




Caleb Ziems
@calebziems.com
PhD student at Stanford NLP. Working on Social NLP and CSS. Previously at GaTech, Meta AI, Emory.
📍Palo Alto, CA
🔗 calebziems.com
📍Palo Alto, CA
🔗 calebziems.com
Can we map out gaps in LLMs’ cultural knowledge?
Check out our #EMNLP2025 talk: Culture Cartography
🗓️ 11/5, 11:30 AM
📌 A109 (CSS Orals 1)
Compared to traditional benchmarking, our mixed-initiative method finds more knowledge gaps even in reasoning models like R1!
Paper: arxiv.org/pdf/2510.27672
Check out our #EMNLP2025 talk: Culture Cartography
🗓️ 11/5, 11:30 AM
📌 A109 (CSS Orals 1)
Compared to traditional benchmarking, our mixed-initiative method finds more knowledge gaps even in reasoning models like R1!
Paper: arxiv.org/pdf/2510.27672

November 4, 2025 at 5:31 PM
Can we map out gaps in LLMs’ cultural knowledge?
Check out our #EMNLP2025 talk: Culture Cartography
🗓️ 11/5, 11:30 AM
📌 A109 (CSS Orals 1)
Compared to traditional benchmarking, our mixed-initiative method finds more knowledge gaps even in reasoning models like R1!
Paper: arxiv.org/pdf/2510.27672
Check out our #EMNLP2025 talk: Culture Cartography
🗓️ 11/5, 11:30 AM
📌 A109 (CSS Orals 1)
Compared to traditional benchmarking, our mixed-initiative method finds more knowledge gaps even in reasoning models like R1!
Paper: arxiv.org/pdf/2510.27672
Reposted by Caleb Ziems

AI always calling your ideas “fantastic” can feel inauthentic, but what are sycophancy’s deeper harms? We find that in the common use case of seeking AI advice on interpersonal situations—specifically conflicts—sycophancy makes people feel more right & less willing to apologize.

October 3, 2025 at 10:53 PM
AI always calling your ideas “fantastic” can feel inauthentic, but what are sycophancy’s deeper harms? We find that in the common use case of seeking AI advice on interpersonal situations—specifically conflicts—sycophancy makes people feel more right & less willing to apologize.
Reposted by Caleb Ziems

I am so excited to be in 🇬🇷Athens🇬🇷 to present "A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms" by me, @kizilcec.bsky.social, and @allisonkoe.bsky.social, at #FAccT2025!!
🔗: arxiv.org/pdf/2506.04419
🔗: arxiv.org/pdf/2506.04419

June 23, 2025 at 2:45 PM
I am so excited to be in 🇬🇷Athens🇬🇷 to present "A Framework for Auditing Chatbots for Dialect-Based Quality-of-Service Harms" by me, @kizilcec.bsky.social, and @allisonkoe.bsky.social, at #FAccT2025!!
🔗: arxiv.org/pdf/2506.04419
🔗: arxiv.org/pdf/2506.04419
Reposted by Caleb Ziems

AI companions aren’t science fiction anymore 🤖💬❤️
Thousands are turning to AI chatbots for emotional connection – finding comfort, sharing secrets, and even falling in love. But as AI companionship grows, the line between real and artificial relationships blurs.
Thousands are turning to AI chatbots for emotional connection – finding comfort, sharing secrets, and even falling in love. But as AI companionship grows, the line between real and artificial relationships blurs.

June 18, 2025 at 4:27 PM
AI companions aren’t science fiction anymore 🤖💬❤️
Thousands are turning to AI chatbots for emotional connection – finding comfort, sharing secrets, and even falling in love. But as AI companionship grows, the line between real and artificial relationships blurs.
Thousands are turning to AI chatbots for emotional connection – finding comfort, sharing secrets, and even falling in love. But as AI companionship grows, the line between real and artificial relationships blurs.
Reposted by Caleb Ziems

Introducing CAVA: The Comprehensive Assessment for Voice Assistants
A new benchmark for evaluating the capabilities required for speech-in-speech-out voice assistants!
- Latency
- Instruction following
- Function calling
- Tone awareness
- Turn taking
- Audio Safety
TalkArena.org/cava
A new benchmark for evaluating the capabilities required for speech-in-speech-out voice assistants!
- Latency
- Instruction following
- Function calling
- Tone awareness
- Turn taking
- Audio Safety
TalkArena.org/cava
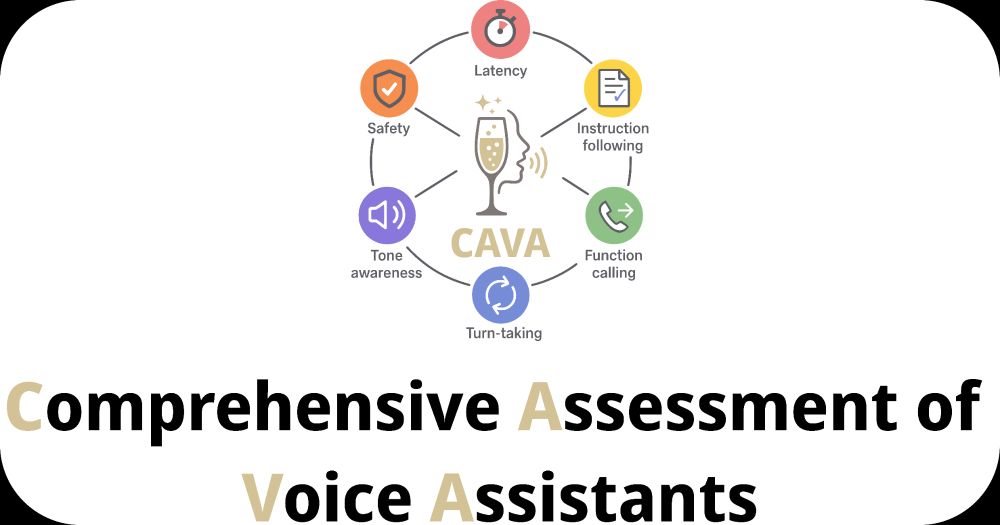
Comprehensive Assessment for Voice Assistants
CAVA is a new benchmark for assessing how well Large Audio Models support voice assistant capabilities.
TalkArena.org
May 7, 2025 at 4:15 PM
Introducing CAVA: The Comprehensive Assessment for Voice Assistants
A new benchmark for evaluating the capabilities required for speech-in-speech-out voice assistants!
- Latency
- Instruction following
- Function calling
- Tone awareness
- Turn taking
- Audio Safety
TalkArena.org/cava
A new benchmark for evaluating the capabilities required for speech-in-speech-out voice assistants!
- Latency
- Instruction following
- Function calling
- Tone awareness
- Turn taking
- Audio Safety
TalkArena.org/cava
Reposted by Caleb Ziems

Reward models for LMs are meant to align outputs with human preferences—but do they accidentally encode dialect biases? 🤔
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)

March 6, 2025 at 7:49 PM
Reward models for LMs are meant to align outputs with human preferences—but do they accidentally encode dialect biases? 🤔
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
Excited to share our paper on biases against African American Language in reward models, accepted to #NAACL2025 Findings! 🎉
Paper: arxiv.org/abs/2502.12858 (1/10)
EgoNormia (egonormia.org) exposes a major gap in Vision-Language Models understanding of the social world: they don't know how to behave when norms about the physical world *conflict* ⚔️ (<45% acc.)
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
March 4, 2025 at 4:44 AM
EgoNormia (egonormia.org) exposes a major gap in Vision-Language Models understanding of the social world: they don't know how to behave when norms about the physical world *conflict* ⚔️ (<45% acc.)
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
But humans are naturally quite good at this (>90% acc.)
Check it out!
➡️ arxiv.org/abs/2502.20490
Reposted by Caleb Ziems

There's been a lot of work on "culture" in NLP, but not much agreement on what it is.
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n

February 18, 2025 at 8:45 PM
There's been a lot of work on "culture" in NLP, but not much agreement on what it is.
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n
Reposted by Caleb Ziems

LM agents today primarily aim to automate tasks. Can we turn them into collaborative teammates? 🤖➕👤
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)

January 17, 2025 at 5:44 PM
LM agents today primarily aim to automate tasks. Can we turn them into collaborative teammates? 🤖➕👤
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)
Reposted by Caleb Ziems

Bill Labov died this morning. I'm not coherent enough to talk about how important and influential and brilliant he was. I am very sad.
I was so lucky to know him, and I am grateful every day that he (and Gillian, and Walt, etc) built an academic field where kindness is expected.
I was so lucky to know him, and I am grateful every day that he (and Gillian, and Walt, etc) built an academic field where kindness is expected.
December 18, 2024 at 2:08 AM
Bill Labov died this morning. I'm not coherent enough to talk about how important and influential and brilliant he was. I am very sad.
I was so lucky to know him, and I am grateful every day that he (and Gillian, and Walt, etc) built an academic field where kindness is expected.
I was so lucky to know him, and I am grateful every day that he (and Gillian, and Walt, etc) built an academic field where kindness is expected.
Reposted by Caleb Ziems
With an increasing number of Large *Audio* Models 🔊, which one do users like the most?
Introducing talkarena.org — an open platform where users speak to LAMs and receive text responses. Through open interaction, we focus on rankings based on user preferences rather than static benchmarks.
🧵 (1/5)
Introducing talkarena.org — an open platform where users speak to LAMs and receive text responses. Through open interaction, we focus on rankings based on user preferences rather than static benchmarks.
🧵 (1/5)

December 10, 2024 at 12:01 AM
With an increasing number of Large *Audio* Models 🔊, which one do users like the most?
Introducing talkarena.org — an open platform where users speak to LAMs and receive text responses. Through open interaction, we focus on rankings based on user preferences rather than static benchmarks.
🧵 (1/5)
Introducing talkarena.org — an open platform where users speak to LAMs and receive text responses. Through open interaction, we focus on rankings based on user preferences rather than static benchmarks.
🧵 (1/5)
Maybe some starter packs for the Dyirbal noun classes?
1. most animate objects, men
2. women, water, fire, violence, and exceptional animals
3. edible fruit and vegetables
4. miscellaneous (includes things not classifiable in the first three)
1. most animate objects, men
2. women, water, fire, violence, and exceptional animals
3. edible fruit and vegetables
4. miscellaneous (includes things not classifiable in the first three)

Some starter packs I plan to do when I get around to it

November 24, 2024 at 5:53 PM
Maybe some starter packs for the Dyirbal noun classes?
1. most animate objects, men
2. women, water, fire, violence, and exceptional animals
3. edible fruit and vegetables
4. miscellaneous (includes things not classifiable in the first three)
1. most animate objects, men
2. women, water, fire, violence, and exceptional animals
3. edible fruit and vegetables
4. miscellaneous (includes things not classifiable in the first three)
Reposted by Caleb Ziems

Hi Bluesky! You get to be the very first internet people to see my standup comedy debut. Because I know you’ll be nicer to me than the 12 year olds on TikTok. youtu.be/KqL2ahOvAgg?...

AI is not the GOAT. (Uh oh, your professor is attempting stand up comedy.)
YouTube video by Casey Fiesler
youtu.be
November 23, 2024 at 6:52 PM
Hi Bluesky! You get to be the very first internet people to see my standup comedy debut. Because I know you’ll be nicer to me than the 12 year olds on TikTok. youtu.be/KqL2ahOvAgg?...
Reposted by Caleb Ziems

I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
November 23, 2024 at 7:54 PM
I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Reposted by Caleb Ziems

I'm recruiting 1-2 PhD students to work with me at the University of Colorado Boulder! Looking for creative students with interests in #NLP and #CulturalAnalytics.
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!

November 19, 2024 at 10:38 AM
I'm recruiting 1-2 PhD students to work with me at the University of Colorado Boulder! Looking for creative students with interests in #NLP and #CulturalAnalytics.
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!
Reposted by Caleb Ziems

Repost if you’ve participated in a Summer Institute in Computational Social Science. Let’s get #SICSS Bluesky going!
October 8, 2023 at 7:49 PM
Repost if you’ve participated in a Summer Institute in Computational Social Science. Let’s get #SICSS Bluesky going!
Reposted by Caleb Ziems

I'm sharing materials from my academic job search last year! Includes research, teaching, and diversity statements, plus my UMD cover letter and job talk slides. I applied for a mix of iSchool, data sci, CS, and linguistics positions). Feel free to share!
juliamendelsohn.github.io/resources/
juliamendelsohn.github.io/resources/
resources | Julia Mendelsohn
Materials that some people might find helpful
juliamendelsohn.github.io
November 18, 2024 at 4:00 PM
I'm sharing materials from my academic job search last year! Includes research, teaching, and diversity statements, plus my UMD cover letter and job talk slides. I applied for a mix of iSchool, data sci, CS, and linguistics positions). Feel free to share!
juliamendelsohn.github.io/resources/
juliamendelsohn.github.io/resources/
Reposted by Caleb Ziems

All the ACL chapters are here now: @aaclmeeting.bsky.social @emnlpmeeting.bsky.social @eaclmeeting.bsky.social @naaclmeeting.bsky.social #NLProc
November 19, 2024 at 3:48 AM
All the ACL chapters are here now: @aaclmeeting.bsky.social @emnlpmeeting.bsky.social @eaclmeeting.bsky.social @naaclmeeting.bsky.social #NLProc
I wanted to contribute to "Starter Pack Season" with one for Stanford NLP+HCI: go.bsky.app/VZBhuJ5
Here are some other great starter packs:
- CSS: go.bsky.app/GoEyD7d + go.bsky.app/CYmRvcK
- NLP: go.bsky.app/SngwGeS + go.bsky.app/JgneRQk
- HCI: go.bsky.app/p3TLwt
- Women in AI: go.bsky.app/LaGDpqg
Here are some other great starter packs:
- CSS: go.bsky.app/GoEyD7d + go.bsky.app/CYmRvcK
- NLP: go.bsky.app/SngwGeS + go.bsky.app/JgneRQk
- HCI: go.bsky.app/p3TLwt
- Women in AI: go.bsky.app/LaGDpqg
November 15, 2024 at 7:20 PM
I wanted to contribute to "Starter Pack Season" with one for Stanford NLP+HCI: go.bsky.app/VZBhuJ5
Here are some other great starter packs:
- CSS: go.bsky.app/GoEyD7d + go.bsky.app/CYmRvcK
- NLP: go.bsky.app/SngwGeS + go.bsky.app/JgneRQk
- HCI: go.bsky.app/p3TLwt
- Women in AI: go.bsky.app/LaGDpqg
Here are some other great starter packs:
- CSS: go.bsky.app/GoEyD7d + go.bsky.app/CYmRvcK
- NLP: go.bsky.app/SngwGeS + go.bsky.app/JgneRQk
- HCI: go.bsky.app/p3TLwt
- Women in AI: go.bsky.app/LaGDpqg
Reposted by Caleb Ziems

Ready for another Computational Social Science Starter Pack?
Here is number 2! More amazing folks to follow! Many students and the next gen represented!
go.bsky.app/GoEyD7d
Here is number 2! More amazing folks to follow! Many students and the next gen represented!
go.bsky.app/GoEyD7d
November 14, 2024 at 11:42 PM
Ready for another Computational Social Science Starter Pack?
Here is number 2! More amazing folks to follow! Many students and the next gen represented!
go.bsky.app/GoEyD7d
Here is number 2! More amazing folks to follow! Many students and the next gen represented!
go.bsky.app/GoEyD7d
Reposted by Caleb Ziems

🤖🧠 I'll be considering applications for postdocs & PhD students to start at Yale in Fall 2025!
If you are interested in the intersection of linguistics, cognitive science, and AI, I encourage you to apply!
Postdoc link: rtmccoy.com/prospective_...
PhD link: rtmccoy.com/prospective_...
If you are interested in the intersection of linguistics, cognitive science, and AI, I encourage you to apply!
Postdoc link: rtmccoy.com/prospective_...
PhD link: rtmccoy.com/prospective_...
November 14, 2024 at 9:39 PM
🤖🧠 I'll be considering applications for postdocs & PhD students to start at Yale in Fall 2025!
If you are interested in the intersection of linguistics, cognitive science, and AI, I encourage you to apply!
Postdoc link: rtmccoy.com/prospective_...
PhD link: rtmccoy.com/prospective_...
If you are interested in the intersection of linguistics, cognitive science, and AI, I encourage you to apply!
Postdoc link: rtmccoy.com/prospective_...
PhD link: rtmccoy.com/prospective_...
Reposted by Caleb Ziems

Hello! I'm an internet linguist!
I wrote a book called Because Internet about how we use language online gretchenmcculloch.com/book
I make @lingthusiasm.bsky.social, a podcast that's enthusiastic about linguistics
And I maintain a linguistics starter pack here: go.bsky.app/UUM7Gcx
I wrote a book called Because Internet about how we use language online gretchenmcculloch.com/book
I make @lingthusiasm.bsky.social, a podcast that's enthusiastic about linguistics
And I maintain a linguistics starter pack here: go.bsky.app/UUM7Gcx
November 8, 2024 at 5:06 PM
Hello! I'm an internet linguist!
I wrote a book called Because Internet about how we use language online gretchenmcculloch.com/book
I make @lingthusiasm.bsky.social, a podcast that's enthusiastic about linguistics
And I maintain a linguistics starter pack here: go.bsky.app/UUM7Gcx
I wrote a book called Because Internet about how we use language online gretchenmcculloch.com/book
I make @lingthusiasm.bsky.social, a podcast that's enthusiastic about linguistics
And I maintain a linguistics starter pack here: go.bsky.app/UUM7Gcx
Reposted by Caleb Ziems

The AI Interdisciplinary Institute at the University of Maryland (AIM) is hiring
40 new faculty members
in all areas of AI, particularly:
- accessibility,
- sustainability,
- social justice, and
- learning;
building on computational, humanistic, or social scientific approaches to AI.
>
40 new faculty members
in all areas of AI, particularly:
- accessibility,
- sustainability,
- social justice, and
- learning;
building on computational, humanistic, or social scientific approaches to AI.
>
November 13, 2024 at 12:38 PM
The AI Interdisciplinary Institute at the University of Maryland (AIM) is hiring
40 new faculty members
in all areas of AI, particularly:
- accessibility,
- sustainability,
- social justice, and
- learning;
building on computational, humanistic, or social scientific approaches to AI.
>
40 new faculty members
in all areas of AI, particularly:
- accessibility,
- sustainability,
- social justice, and
- learning;
building on computational, humanistic, or social scientific approaches to AI.
>
Reposted by Caleb Ziems

🎓 Fully funded PhD Fellowship in Interpretable NLP at the University of Copenhagen & Pioneer Centre for AI available!
📆 Application deadline: 15 Jan 2025
👥 Supervisors: Pepa Atanasova & me
🤝 Reasons to apply: www.copenlu.com/post/why-ucph/
📝 Apply here: employment.ku.dk/phd/?show=16...
#NLProc #XAI
📆 Application deadline: 15 Jan 2025
👥 Supervisors: Pepa Atanasova & me
🤝 Reasons to apply: www.copenlu.com/post/why-ucph/
📝 Apply here: employment.ku.dk/phd/?show=16...
#NLProc #XAI

November 8, 2024 at 2:13 PM
🎓 Fully funded PhD Fellowship in Interpretable NLP at the University of Copenhagen & Pioneer Centre for AI available!
📆 Application deadline: 15 Jan 2025
👥 Supervisors: Pepa Atanasova & me
🤝 Reasons to apply: www.copenlu.com/post/why-ucph/
📝 Apply here: employment.ku.dk/phd/?show=16...
#NLProc #XAI
📆 Application deadline: 15 Jan 2025
👥 Supervisors: Pepa Atanasova & me
🤝 Reasons to apply: www.copenlu.com/post/why-ucph/
📝 Apply here: employment.ku.dk/phd/?show=16...
#NLProc #XAI
Reposted by Caleb Ziems

Papers at #EMNLP2024 #1
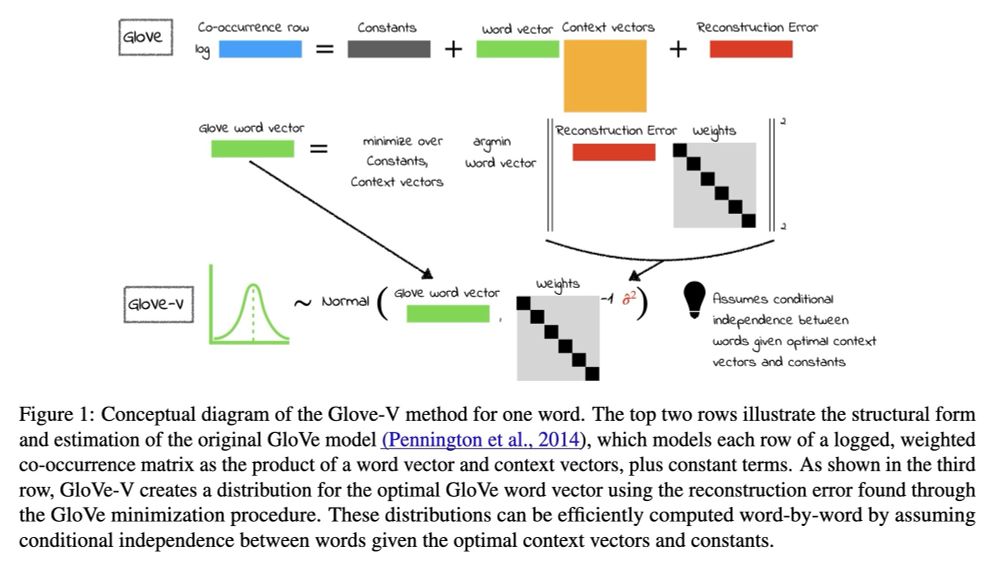
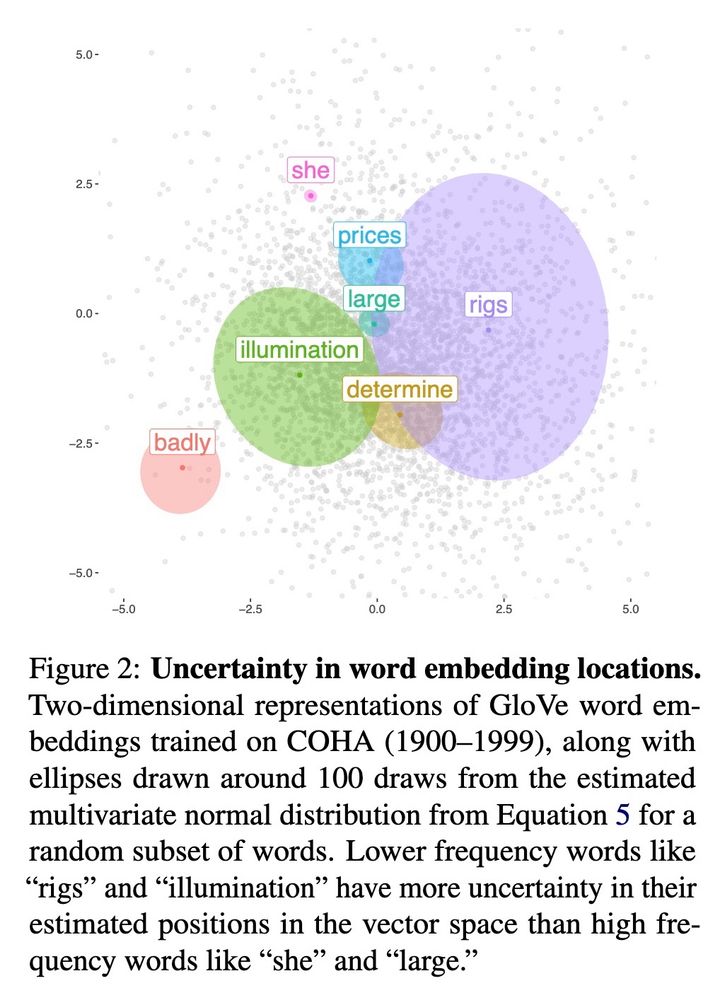
Statistical Uncertainty in Word Embeddings: GloVe-V
Neural models, from word vectors through transformers, use point estimate representations. They can have large variances, which often loom large in CSS applications.
Tue Nov 12 15:15-15:30 Flagler
Statistical Uncertainty in Word Embeddings: GloVe-V
Neural models, from word vectors through transformers, use point estimate representations. They can have large variances, which often loom large in CSS applications.
Tue Nov 12 15:15-15:30 Flagler
November 10, 2024 at 12:36 AM
Papers at #EMNLP2024 #1
Statistical Uncertainty in Word Embeddings: GloVe-V
Neural models, from word vectors through transformers, use point estimate representations. They can have large variances, which often loom large in CSS applications.
Tue Nov 12 15:15-15:30 Flagler
Statistical Uncertainty in Word Embeddings: GloVe-V
Neural models, from word vectors through transformers, use point estimate representations. They can have large variances, which often loom large in CSS applications.
Tue Nov 12 15:15-15:30 Flagler