Akhila Yerukola
@akhilayerukola.bsky.social
390 followers
230 following
18 posts
PhD student at CMU LTI; Interested in pragmatics and cross-cultural understanding;
intern @ Allen Institute for AI |Prev: Senior Research Engineer @ Samsung Research America | Masters @ Stanford
https://akhila-yerukola.github.io/
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Akhila Yerukola


Reposted by Akhila Yerukola


Reposted by Akhila Yerukola

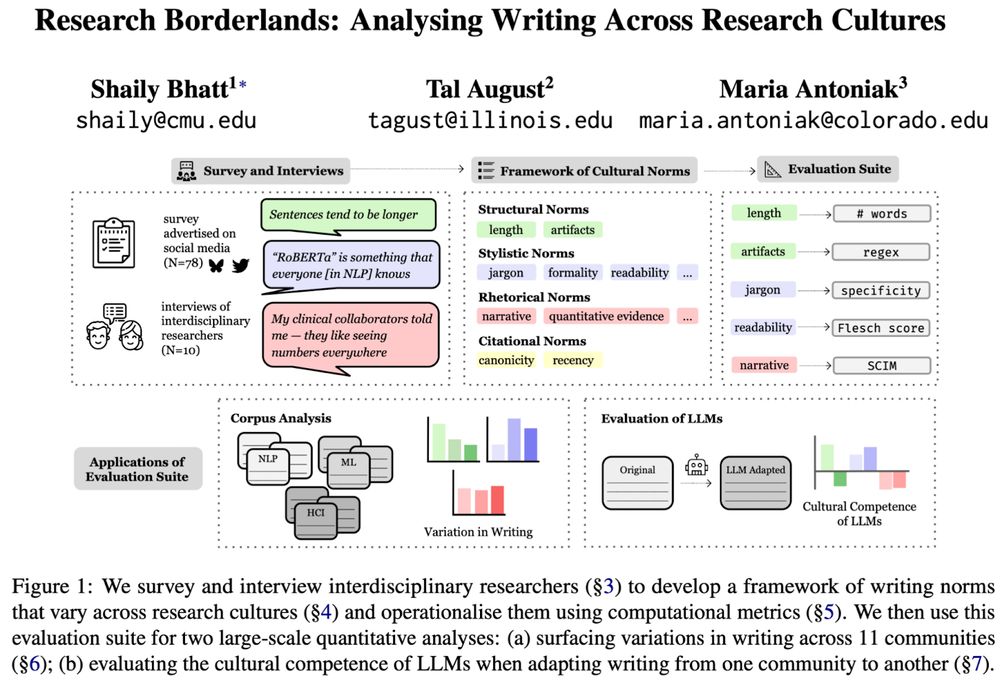
Reposted by Akhila Yerukola

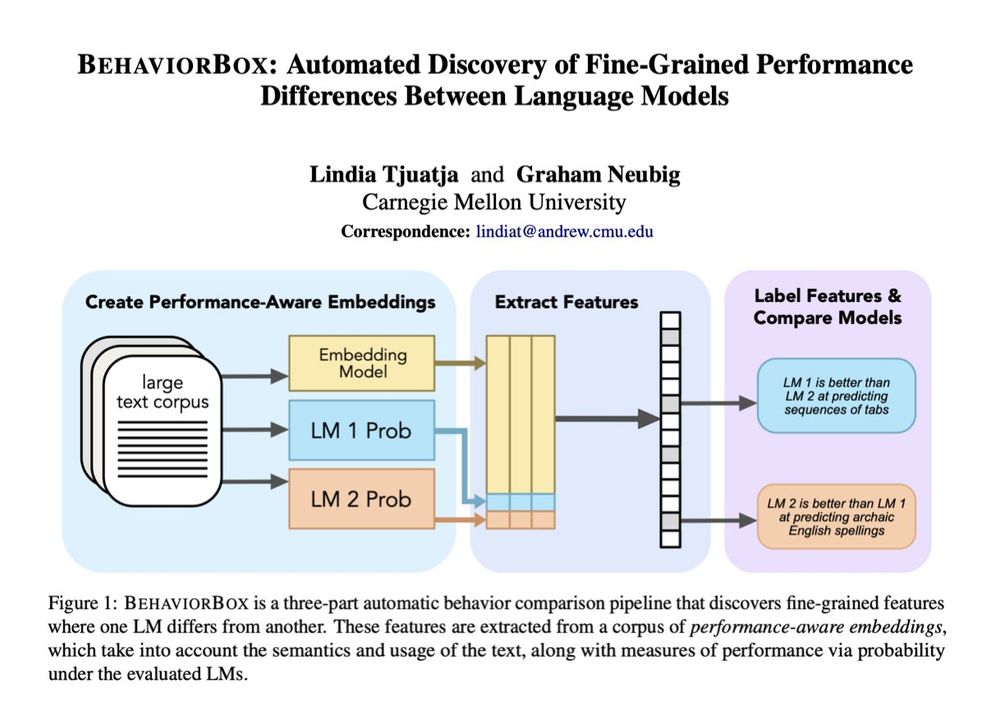
Reposted by Akhila Yerukola
Reposted by Akhila Yerukola





Reposted by Akhila Yerukola


Reposted by Akhila Yerukola

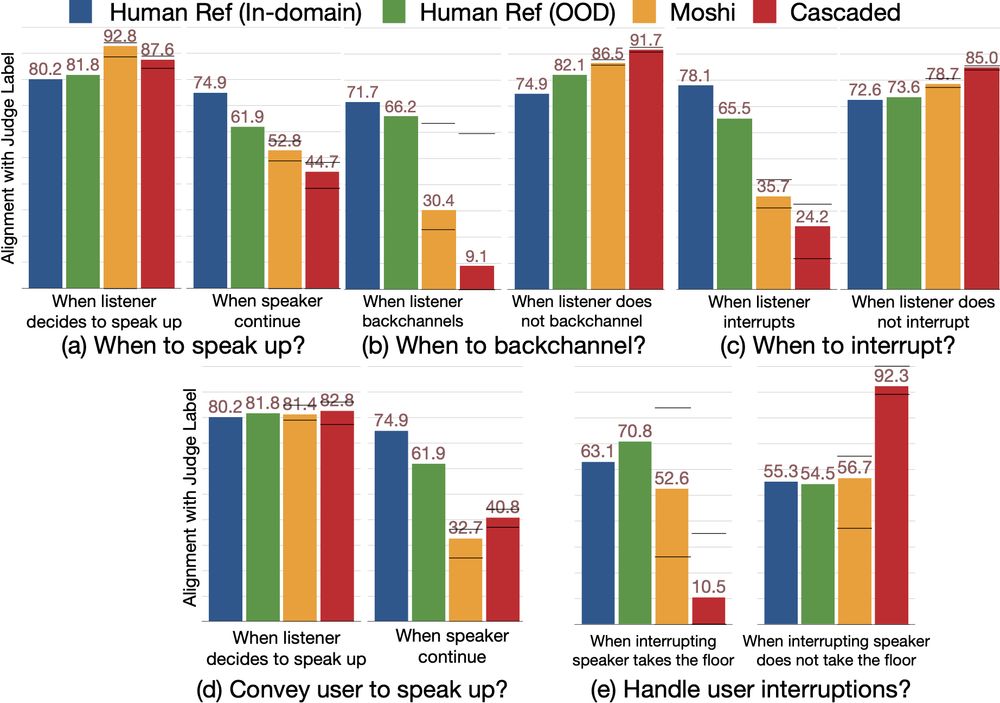
Reposted by Akhila Yerukola
Reposted by Akhila Yerukola

Maarten Sap
@maartensap.bsky.social
· Feb 26


