Haokun Liu
@haokunliu.bsky.social
87 followers
53 following
27 posts
Ph.D. Student at the University of Chicago | Chicago Human + AI Lab
haokunliu.com
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Haokun Liu
Reposted by Haokun Liu

Reposted by Haokun Liu

Reposted by Haokun Liu

Reposted by Haokun Liu


Reposted by Haokun Liu
Reposted by Haokun Liu


Reposted by Haokun Liu

Haokun Liu
@haokunliu.bsky.social
· Apr 28
Haokun Liu
@haokunliu.bsky.social
· Apr 28

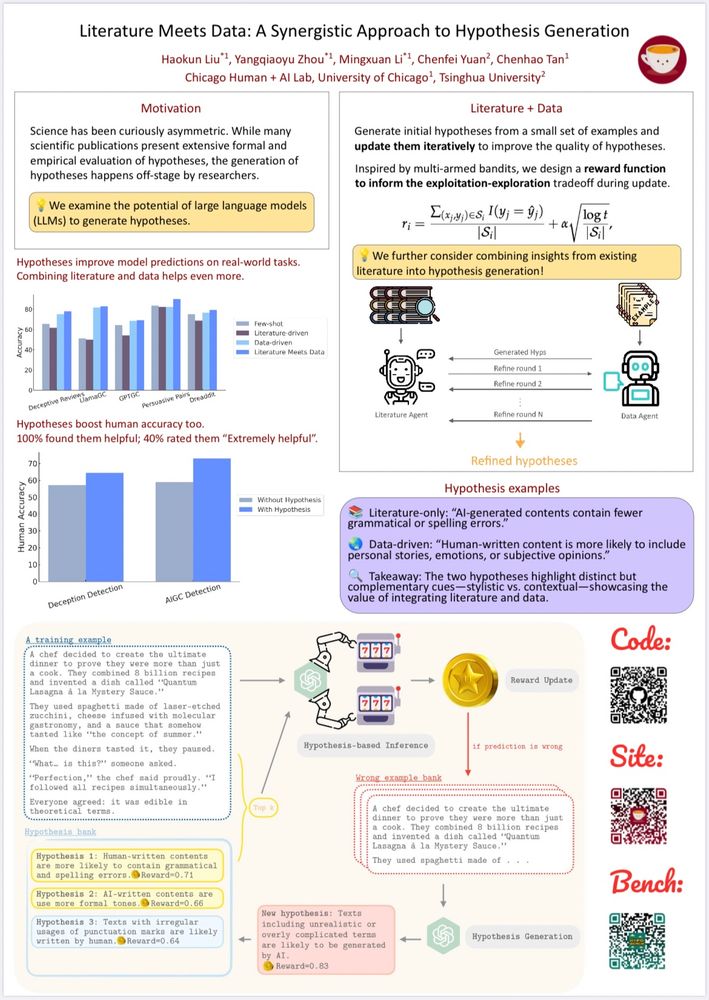
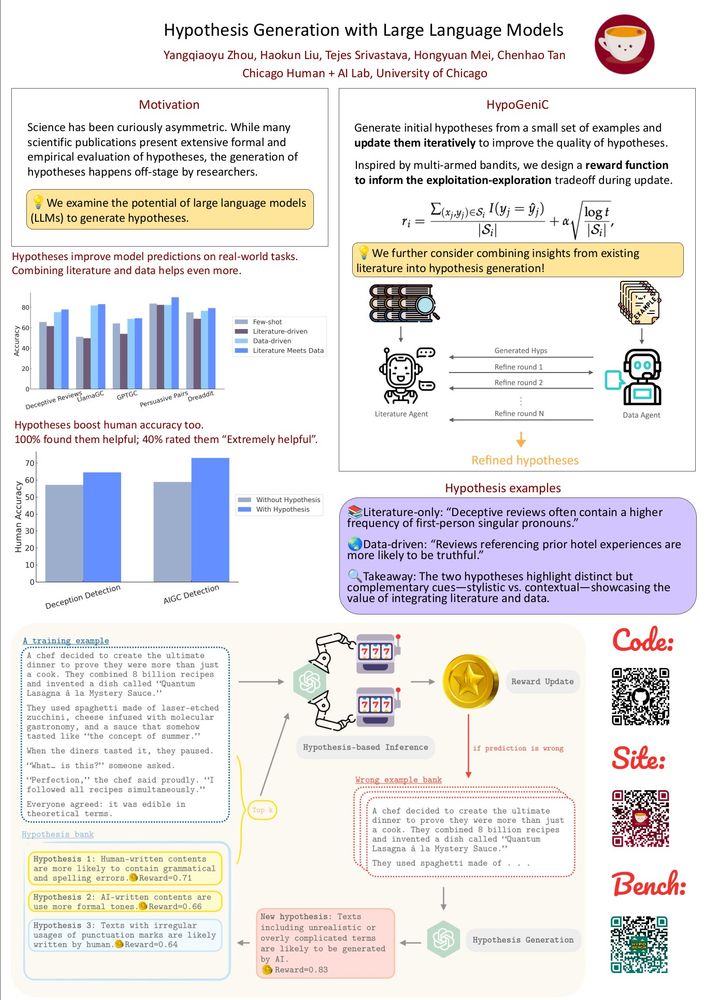
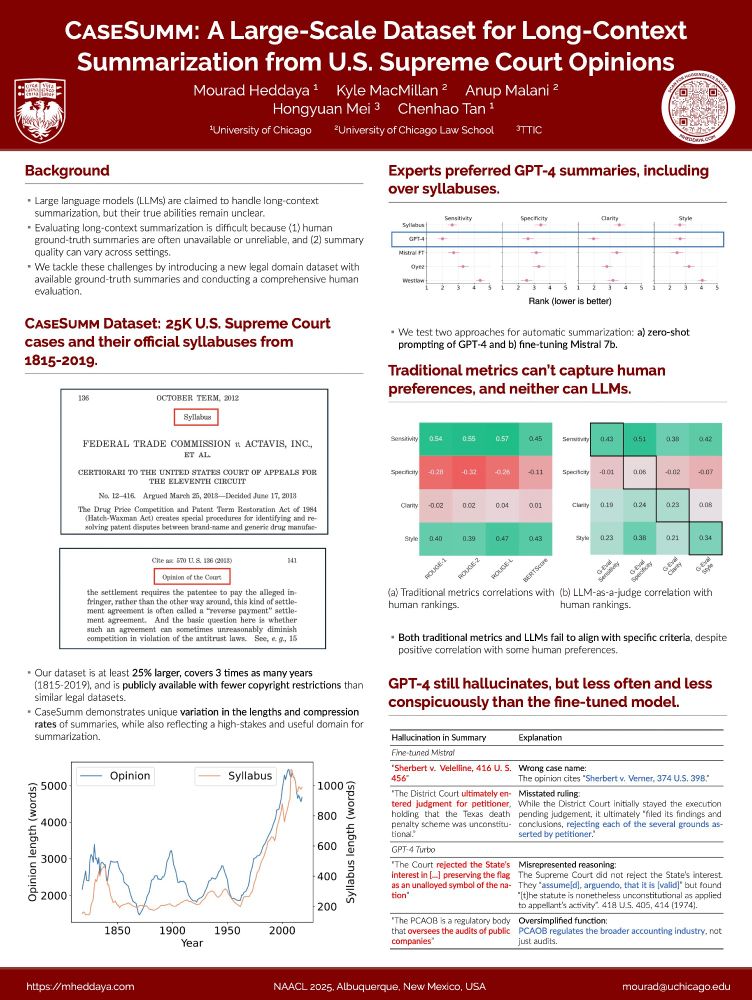
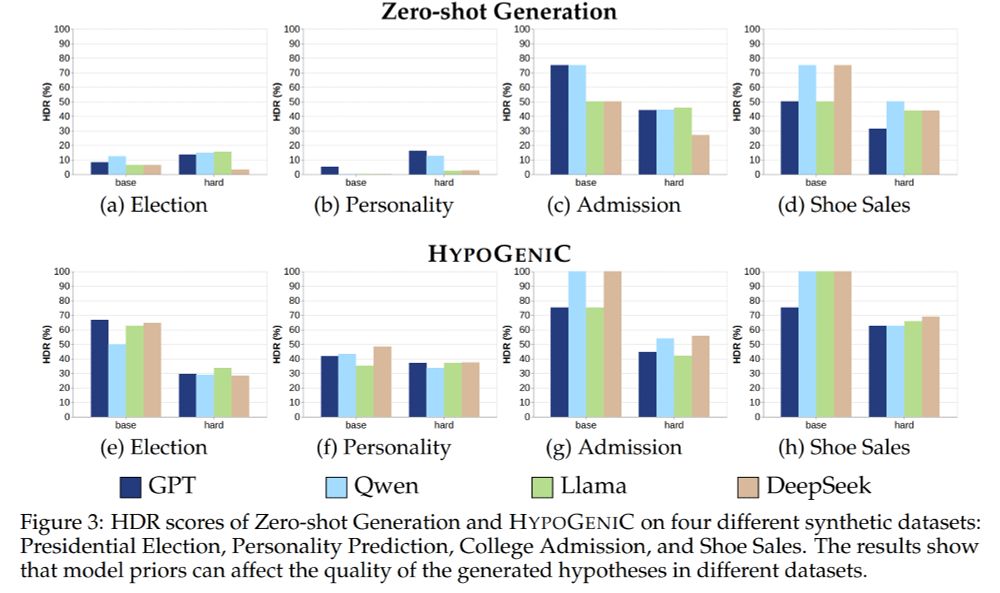
HypoBench: Towards Systematic and Principled Benchmarking for Hypothesis Generation
There is growing interest in hypothesis generation with large language models (LLMs). However, fundamental questions remain: what makes a good hypothesis, and how can we systematically evaluate method...
arxiv.org
Haokun Liu
@haokunliu.bsky.social
· Apr 28
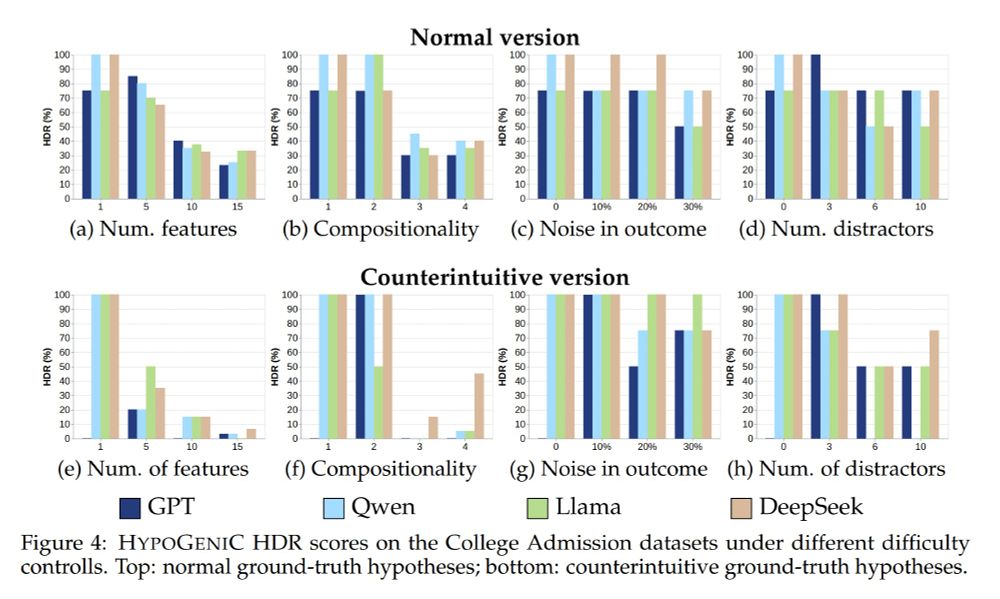
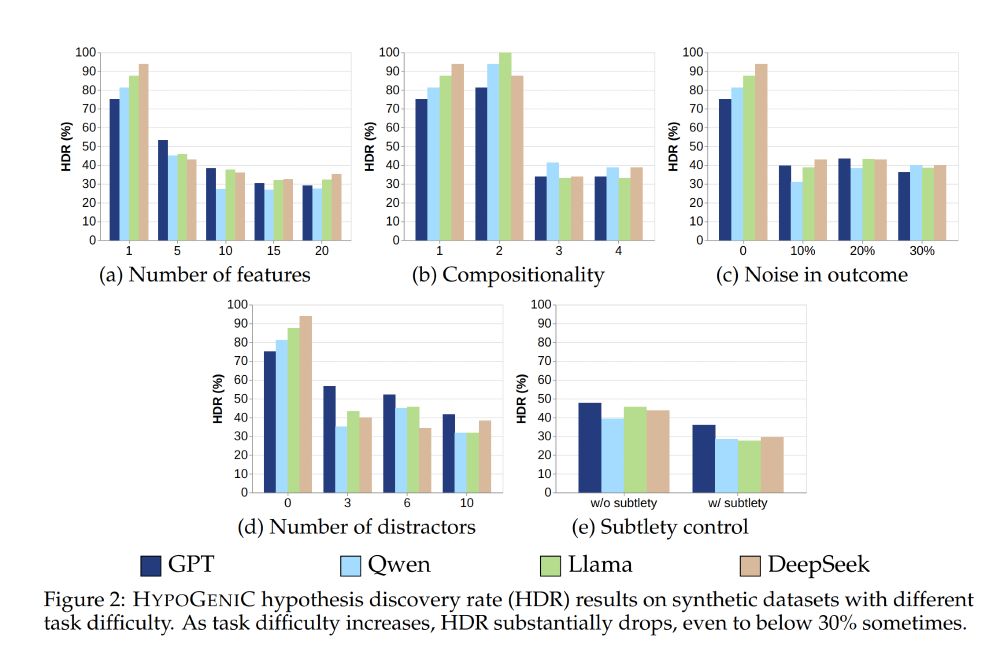
Haokun Liu
@haokunliu.bsky.social
· Apr 28
Haokun Liu
@haokunliu.bsky.social
· Apr 28
Haokun Liu
@haokunliu.bsky.social
· Apr 28
Haokun Liu
@haokunliu.bsky.social
· Apr 28
Haokun Liu
@haokunliu.bsky.social
· Apr 28
Haokun Liu
@haokunliu.bsky.social
· Apr 28
Haokun Liu
@haokunliu.bsky.social
· Apr 28