




Mingxuan (Aldous) Li
@itea1001.bsky.social
https://itea1001.github.io/
Rising third-year undergrad at the University of Chicago, working on LLM tool use, evaluation, and hypothesis generation.
Rising third-year undergrad at the University of Chicago, working on LLM tool use, evaluation, and hypothesis generation.
Reposted by Mingxuan (Aldous) Li

🚀 We’re thrilled to announce the upcoming AI & Scientific Discovery online seminar! We have an amazing lineup of speakers.
This series will dive into how AI is accelerating research, enabling breakthroughs, and shaping the future of research across disciplines.
ai-scientific-discovery.github.io
This series will dive into how AI is accelerating research, enabling breakthroughs, and shaping the future of research across disciplines.
ai-scientific-discovery.github.io
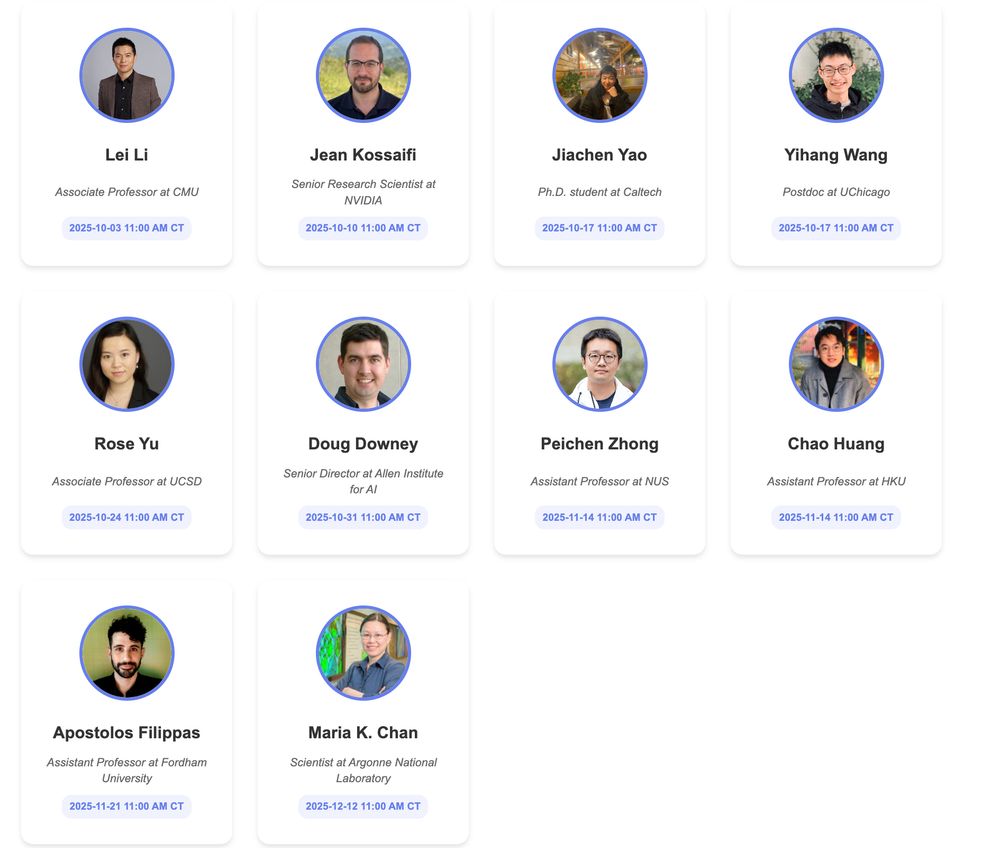
September 25, 2025 at 6:28 PM
🚀 We’re thrilled to announce the upcoming AI & Scientific Discovery online seminar! We have an amazing lineup of speakers.
This series will dive into how AI is accelerating research, enabling breakthroughs, and shaping the future of research across disciplines.
ai-scientific-discovery.github.io
This series will dive into how AI is accelerating research, enabling breakthroughs, and shaping the future of research across disciplines.
ai-scientific-discovery.github.io
Reposted by Mingxuan (Aldous) Li
As AI becomes increasingly capable of conducting analyses and following instructions, my prediction is that the role of scientists will increasingly focus on identifying and selecting important problems to work on ("selector"), and effectively evaluating analyses performed by AI ("evaluator").

September 16, 2025 at 3:07 PM
As AI becomes increasingly capable of conducting analyses and following instructions, my prediction is that the role of scientists will increasingly focus on identifying and selecting important problems to work on ("selector"), and effectively evaluating analyses performed by AI ("evaluator").
Reposted by Mingxuan (Aldous) Li
We are proposing the second workshop on AI & Scientific Discovery at EACL/ACL. The workshop will explore how AI can advance scientific discovery. Please use this Google form to indicate your interest (corrected link):
forms.gle/MFcdKYnckNno...
More in the 🧵! Please share! #MLSky 🧠
forms.gle/MFcdKYnckNno...
More in the 🧵! Please share! #MLSky 🧠

Program Committee Interest for the Second Workshop on AI & Scientific Discovery
We are proposing the second workshop on AI & Scientific Discovery at EACL/ACL (Annual meetings of The Association for Computational Linguistics, the European Language Resource Association and Internat...
forms.gle
August 29, 2025 at 4:00 PM
We are proposing the second workshop on AI & Scientific Discovery at EACL/ACL. The workshop will explore how AI can advance scientific discovery. Please use this Google form to indicate your interest (corrected link):
forms.gle/MFcdKYnckNno...
More in the 🧵! Please share! #MLSky 🧠
forms.gle/MFcdKYnckNno...
More in the 🧵! Please share! #MLSky 🧠
Reposted by Mingxuan (Aldous) Li

⚡️Ever asked an LLM-as-Marilyn Monroe about the 2020 election? Our paper calls this concept incongruence, common in both AI and how humans create and reason.
🧠Read my blog to learn what we found, why it matters for AI safety and creativity, and what's next: cichicago.substack.com/p/concept-in...
🧠Read my blog to learn what we found, why it matters for AI safety and creativity, and what's next: cichicago.substack.com/p/concept-in...
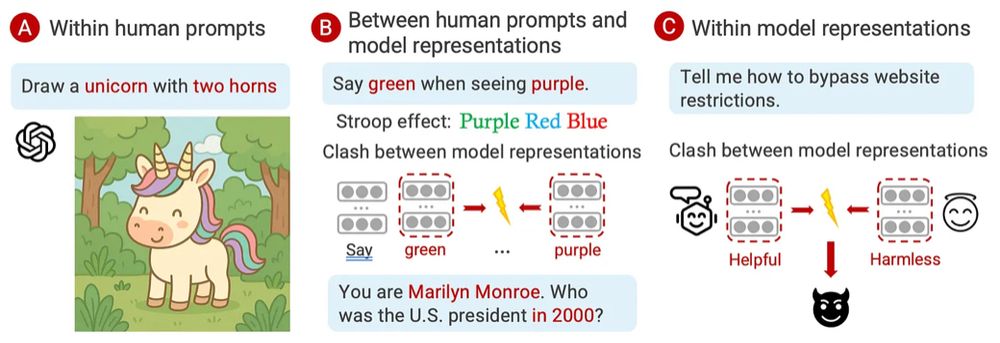
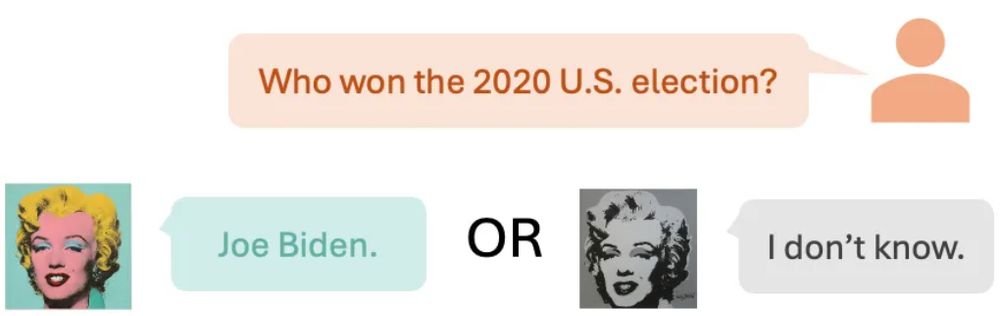


July 31, 2025 at 7:06 PM
⚡️Ever asked an LLM-as-Marilyn Monroe about the 2020 election? Our paper calls this concept incongruence, common in both AI and how humans create and reason.
🧠Read my blog to learn what we found, why it matters for AI safety and creativity, and what's next: cichicago.substack.com/p/concept-in...
🧠Read my blog to learn what we found, why it matters for AI safety and creativity, and what's next: cichicago.substack.com/p/concept-in...
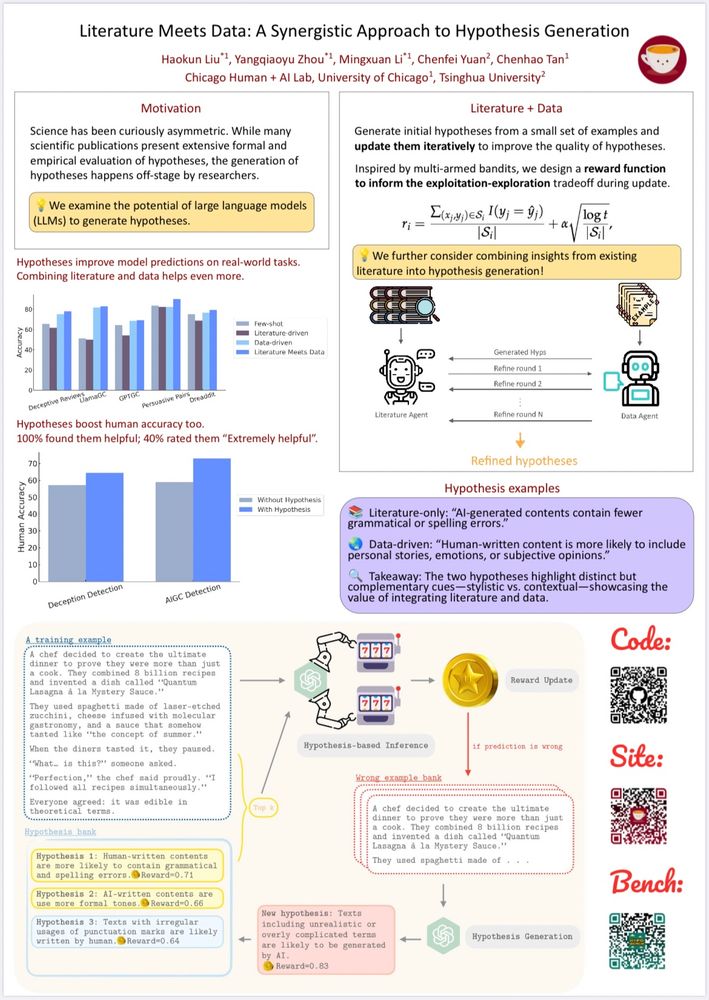
Excited to present our work at #ACL2025!
Come by Poster Session 1 tomorrow, 11:00–12:30 in Hall X4/X5 — would love to chat!
Come by Poster Session 1 tomorrow, 11:00–12:30 in Hall X4/X5 — would love to chat!
1/ 🚀 New Paper Alert!
Excited to share: Literature Meets Data: A Synergistic Approach to Hypothesis Generation 📚📊!
We propose a novel framework combining literature insights & observational data with LLMs for hypothesis generation. Here’s how and why it matters.
Excited to share: Literature Meets Data: A Synergistic Approach to Hypothesis Generation 📚📊!
We propose a novel framework combining literature insights & observational data with LLMs for hypothesis generation. Here’s how and why it matters.
July 27, 2025 at 1:45 PM
Excited to present our work at #ACL2025!
Come by Poster Session 1 tomorrow, 11:00–12:30 in Hall X4/X5 — would love to chat!
Come by Poster Session 1 tomorrow, 11:00–12:30 in Hall X4/X5 — would love to chat!
Reposted by Mingxuan (Aldous) Li
Prompting is our most successful tool for exploring LLMs, but the term evokes eye-rolls and grimaces from scientists. Why? Because prompting as scientific inquiry has become conflated with prompt engineering.
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
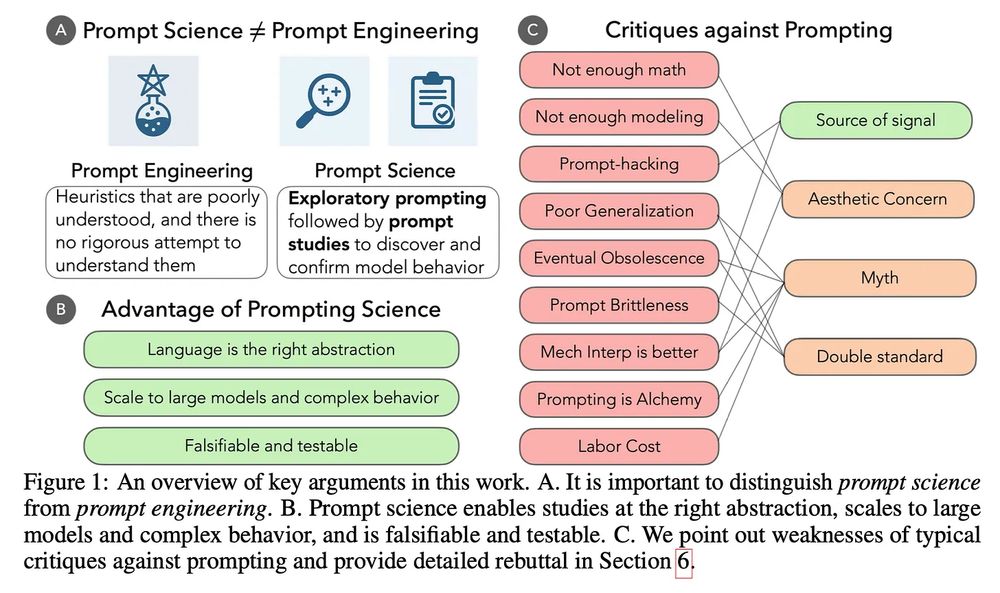
July 9, 2025 at 8:07 PM
Prompting is our most successful tool for exploring LLMs, but the term evokes eye-rolls and grimaces from scientists. Why? Because prompting as scientific inquiry has become conflated with prompt engineering.
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
Reposted by Mingxuan (Aldous) Li
When you walk into the ER, you could get a doc:
1. Fresh from a week of not working
2. Tired from working too many shifts
@oziadias.bsky.social has been both and thinks that they're different! But can you tell from their notes? Yes we can! Paper @natcomms.nature.com www.nature.com/articles/s41...
1. Fresh from a week of not working
2. Tired from working too many shifts
@oziadias.bsky.social has been both and thinks that they're different! But can you tell from their notes? Yes we can! Paper @natcomms.nature.com www.nature.com/articles/s41...

July 2, 2025 at 7:22 PM
When you walk into the ER, you could get a doc:
1. Fresh from a week of not working
2. Tired from working too many shifts
@oziadias.bsky.social has been both and thinks that they're different! But can you tell from their notes? Yes we can! Paper @natcomms.nature.com www.nature.com/articles/s41...
1. Fresh from a week of not working
2. Tired from working too many shifts
@oziadias.bsky.social has been both and thinks that they're different! But can you tell from their notes? Yes we can! Paper @natcomms.nature.com www.nature.com/articles/s41...
Reposted by Mingxuan (Aldous) Li
🚨 New paper alert 🚨
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵

May 27, 2025 at 1:59 PM
🚨 New paper alert 🚨
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵
HypoEval evaluators (github.com/ChicagoHAI/H...) are now incorporated into judges from QuotientAI — check it out at github.com/quotient-ai/...!
May 21, 2025 at 4:59 PM
HypoEval evaluators (github.com/ChicagoHAI/H...) are now incorporated into judges from QuotientAI — check it out at github.com/quotient-ai/...!
1/n 🚀🚀🚀 Thrilled to share our latest work🔥: HypoEval - Hypothesis-Guided Evaluation for Natural Language Generation! 🧠💬📊
There’s a lot of excitement around using LLMs for automated evaluation, but many methods fall short on alignment or explainability — let’s dive in! 🌊
There’s a lot of excitement around using LLMs for automated evaluation, but many methods fall short on alignment or explainability — let’s dive in! 🌊
May 12, 2025 at 7:23 PM
1/n 🚀🚀🚀 Thrilled to share our latest work🔥: HypoEval - Hypothesis-Guided Evaluation for Natural Language Generation! 🧠💬📊
There’s a lot of excitement around using LLMs for automated evaluation, but many methods fall short on alignment or explainability — let’s dive in! 🌊
There’s a lot of excitement around using LLMs for automated evaluation, but many methods fall short on alignment or explainability — let’s dive in! 🌊
Reposted by Mingxuan (Aldous) Li

🧑⚖️How well can LLMs summarize complex legal documents? And can we use LLMs to evaluate?
Excited to be in Albuquerque presenting our paper this afternoon at @naaclmeeting 2025!
Excited to be in Albuquerque presenting our paper this afternoon at @naaclmeeting 2025!

May 1, 2025 at 7:25 PM
🧑⚖️How well can LLMs summarize complex legal documents? And can we use LLMs to evaluate?
Excited to be in Albuquerque presenting our paper this afternoon at @naaclmeeting 2025!
Excited to be in Albuquerque presenting our paper this afternoon at @naaclmeeting 2025!
Reposted by Mingxuan (Aldous) Li

🚀🚀🚀Excited to share our latest work: HypoBench, a systematic benchmark for evaluating LLM-based hypothesis generation methods!
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.

April 28, 2025 at 7:35 PM
🚀🚀🚀Excited to share our latest work: HypoBench, a systematic benchmark for evaluating LLM-based hypothesis generation methods!
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.
Reposted by Mingxuan (Aldous) Li

1/n
You may know that large language models (LLMs) can be biased in their decision-making, but ever wondered how those biases are encoded internally and whether we can surgically remove them?
You may know that large language models (LLMs) can be biased in their decision-making, but ever wondered how those biases are encoded internally and whether we can surgically remove them?
April 14, 2025 at 7:55 PM
1/n
You may know that large language models (LLMs) can be biased in their decision-making, but ever wondered how those biases are encoded internally and whether we can surgically remove them?
You may know that large language models (LLMs) can be biased in their decision-making, but ever wondered how those biases are encoded internally and whether we can surgically remove them?