
Mingxuan (Aldous) Li
@itea1001.bsky.social
9 followers
24 following
15 posts
https://itea1001.github.io/
Rising third-year undergrad at the University of Chicago, working on LLM tool use, evaluation, and hypothesis generation.
Posts
Media
Videos
Starter Packs
Reposted by Mingxuan (Aldous) Li

Reposted by Mingxuan (Aldous) Li

Reposted by Mingxuan (Aldous) Li

Reposted by Mingxuan (Aldous) Li

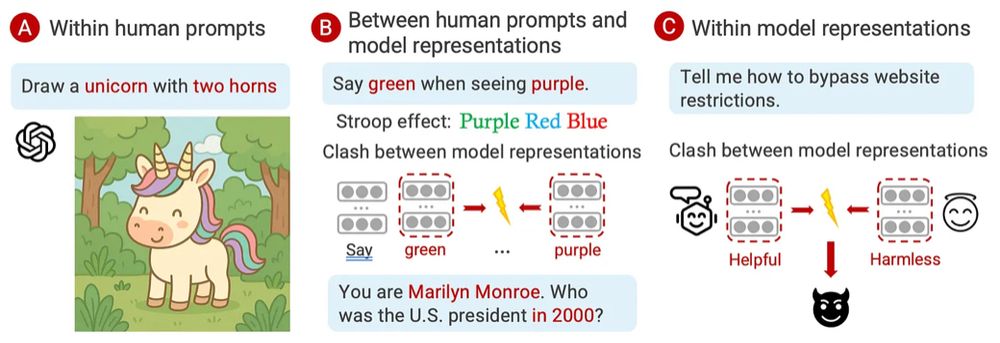
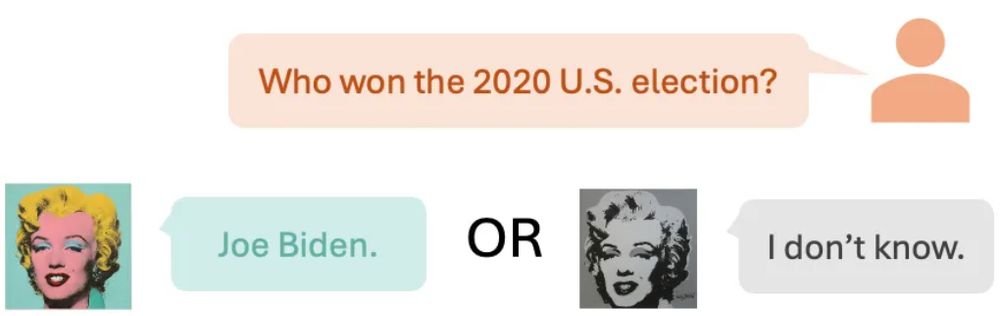



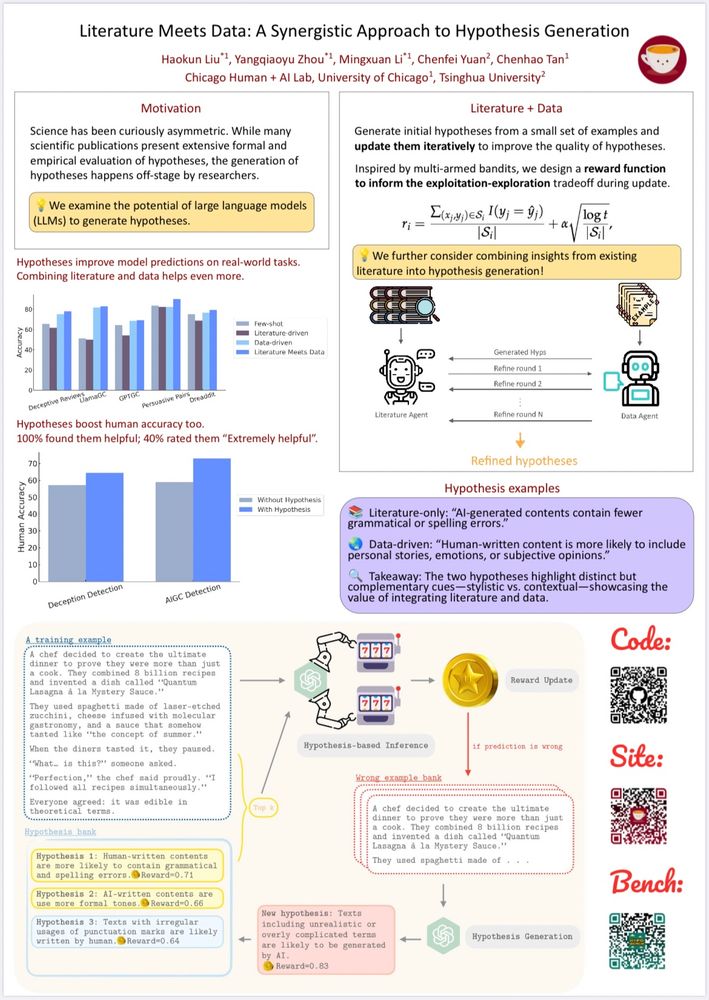
Reposted by Mingxuan (Aldous) Li
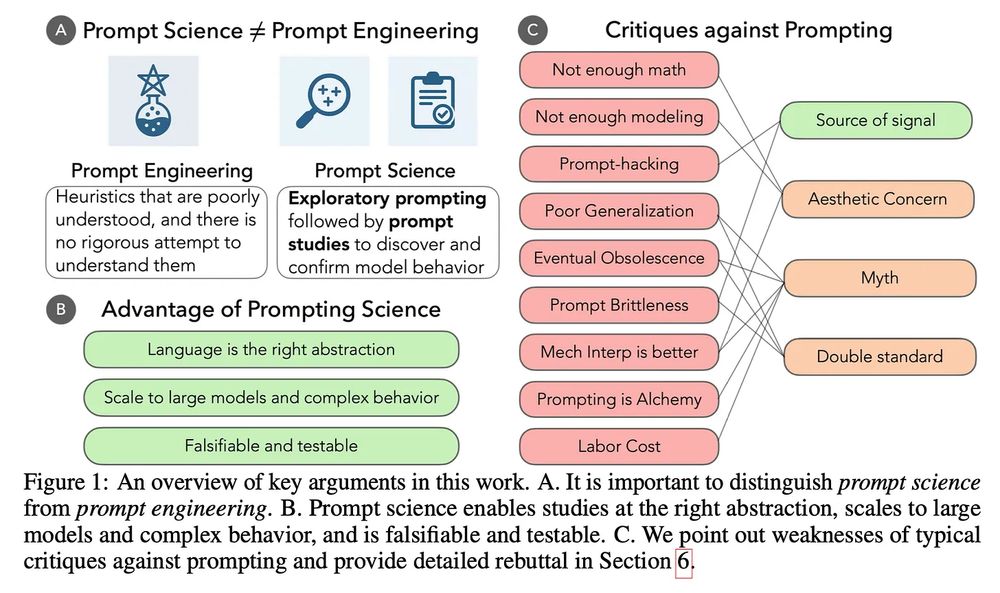
Reposted by Mingxuan (Aldous) Li

Reposted by Mingxuan (Aldous) Li



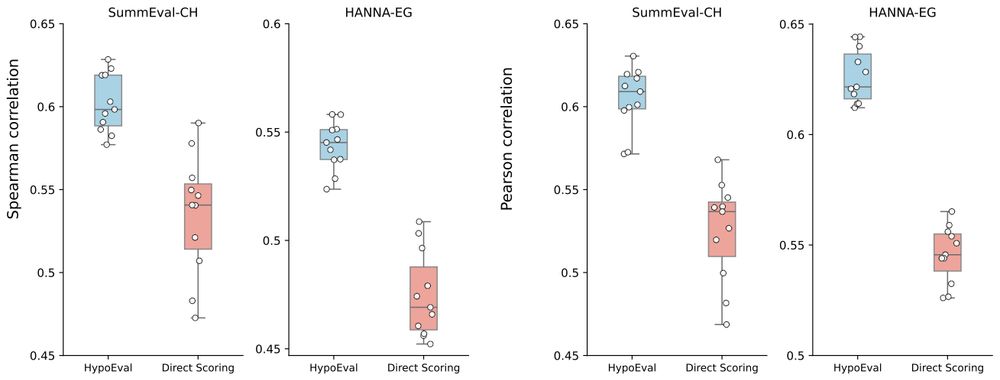

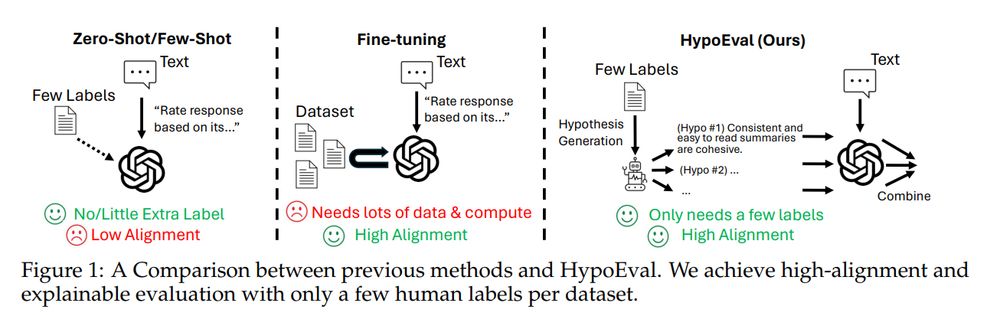
Reposted by Mingxuan (Aldous) Li


Reposted by Mingxuan (Aldous) Li

