
Jaap Jumelet
@jumelet.bsky.social
700 followers
270 following
32 posts
Postdoc @rug.nl with Arianna Bisazza.
Interested in NLP, interpretability, syntax, language acquisition and typology.
Posts
Media
Videos
Starter Packs
Pinned

Jaap Jumelet
@jumelet.bsky.social
· Sep 1

Reposted by Jaap Jumelet


Jaap Jumelet
@jumelet.bsky.social
· Jul 1
Reposted by Jaap Jumelet

Arianna Bisazza
@arianna-bis.bsky.social
· Jun 19

TurBLiMP: A Turkish Benchmark of Linguistic Minimal Pairs
We introduce TurBLiMP, the first Turkish benchmark of linguistic minimal pairs, designed to evaluate the linguistic abilities of monolingual and multilingual language models (LMs). Covering 16 linguis...
arxiv.org
Reposted by Jaap Jumelet


Jaap Jumelet
@jumelet.bsky.social
· Jun 12
Reposted by Jaap Jumelet


Reposted by Jaap Jumelet

Francesca Padovani
@frap98.bsky.social
· May 30

Child-Directed Language Does Not Consistently Boost Syntax Learning in Language Models
Seminal work by Huebner et al. (2021) showed that language models (LMs) trained on English Child-Directed Language (CDL) can reach similar syntactic abilities as LMs trained on much larger amounts of ...
arxiv.org
Reposted by Jaap Jumelet

Neil Renic
@ncrenic.bsky.social
· May 28

University: a good idea | Patrick Porter | The Critic Magazine
A former student of mine has penned an attack on universities, derived from their own disappointing experience studying Politics and International Relations at the place where I ply my trade. In short...
thecritic.co.uk

Reposted by Jaap Jumelet


Reposted by Jaap Jumelet


Reposted by Jaap Jumelet

Seth Aycock
@sethjsa.bsky.social
· Apr 25

Can LLMs Really Learn to Translate a Low-Resource Language from One Grammar Book?
Extremely low-resource (XLR) languages lack substantial corpora for training NLP models, motivating the use of all available resources such as dictionaries and grammar books. Machine Translation from ...
arxiv.org
Jaap Jumelet
@jumelet.bsky.social
· Apr 23
Reposted by Jaap Jumelet


Jaap Jumelet
@jumelet.bsky.social
· Apr 17
Reposted by Jaap Jumelet
Reposted by Jaap Jumelet
Jaap Jumelet
@jumelet.bsky.social
· Apr 7

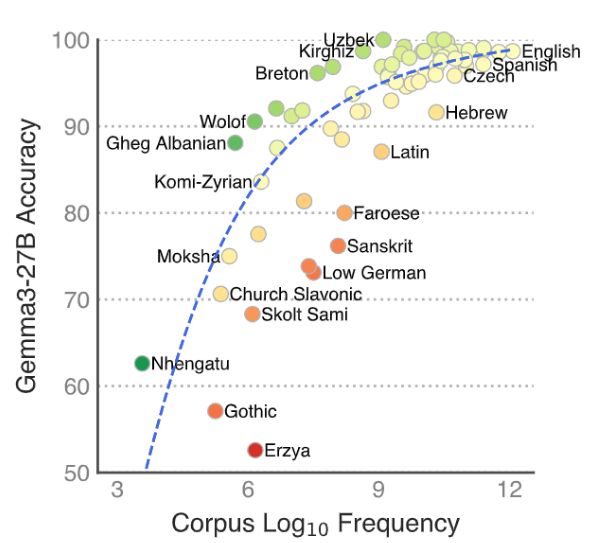
MultiBLiMP 1.0: A Massively Multilingual Benchmark of Linguistic Minimal Pairs
We introduce MultiBLiMP 1.0, a massively multilingual benchmark of linguistic minimal pairs, covering 101 languages, 6 linguistic phenomena and containing more than 125,000 minimal pairs. Our minimal ...
arxiv.org




