



Enzo Doyen
@edoyen.com
89 followers
110 following
78 posts
PhD Candidate in Natural Language Processing @unistra.fr; working on LLM gender bias mitigating.
Localization Specialist (EN → FR).
Interested in research; politics; technology; languages; literature; philosophy.
Website: https://edoyen.com/
Views my own.
Posts
Media
Videos
Starter Packs
Reposted by Enzo Doyen

Reposted by Enzo Doyen

Reposted by Enzo Doyen


Enzo Doyen
@edoyen.com
· Jul 15
Enzo Doyen
@edoyen.com
· Jul 15
Reposted by Enzo Doyen

GITT 2025
@gitt-workshop.bsky.social
· Jun 23
Enzo Doyen
@edoyen.com
· May 29
Reposted by Enzo Doyen

Maria Antoniak
@mariaa.bsky.social
· Apr 6

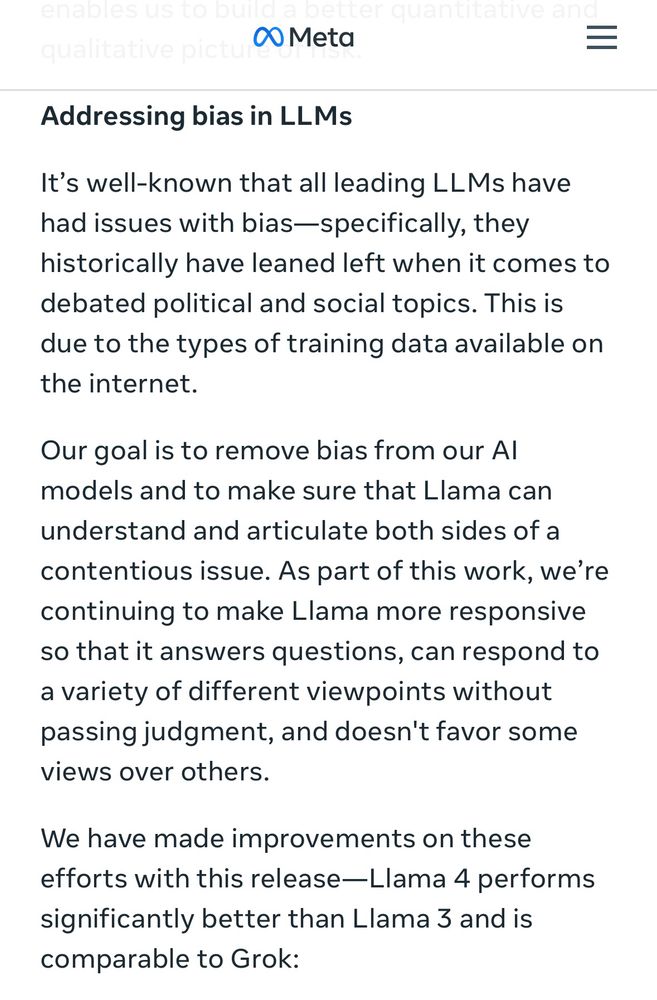
Meta introduced Llama 4 models and added this section near the very bottom of the announcement 😬
“[LLMs] historically have leaned left when it comes to debated political and social topics.”
ai.meta.com/blog/llama-4...
“[LLMs] historically have leaned left when it comes to debated political and social topics.”
ai.meta.com/blog/llama-4...

Enzo Doyen
@edoyen.com
· Mar 13
Enzo Doyen
@edoyen.com
· Mar 12
Enzo Doyen
@edoyen.com
· Mar 12
Enzo Doyen
@edoyen.com
· Mar 12
Enzo Doyen
@edoyen.com
· Feb 12

Reposted by Enzo Doyen


Enzo Doyen
@edoyen.com
· Feb 1

Enzo Doyen
@edoyen.com
· Jan 28
Enzo Doyen
@edoyen.com
· Jan 28
Enzo Doyen
@edoyen.com
· Jan 28
Enzo Doyen
@edoyen.com
· Jan 28
Enzo Doyen
@edoyen.com
· Jan 28
Enzo Doyen
@edoyen.com
· Jan 28
Enzo Doyen
@edoyen.com
· Jan 28
Enzo Doyen
@edoyen.com
· Jan 28