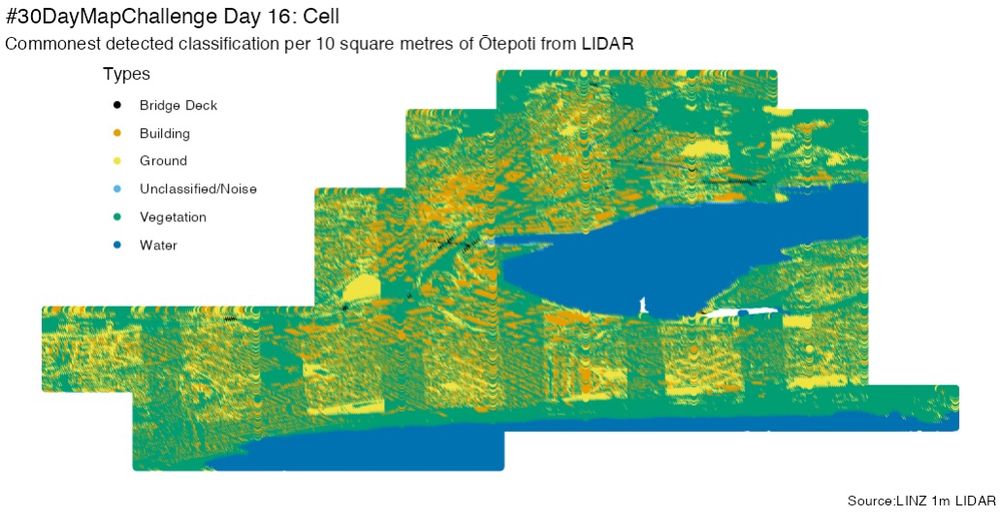
November 16, 2025 at 1:52 AM
#30DayMapChallenge Day 16: Cell
LINZ ground LIDAR point cloud data for Ōtepoti (13.64 points per m²) & showing the commonest classification in each 10 square metres (so some Duckplyr in #rstats to crunch that out). It looks like the the classification is partially sensitive to the sweep reading
LINZ ground LIDAR point cloud data for Ōtepoti (13.64 points per m²) & showing the commonest classification in each 10 square metres (so some Duckplyr in #rstats to crunch that out). It looks like the the classification is partially sensitive to the sweep reading

This article shows how duckplyr can be used instead of dplyr, providing very fast results with very huge datasets. #rstats #programming
tidyverse.org/blog/2025/06...
tidyverse.org/blog/2025/06...

duckplyr fully joins the tidyverse!
duckplyr 1.1.0 is on CRAN! A drop-in replacement for dplyr, powered by DuckDB for speed. It is the most dplyr-like of dplyr backends.
tidyverse.org
November 11, 2025 at 3:55 PM
This article shows how duckplyr can be used instead of dplyr, providing very fast results with very huge datasets. #rstats #programming
tidyverse.org/blog/2025/06...
tidyverse.org/blog/2025/06...

14/
Full blog post:
www.tidyverse.org/blog/2025/0...
duckplyr 1.1.0: now part of the tidyverse.
Familiar. Blazing fast. Made for modern data.
Full blog post:
www.tidyverse.org/blog/2025/0...
duckplyr 1.1.0: now part of the tidyverse.
Familiar. Blazing fast. Made for modern data.

duckplyr fully joins the tidyverse!
duckplyr 1.1.0 is on CRAN! A drop-in replacement for dplyr, powered by DuckDB for speed. It is the most dplyr-like of dplyr backends.
www.tidyverse.org
November 11, 2025 at 2:45 PM
14/
Full blog post:
www.tidyverse.org/blog/2025/0...
duckplyr 1.1.0: now part of the tidyverse.
Familiar. Blazing fast. Made for modern data.
Full blog post:
www.tidyverse.org/blog/2025/0...
duckplyr 1.1.0: now part of the tidyverse.
Familiar. Blazing fast. Made for modern data.
13/
Install it now:
install.packages("duckplyr")
Start using your dplyr code—at DuckDB speed.
Install it now:
install.packages("duckplyr")
Start using your dplyr code—at DuckDB speed.
November 11, 2025 at 2:45 PM
13/
Install it now:
install.packages("duckplyr")
Start using your dplyr code—at DuckDB speed.
Install it now:
install.packages("duckplyr")
Start using your dplyr code—at DuckDB speed.
12/
Warning: duckplyr is fast, but R might not show memory usage correctly.
Always monitor RAM if you're near the limit.
Warning: duckplyr is fast, but R might not show memory usage correctly.
Always monitor RAM if you're near the limit.
November 11, 2025 at 2:45 PM
12/
Warning: duckplyr is fast, but R might not show memory usage correctly.
Always monitor RAM if you're near the limit.
Warning: duckplyr is fast, but R might not show memory usage correctly.
Always monitor RAM if you're near the limit.
11/
duckplyr tracks fallbacks.
You can review them and submit reports—help make it smarter.
Every fallback is a future speed boost.
duckplyr tracks fallbacks.
You can review them and submit reports—help make it smarter.
Every fallback is a future speed boost.
November 11, 2025 at 2:45 PM
11/
duckplyr tracks fallbacks.
You can review them and submit reports—help make it smarter.
Every fallback is a future speed boost.
duckplyr tracks fallbacks.
You can review them and submit reports—help make it smarter.
Every fallback is a future speed boost.
10/
If you use dbplyr, good news:
duckplyr plays nice.
Convert duck frames to lazy dbplyr tables and back in one line.
If you use dbplyr, good news:
duckplyr plays nice.
Convert duck frames to lazy dbplyr tables and back in one line.
November 11, 2025 at 2:45 PM
10/
If you use dbplyr, good news:
duckplyr plays nice.
Convert duck frames to lazy dbplyr tables and back in one line.
If you use dbplyr, good news:
duckplyr plays nice.
Convert duck frames to lazy dbplyr tables and back in one line.
9/
Need SQL-like power?
Use DuckDB functions right inside duckplyr pipelines with dd$.
Yes, even Levenshtein distance.
Need SQL-like power?
Use DuckDB functions right inside duckplyr pipelines with dd$.
Yes, even Levenshtein distance.
November 11, 2025 at 2:45 PM
9/
Need SQL-like power?
Use DuckDB functions right inside duckplyr pipelines with dd$.
Yes, even Levenshtein distance.
Need SQL-like power?
Use DuckDB functions right inside duckplyr pipelines with dd$.
Yes, even Levenshtein distance.
8/
Got data too big for RAM?
duckplyr works out-of-memory.
Read/write Parquet. Process directly from disk. It just works.
Got data too big for RAM?
duckplyr works out-of-memory.
Read/write Parquet. Process directly from disk. It just works.
November 11, 2025 at 2:45 PM
8/
Got data too big for RAM?
duckplyr works out-of-memory.
Read/write Parquet. Process directly from disk. It just works.
Got data too big for RAM?
duckplyr works out-of-memory.
Read/write Parquet. Process directly from disk. It just works.
7/
Example:
library(duckplyr)
df <- as_duckplyr_df(bigdata)
df |> filter(x > 10) |> group_by(y) |> summarise(n = n())
Familiar code. Faster engine.
Example:
library(duckplyr)
df <- as_duckplyr_df(bigdata)
df |> filter(x > 10) |> group_by(y) |> summarise(n = n())
Familiar code. Faster engine.
November 11, 2025 at 2:45 PM
7/
Example:
library(duckplyr)
df <- as_duckplyr_df(bigdata)
df |> filter(x > 10) |> group_by(y) |> summarise(n = n())
Familiar code. Faster engine.
Example:
library(duckplyr)
df <- as_duckplyr_df(bigdata)
df |> filter(x > 10) |> group_by(y) |> summarise(n = n())
Familiar code. Faster engine.
6/
Use it two ways:
Load duckplyr to override dplyr globally
Or just convert specific data frames with as_duckplyr_df()
Use it two ways:
Load duckplyr to override dplyr globally
Or just convert specific data frames with as_duckplyr_df()
November 11, 2025 at 2:45 PM
6/
Use it two ways:
Load duckplyr to override dplyr globally
Or just convert specific data frames with as_duckplyr_df()
Use it two ways:
Load duckplyr to override dplyr globally
Or just convert specific data frames with as_duckplyr_df()
5/
When DuckDB can’t handle something, duckplyr falls back to dplyr.
Same results. Always.
It’s safe to try.
When DuckDB can’t handle something, duckplyr falls back to dplyr.
Same results. Always.
It’s safe to try.
November 11, 2025 at 2:45 PM
5/
When DuckDB can’t handle something, duckplyr falls back to dplyr.
Same results. Always.
It’s safe to try.
When DuckDB can’t handle something, duckplyr falls back to dplyr.
Same results. Always.
It’s safe to try.
4/
duckplyr handles huge datasets with ease.
6M rows?
10× faster than dplyr in benchmarks.
Less memory. Less time. No sweat.
duckplyr handles huge datasets with ease.
6M rows?
10× faster than dplyr in benchmarks.
Less memory. Less time. No sweat.
November 11, 2025 at 2:45 PM
4/
duckplyr handles huge datasets with ease.
6M rows?
10× faster than dplyr in benchmarks.
Less memory. Less time. No sweat.
duckplyr handles huge datasets with ease.
6M rows?
10× faster than dplyr in benchmarks.
Less memory. Less time. No sweat.
2/
duckplyr is a drop-in replacement for dplyr.
Same code. Same verbs.
But it runs on DuckDB under the hood—for serious speed.
duckplyr is a drop-in replacement for dplyr.
Same code. Same verbs.
But it runs on DuckDB under the hood—for serious speed.
November 11, 2025 at 2:45 PM
2/
duckplyr is a drop-in replacement for dplyr.
Same code. Same verbs.
But it runs on DuckDB under the hood—for serious speed.
duckplyr is a drop-in replacement for dplyr.
Same code. Same verbs.
But it runs on DuckDB under the hood—for serious speed.
1/ Working with big data in R?
Your wrangling just got a massive upgrade.
duckplyr is now in the tidyverse—and it’s fast. Really fast. 🧵
Your wrangling just got a massive upgrade.
duckplyr is now in the tidyverse—and it’s fast. Really fast. 🧵

November 11, 2025 at 2:45 PM
1/ Working with big data in R?
Your wrangling just got a massive upgrade.
duckplyr is now in the tidyverse—and it’s fast. Really fast. 🧵
Your wrangling just got a massive upgrade.
duckplyr is now in the tidyverse—and it’s fast. Really fast. 🧵
10/
Trick example: DelayedArray. Duckplyr with DuckDB
R can now work on chunks of data, lazily, like Python’s dask or pandas.read_csv(chunksize=…).
Trick example: DelayedArray. Duckplyr with DuckDB
R can now work on chunks of data, lazily, like Python’s dask or pandas.read_csv(chunksize=…).
November 9, 2025 at 2:15 PM
10/
Trick example: DelayedArray. Duckplyr with DuckDB
R can now work on chunks of data, lazily, like Python’s dask or pandas.read_csv(chunksize=…).
Trick example: DelayedArray. Duckplyr with DuckDB
R can now work on chunks of data, lazily, like Python’s dask or pandas.read_csv(chunksize=…).

Updates on CRAN: BlueCarbon (0.1.1), duckplyr (1.1.3)
November 4, 2025 at 1:35 PM
Updates on CRAN: BlueCarbon (0.1.1), duckplyr (1.1.3)


⚡ Results:
* dplyr: ~12–80s 🐢
* duckplyr: ~2–10s 🚀
* polars: ~1.8–10s 🚀🚀
* dbplyr: 47–171s 😬 (but i'm probably bad at it)
💾 Memory:
* dplyr: up to 2,099 MB
* dbplyr: ~2 GB
* duckplyr: up to 675 MB
* polars: as low as 35 MB ✨
* dplyr: ~12–80s 🐢
* duckplyr: ~2–10s 🚀
* polars: ~1.8–10s 🚀🚀
* dbplyr: 47–171s 😬 (but i'm probably bad at it)
💾 Memory:
* dplyr: up to 2,099 MB
* dbplyr: ~2 GB
* duckplyr: up to 675 MB
* polars: as low as 35 MB ✨
October 28, 2025 at 12:04 PM
⚡ Results:
* dplyr: ~12–80s 🐢
* duckplyr: ~2–10s 🚀
* polars: ~1.8–10s 🚀🚀
* dbplyr: 47–171s 😬 (but i'm probably bad at it)
💾 Memory:
* dplyr: up to 2,099 MB
* dbplyr: ~2 GB
* duckplyr: up to 675 MB
* polars: as low as 35 MB ✨
* dplyr: ~12–80s 🐢
* duckplyr: ~2–10s 🚀
* polars: ~1.8–10s 🚀🚀
* dbplyr: 47–171s 😬 (but i'm probably bad at it)
💾 Memory:
* dplyr: up to 2,099 MB
* dbplyr: ~2 GB
* duckplyr: up to 675 MB
* polars: as low as 35 MB ✨