Mohsen Zakeri
@mohsenzakeri.bsky.social
630 followers
130 following
15 posts
Postdoctoral Fellow at Johns Hopkins University, Computational Biology ❤️
www.mohsenzakeri.com
Posts
Media
Videos
Starter Packs
Reposted by Mohsen Zakeri
Reposted by Mohsen Zakeri




Reposted by Mohsen Zakeri
Reposted by Mohsen Zakeri
Reposted by Mohsen Zakeri
Reposted by Mohsen Zakeri

Mia Farrow
@miafarrow.bsky.social
· Jun 20
Reposted by Mohsen Zakeri

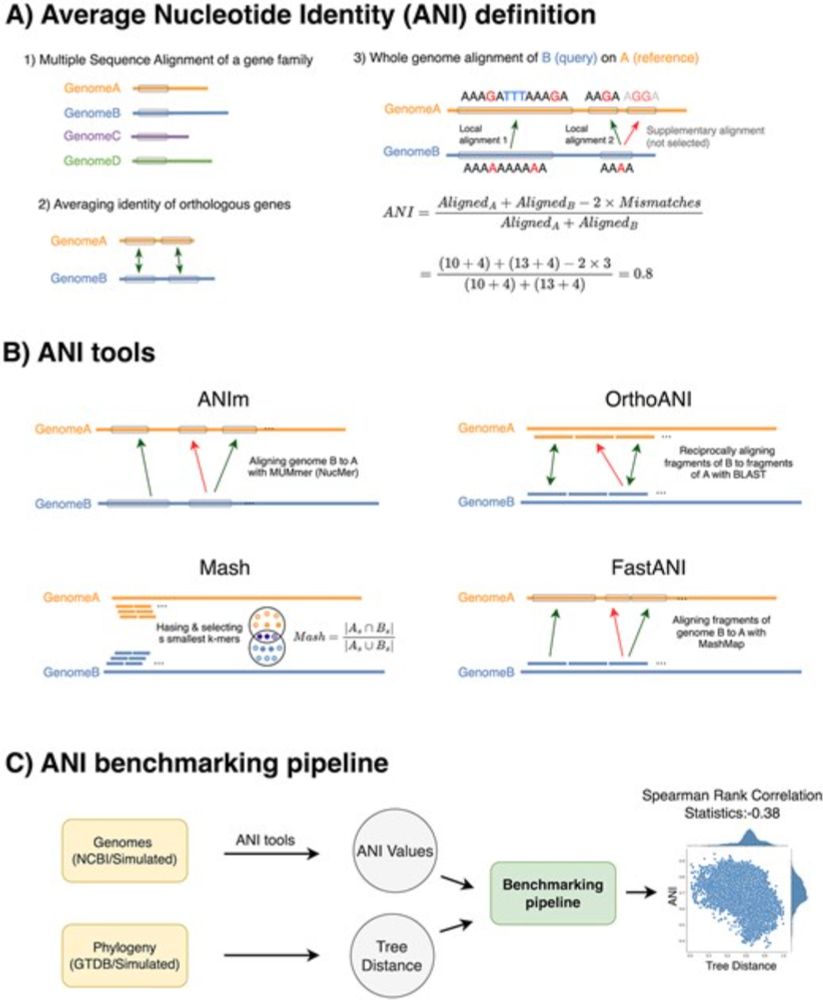
Kuan-Hao Chao
@kuanhaochao.bsky.social
· Jun 17

Reposted by Mohsen Zakeri





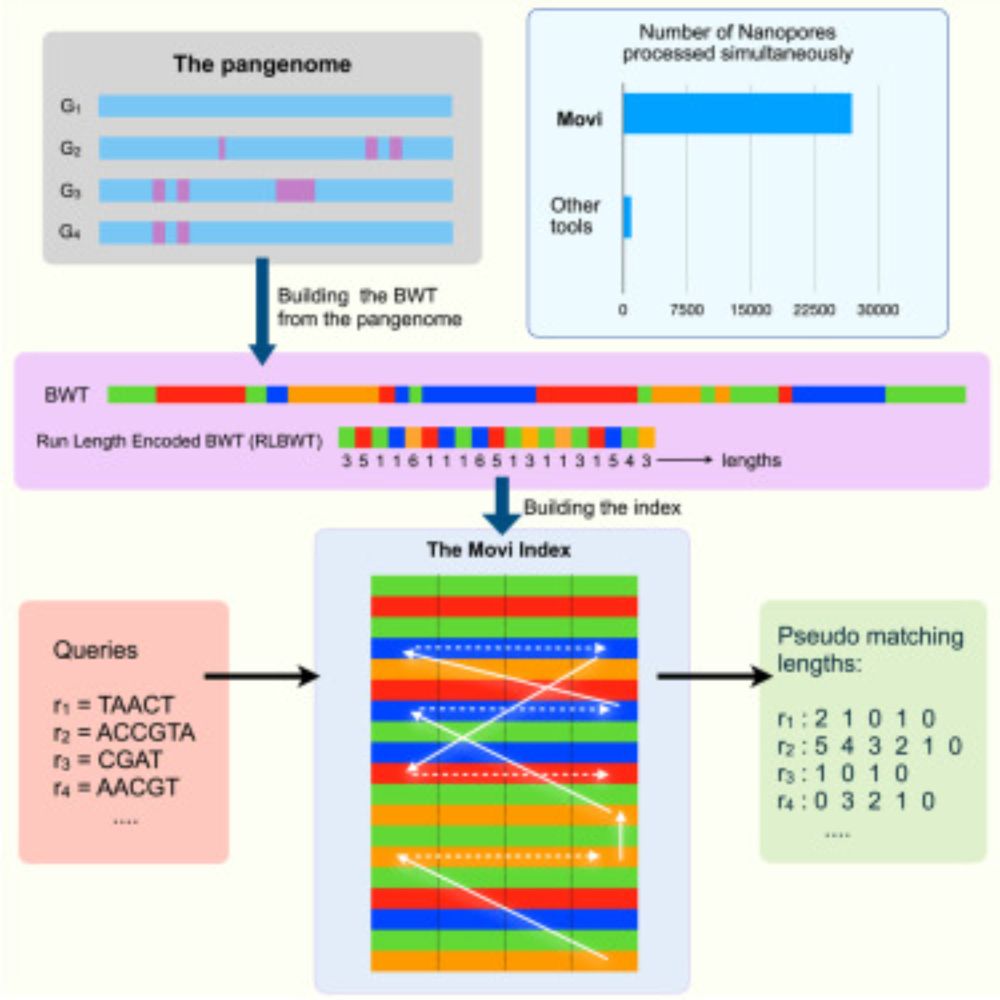
Mohsen Zakeri
@mohsenzakeri.bsky.social
· May 29

Reposted by Mohsen Zakeri
Reposted by Mohsen Zakeri

Reposted by Mohsen Zakeri


Reposted by Mohsen Zakeri
Reposted by Mohsen Zakeri

Reposted by Mohsen Zakeri

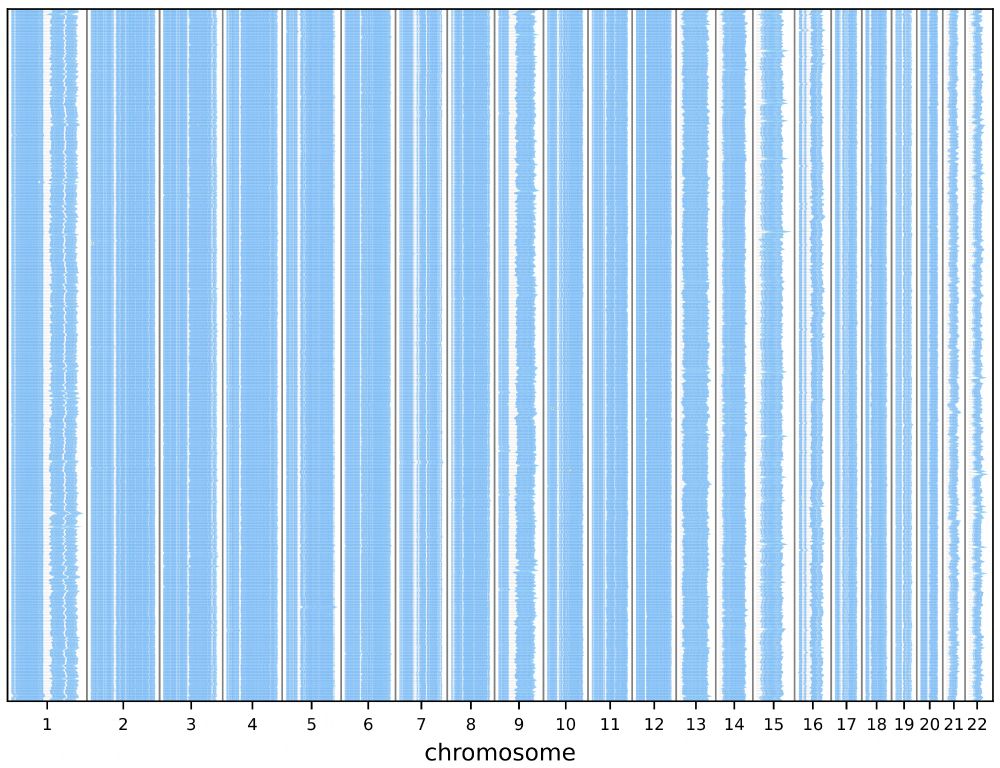
Reposted by Mohsen Zakeri