




Damiano Sgarbossa
@damianosg.bsky.social
Pinned
Damiano Sgarbossa
@damianosg.bsky.social
· Aug 21
📢 Our new preprint is out on bioRxiv! We introduce RAG-ESM, a retrieval-augmented framework that improves pretrained protein language models like ESM2 by making them homology-aware with minimal additional training costs.
🔗 doi.org/10.1101/2025...
💻 github.com/Bitbol-Lab/r...
1/7
🔗 doi.org/10.1101/2025...
💻 github.com/Bitbol-Lab/r...
1/7

🎉 Excited to share that the last paper of my PhD is now published in PRX Life!
We introduce RAG-ESM, a retrieval-augmented framework that makes pretrained protein language models (like ESM2) homology-aware with minimal training cost.
📄 Paper: journals.aps.org/prxlife/abst...
We introduce RAG-ESM, a retrieval-augmented framework that makes pretrained protein language models (like ESM2) homology-aware with minimal training cost.
📄 Paper: journals.aps.org/prxlife/abst...
Reposted by Damiano Sgarbossa

With this, the last bit of my PhD at @embl.org is finally out!
We developed salad (sparse all-atom denoising), a family of blazing fast protein structure diffusion models.
Paper: nature.com/articles/s42256-…
Code: github.com/mjendrusch/salad
Data: zenodo.org/records/14711580
1/🧵
We developed salad (sparse all-atom denoising), a family of blazing fast protein structure diffusion models.
Paper: nature.com/articles/s42256-…
Code: github.com/mjendrusch/salad
Data: zenodo.org/records/14711580
1/🧵

‘Salad’ – a new AI model from EMBL scientists – offers major improvements in synthetic protein design.
Salad is significantly faster than comparable methods, and designing proteins that don't exist in nature can have applications in many scientific fields.
www.nature.com/articles/s42...
Salad is significantly faster than comparable methods, and designing proteins that don't exist in nature can have applications in many scientific fields.
www.nature.com/articles/s42...

September 24, 2025 at 12:27 PM
With this, the last bit of my PhD at @embl.org is finally out!
We developed salad (sparse all-atom denoising), a family of blazing fast protein structure diffusion models.
Paper: nature.com/articles/s42256-…
Code: github.com/mjendrusch/salad
Data: zenodo.org/records/14711580
1/🧵
We developed salad (sparse all-atom denoising), a family of blazing fast protein structure diffusion models.
Paper: nature.com/articles/s42256-…
Code: github.com/mjendrusch/salad
Data: zenodo.org/records/14711580
1/🧵
Reposted by Damiano Sgarbossa

Two exciting openings with us! 🤖🧬🆎🧫💉
- AI Scientist 👉 lnkd.in/eDXHH4E8
- AI Scientist, Drug Creation 👉 lnkd.in/eEvGyaTR
You'll work on antibody sequence/structure design, antibody-antigen co-folding, antibody-antigen binding prediction, physics-based methodologies, and more!
DMs welcome!
- AI Scientist 👉 lnkd.in/eDXHH4E8
- AI Scientist, Drug Creation 👉 lnkd.in/eEvGyaTR
You'll work on antibody sequence/structure design, antibody-antigen co-folding, antibody-antigen binding prediction, physics-based methodologies, and more!
DMs welcome!
August 29, 2025 at 8:13 AM
Two exciting openings with us! 🤖🧬🆎🧫💉
- AI Scientist 👉 lnkd.in/eDXHH4E8
- AI Scientist, Drug Creation 👉 lnkd.in/eEvGyaTR
You'll work on antibody sequence/structure design, antibody-antigen co-folding, antibody-antigen binding prediction, physics-based methodologies, and more!
DMs welcome!
- AI Scientist 👉 lnkd.in/eDXHH4E8
- AI Scientist, Drug Creation 👉 lnkd.in/eEvGyaTR
You'll work on antibody sequence/structure design, antibody-antigen co-folding, antibody-antigen binding prediction, physics-based methodologies, and more!
DMs welcome!
🎉 Excited to share that the last paper of my PhD is now published in PRX Life!
We introduce RAG-ESM, a retrieval-augmented framework that makes pretrained protein language models (like ESM2) homology-aware with minimal training cost.
📄 Paper: journals.aps.org/prxlife/abst...
We introduce RAG-ESM, a retrieval-augmented framework that makes pretrained protein language models (like ESM2) homology-aware with minimal training cost.
📄 Paper: journals.aps.org/prxlife/abst...
📢 Our new preprint is out on bioRxiv! We introduce RAG-ESM, a retrieval-augmented framework that improves pretrained protein language models like ESM2 by making them homology-aware with minimal additional training costs.
🔗 doi.org/10.1101/2025...
💻 github.com/Bitbol-Lab/r...
1/7
🔗 doi.org/10.1101/2025...
💻 github.com/Bitbol-Lab/r...
1/7
August 21, 2025 at 4:13 PM
🎉 Excited to share that the last paper of my PhD is now published in PRX Life!
We introduce RAG-ESM, a retrieval-augmented framework that makes pretrained protein language models (like ESM2) homology-aware with minimal training cost.
📄 Paper: journals.aps.org/prxlife/abst...
We introduce RAG-ESM, a retrieval-augmented framework that makes pretrained protein language models (like ESM2) homology-aware with minimal training cost.
📄 Paper: journals.aps.org/prxlife/abst...
Reposted by Damiano Sgarbossa

[1/8] 📄 New preprint! With Gionata Paolo Zalaffi & Anne-Florence Bitbol, we introduce ProteomeLM, a transformer that processes entire proteomes (prokaryotes and eukaryotes), enabling ultra-fast protein–protein interaction (PPI) prediction across the tree of life.
🔗 www.biorxiv.org/content/10.1...
🔗 www.biorxiv.org/content/10.1...

ProteomeLM: A proteome-scale language model allowing fast prediction of protein-protein interactions and gene essentiality across taxa
Language models starting from biological sequence data are advancing many inference problems, both at the scale of single proteins, and at the scale of genomic neighborhoods. In this paper, we introduce ProteomeLM, a transformer-based language model that reasons on entire proteomes from species spanning the tree of life. Leveraging protein language model embeddings, ProteomeLM is trained to reconstruct masked protein embeddings using the whole proteomic context. It thus learns contextualized protein representations reflecting proteome-scale functional constraints. We show that ProteomeLM spontaneously captures protein-protein interactions (PPI) in its attention coefficients. We demonstrate that it screens whole interactomes orders of magnitude faster than amino-acid coevolution-based methods, and substantially outperforms them. We further develop ProteomeLM-PPI, a supervised PPI prediction network that combines ProteomeLM embeddings and attention coefficients, and achieves state-of-the-art performance across species and benchmarks. Finally, we introduce ProteomeLM-Ess, a supervised predictor of gene essentiality that generalizes across diverse taxa. Our results highlight the power of proteome-scale language models for addressing function and interactions at the organism level. ### Competing Interest Statement The authors have declared no competing interest. European Research Council, https://ror.org/0472cxd90, 851173
www.biorxiv.org
August 21, 2025 at 1:55 PM
[1/8] 📄 New preprint! With Gionata Paolo Zalaffi & Anne-Florence Bitbol, we introduce ProteomeLM, a transformer that processes entire proteomes (prokaryotes and eukaryotes), enabling ultra-fast protein–protein interaction (PPI) prediction across the tree of life.
🔗 www.biorxiv.org/content/10.1...
🔗 www.biorxiv.org/content/10.1...
Happy to announce that our paper, "ProtMamba: a homology-aware but alignment-free protein state space model", has been published in Bioinformatics! 🎉
doi.org/10.1093/bioi...
doi.org/10.1093/bioi...

July 7, 2025 at 4:48 PM
Happy to announce that our paper, "ProtMamba: a homology-aware but alignment-free protein state space model", has been published in Bioinformatics! 🎉
doi.org/10.1093/bioi...
doi.org/10.1093/bioi...
I'm really happy to share with you that after 4 years at EPFL I'm finally a PhD! 🎉🎓
Last Friday I defended my thesis titled: "Revealing and Exploiting Coevolution through Protein Language Models".
It was an amazing journey where I met some incredible people. Thank you all ❤️
Last Friday I defended my thesis titled: "Revealing and Exploiting Coevolution through Protein Language Models".
It was an amazing journey where I met some incredible people. Thank you all ❤️

June 30, 2025 at 11:42 AM
I'm really happy to share with you that after 4 years at EPFL I'm finally a PhD! 🎉🎓
Last Friday I defended my thesis titled: "Revealing and Exploiting Coevolution through Protein Language Models".
It was an amazing journey where I met some incredible people. Thank you all ❤️
Last Friday I defended my thesis titled: "Revealing and Exploiting Coevolution through Protein Language Models".
It was an amazing journey where I met some incredible people. Thank you all ❤️
Reposted by Damiano Sgarbossa

New preprint of @trono-lab.bsky.social and my PhD work!
By modulating SWI/SNF remodeling at ancient transposable elements - LINE/L2s and SINE/MIRs, a "noncanonical" KZFP called ZNF436 protects cardiomyocytes from losing their identity.
🫀heartbeat on 🔁 repeat
www.biorxiv.org/content/10.1... #TEsky
By modulating SWI/SNF remodeling at ancient transposable elements - LINE/L2s and SINE/MIRs, a "noncanonical" KZFP called ZNF436 protects cardiomyocytes from losing their identity.
🫀heartbeat on 🔁 repeat
www.biorxiv.org/content/10.1... #TEsky
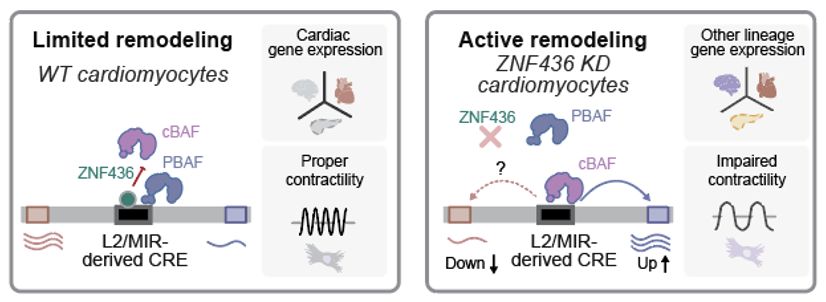
May 19, 2025 at 2:01 PM
New preprint of @trono-lab.bsky.social and my PhD work!
By modulating SWI/SNF remodeling at ancient transposable elements - LINE/L2s and SINE/MIRs, a "noncanonical" KZFP called ZNF436 protects cardiomyocytes from losing their identity.
🫀heartbeat on 🔁 repeat
www.biorxiv.org/content/10.1... #TEsky
By modulating SWI/SNF remodeling at ancient transposable elements - LINE/L2s and SINE/MIRs, a "noncanonical" KZFP called ZNF436 protects cardiomyocytes from losing their identity.
🫀heartbeat on 🔁 repeat
www.biorxiv.org/content/10.1... #TEsky
Reposted by Damiano Sgarbossa

In this evaluation of AlphaFold3 (and other methods), we show that (i) accurate predictions are limited to RNA structures/complexes with structural similarity to PDB and (ii) that current methods are bad at estimating the accuracy of the predictions. www.biorxiv.org/content/10.1...
Limits of deep-learning-based RNA prediction methods
Motivation: In recent years, tremendous advances have been made in predicting protein structures and protein-protein interactions. However, progress in predicting the structure of RNA, either alone or...
www.biorxiv.org
May 5, 2025 at 1:01 PM
In this evaluation of AlphaFold3 (and other methods), we show that (i) accurate predictions are limited to RNA structures/complexes with structural similarity to PDB and (ii) that current methods are bad at estimating the accuracy of the predictions. www.biorxiv.org/content/10.1...
📢 Our new preprint is out on bioRxiv! We introduce RAG-ESM, a retrieval-augmented framework that improves pretrained protein language models like ESM2 by making them homology-aware with minimal additional training costs.
🔗 doi.org/10.1101/2025...
💻 github.com/Bitbol-Lab/r...
1/7
🔗 doi.org/10.1101/2025...
💻 github.com/Bitbol-Lab/r...
1/7
April 11, 2025 at 2:47 PM
📢 Our new preprint is out on bioRxiv! We introduce RAG-ESM, a retrieval-augmented framework that improves pretrained protein language models like ESM2 by making them homology-aware with minimal additional training costs.
🔗 doi.org/10.1101/2025...
💻 github.com/Bitbol-Lab/r...
1/7
🔗 doi.org/10.1101/2025...
💻 github.com/Bitbol-Lab/r...
1/7
Reposted by Damiano Sgarbossa

📢📢 "Proteina: Scaling Flow-based Protein Structure Generative Models"
#ICLR2025 (Oral Presentation)
🔥 Project page: research.nvidia.com/labs/genair/...
📜 Paper: arxiv.org/abs/2503.00710
🛠️ Code and weights: github.com/NVIDIA-Digit...
🧵Details in thread...
(1/n)
#ICLR2025 (Oral Presentation)
🔥 Project page: research.nvidia.com/labs/genair/...
📜 Paper: arxiv.org/abs/2503.00710
🛠️ Code and weights: github.com/NVIDIA-Digit...
🧵Details in thread...
(1/n)
March 4, 2025 at 5:09 PM
📢📢 "Proteina: Scaling Flow-based Protein Structure Generative Models"
#ICLR2025 (Oral Presentation)
🔥 Project page: research.nvidia.com/labs/genair/...
📜 Paper: arxiv.org/abs/2503.00710
🛠️ Code and weights: github.com/NVIDIA-Digit...
🧵Details in thread...
(1/n)
#ICLR2025 (Oral Presentation)
🔥 Project page: research.nvidia.com/labs/genair/...
📜 Paper: arxiv.org/abs/2503.00710
🛠️ Code and weights: github.com/NVIDIA-Digit...
🧵Details in thread...
(1/n)
Reposted by Damiano Sgarbossa

Excited to share PoET-2, our next breakthrough in protein language modeling. It represents a fundamental shift in how AI learns from evolutionary sequences. 🧵 1/13
February 11, 2025 at 2:30 PM
Excited to share PoET-2, our next breakthrough in protein language modeling. It represents a fundamental shift in how AI learns from evolutionary sequences. 🧵 1/13
Reposted by Damiano Sgarbossa

I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
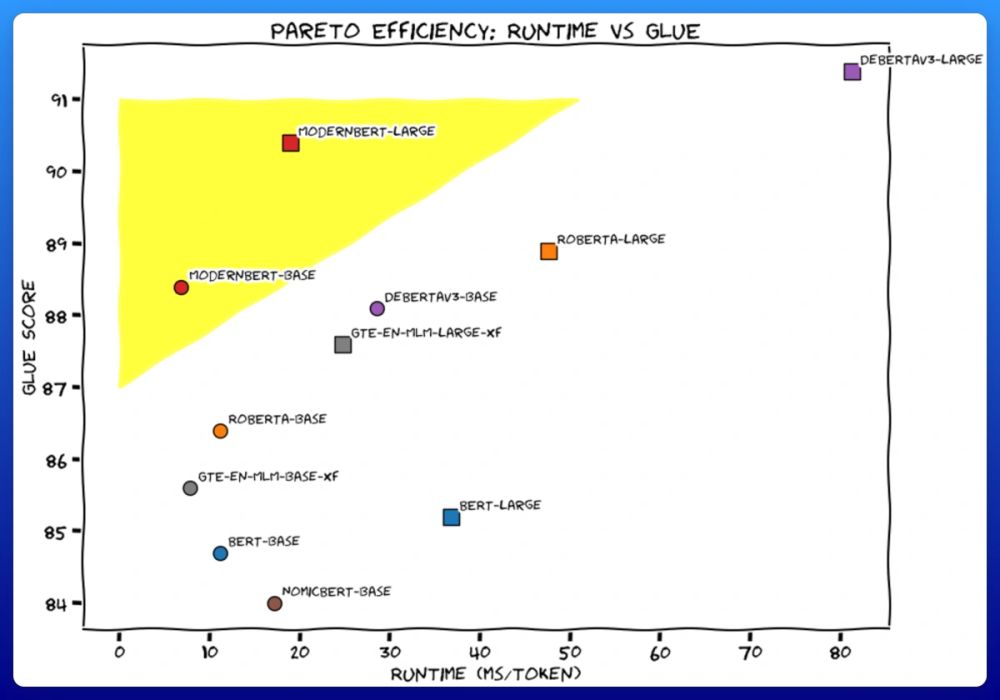
December 19, 2024 at 4:45 PM
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
Reposted by Damiano Sgarbossa

Extremely pleased to announce that after *checks notes* 2 years, our paper on Structure-based Drug Design with diffusion models has been published in Nature Computational Science (@natcomputsci.bsky.social)!!
Thanks a lot to the great co-authors! Esp
@rne.bsky.social & Yuanqi Du.
Thanks a lot to the great co-authors! Esp
@rne.bsky.social & Yuanqi Du.

Structure-based drug design with equivariant diffusion models - Nature Computational Science
This work applies diffusion models to conditional molecule generation and shows how they can be used to tackle various structure-based drug design problems
www.nature.com
December 10, 2024 at 3:10 PM
Extremely pleased to announce that after *checks notes* 2 years, our paper on Structure-based Drug Design with diffusion models has been published in Nature Computational Science (@natcomputsci.bsky.social)!!
Thanks a lot to the great co-authors! Esp
@rne.bsky.social & Yuanqi Du.
Thanks a lot to the great co-authors! Esp
@rne.bsky.social & Yuanqi Du.
Reposted by Damiano Sgarbossa

1/🧬 Excited to share PLAID, our new approach for co-generating sequence and all-atom protein structures by sampling from the latent space of ESMFold. This requires only sequences during training, which unlocks more data and annotations:
bit.ly/plaid-proteins
🧵
bit.ly/plaid-proteins
🧵
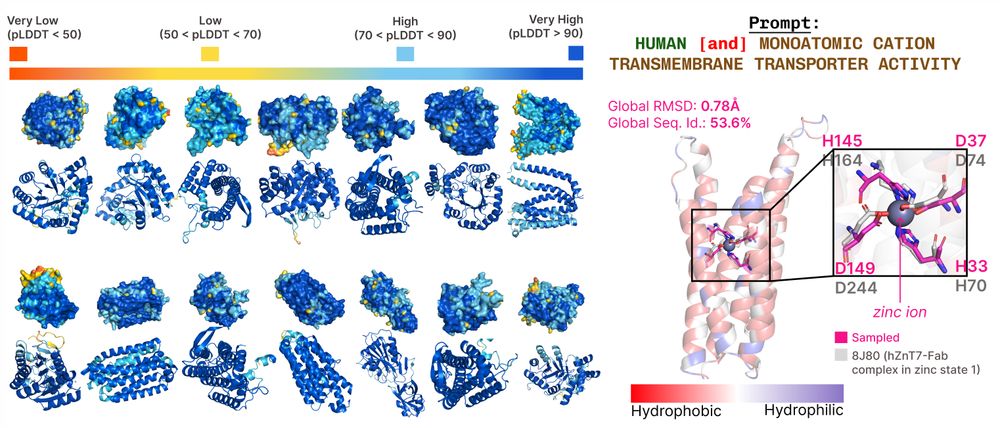
December 6, 2024 at 5:44 PM
1/🧬 Excited to share PLAID, our new approach for co-generating sequence and all-atom protein structures by sampling from the latent space of ESMFold. This requires only sequences during training, which unlocks more data and annotations:
bit.ly/plaid-proteins
🧵
bit.ly/plaid-proteins
🧵
Reposted by Damiano Sgarbossa

Introducing ESM Cambrian, a new family of protein language models, focused on creating representations of the underlying biology of proteins.
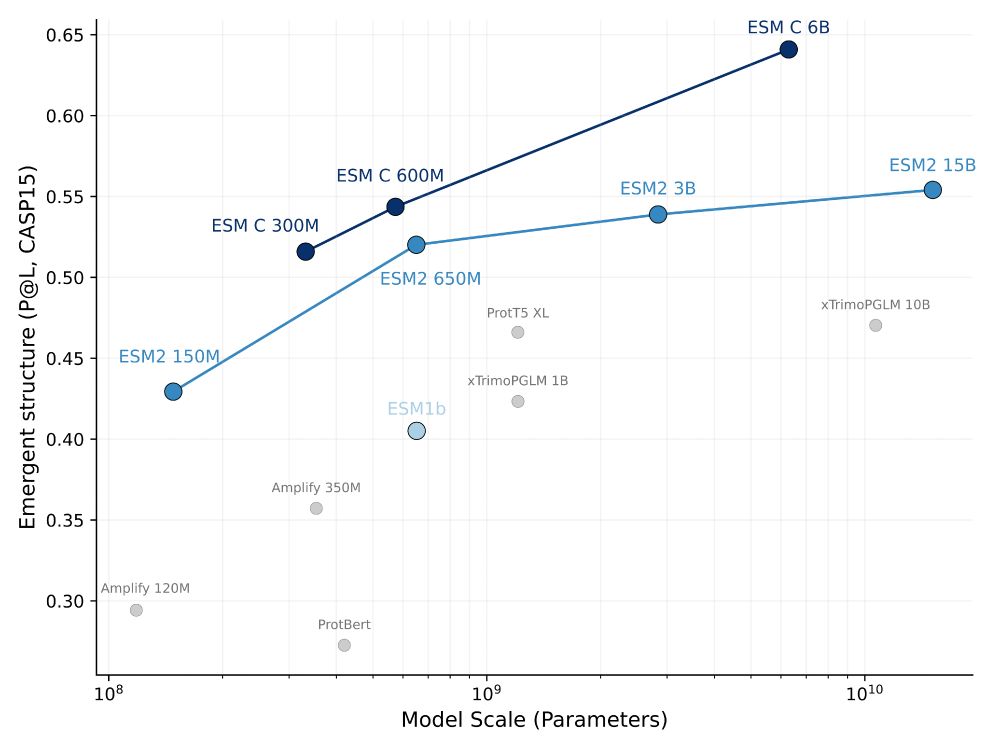
December 4, 2024 at 5:45 PM
Introducing ESM Cambrian, a new family of protein language models, focused on creating representations of the underlying biology of proteins.
We’re happy to announce that our track "AI & the Molecular World" at @appliedmldays.org will take place this year too! Join us in Lausanne on February 13, 2024!
The call for talks is now open! Submit your abstract by January 5, 2024, at:
forms.gle/hu6BEWMN1BcR...
The call for talks is now open! Submit your abstract by January 5, 2024, at:
forms.gle/hu6BEWMN1BcR...

November 22, 2024 at 8:53 AM
We’re happy to announce that our track "AI & the Molecular World" at @appliedmldays.org will take place this year too! Join us in Lausanne on February 13, 2024!
The call for talks is now open! Submit your abstract by January 5, 2024, at:
forms.gle/hu6BEWMN1BcR...
The call for talks is now open! Submit your abstract by January 5, 2024, at:
forms.gle/hu6BEWMN1BcR...
Reposted by Damiano Sgarbossa

We strongly suggest that academic publishers and other platforms that host research rapidly implement a Share to Bluesky button for their articles. Here's how:
docs.bsky.app/docs/advance...
#AcademicSky #HigherEd #Altmetrics
docs.bsky.app/docs/advance...
#AcademicSky #HigherEd #Altmetrics

Action Intent Links | Bluesky
Authors, websites, and apps can use action intent links to implement "Share on Bluesky" buttons, or similar in-app actions. Logged-in users will be directed to the corresponding action view in the Blu...
docs.bsky.app
November 18, 2024 at 2:48 PM
We strongly suggest that academic publishers and other platforms that host research rapidly implement a Share to Bluesky button for their articles. Here's how:
docs.bsky.app/docs/advance...
#AcademicSky #HigherEd #Altmetrics
docs.bsky.app/docs/advance...
#AcademicSky #HigherEd #Altmetrics
Reposted by Damiano Sgarbossa

Thrilled to announce Boltz-1, the first open-source and commercially available model to achieve AlphaFold3-level accuracy on biomolecular structure prediction! An exciting collaboration with Jeremy, Saro, and an amazing team at MIT and Genesis Therapeutics. A thread!
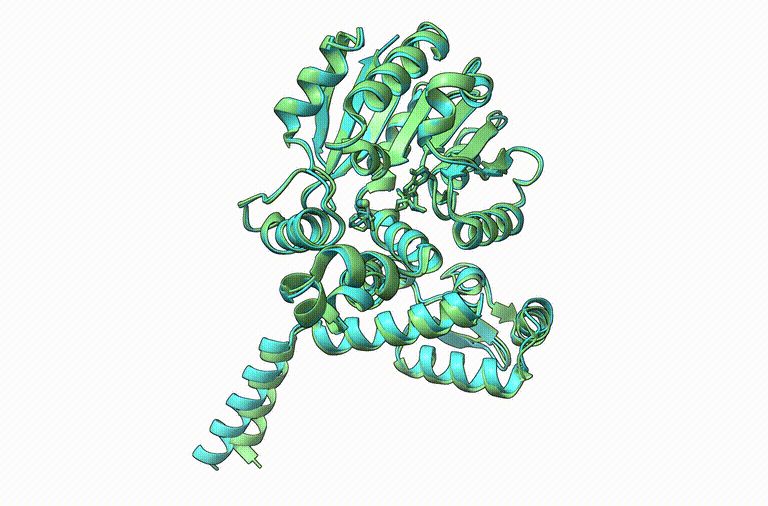
November 17, 2024 at 4:20 PM
Thrilled to announce Boltz-1, the first open-source and commercially available model to achieve AlphaFold3-level accuracy on biomolecular structure prediction! An exciting collaboration with Jeremy, Saro, and an amazing team at MIT and Genesis Therapeutics. A thread!