Sebastian Loeschcke
@sloeschcke.bsky.social
340 followers
200 following
25 posts
Working on Efficient Training, Low-Rank Methods, and Quantization.
PhD at the University of Copenhagen 🇩🇰
Member of @belongielab.org, Danish Data Science Academy, and Pioneer Centre for AI 🤖
🔗 sebulo.github.io/
Posts
Media
Videos
Starter Packs


Reposted by Sebastian Loeschcke

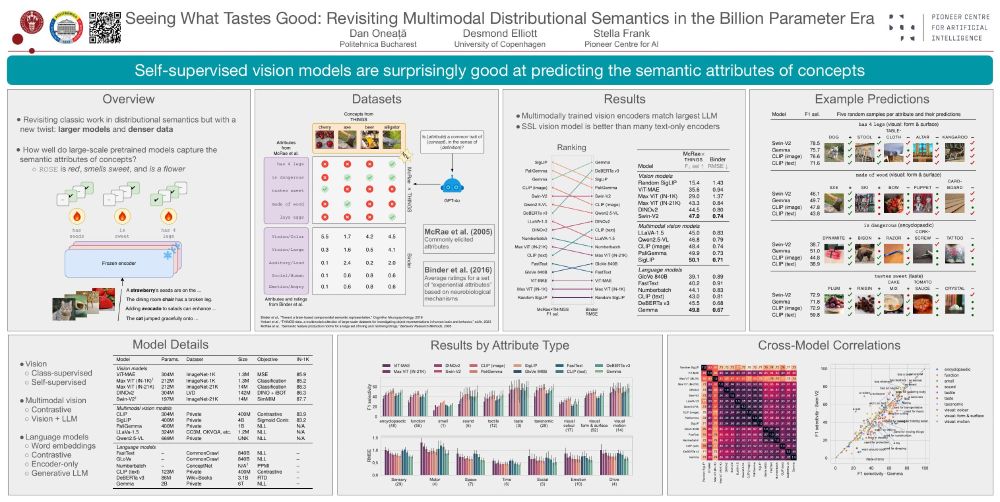








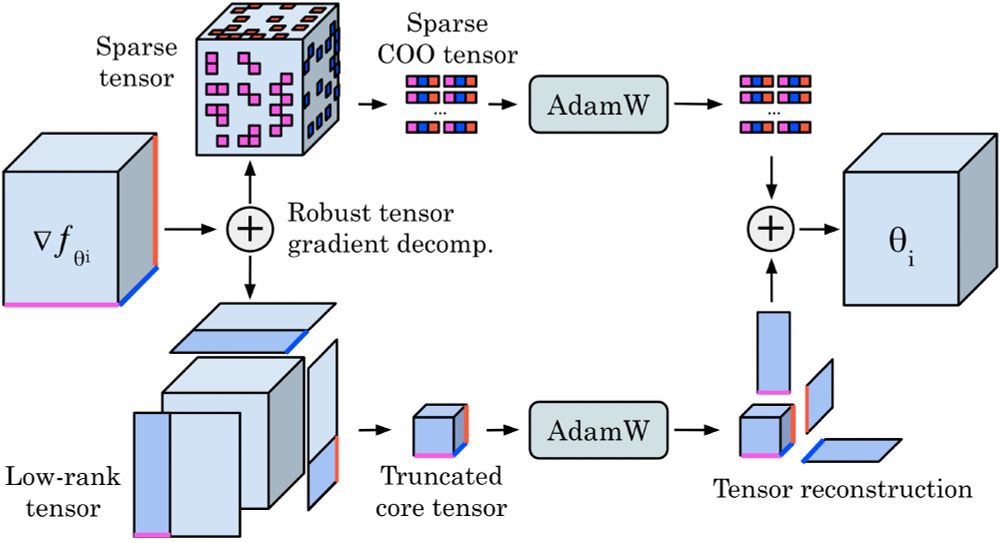
Reposted by Sebastian Loeschcke



Reposted by Sebastian Loeschcke



Reposted by Sebastian Loeschcke


Reposted by Sebastian Loeschcke

Serge Belongie
@serge.belongie.com
· Dec 16




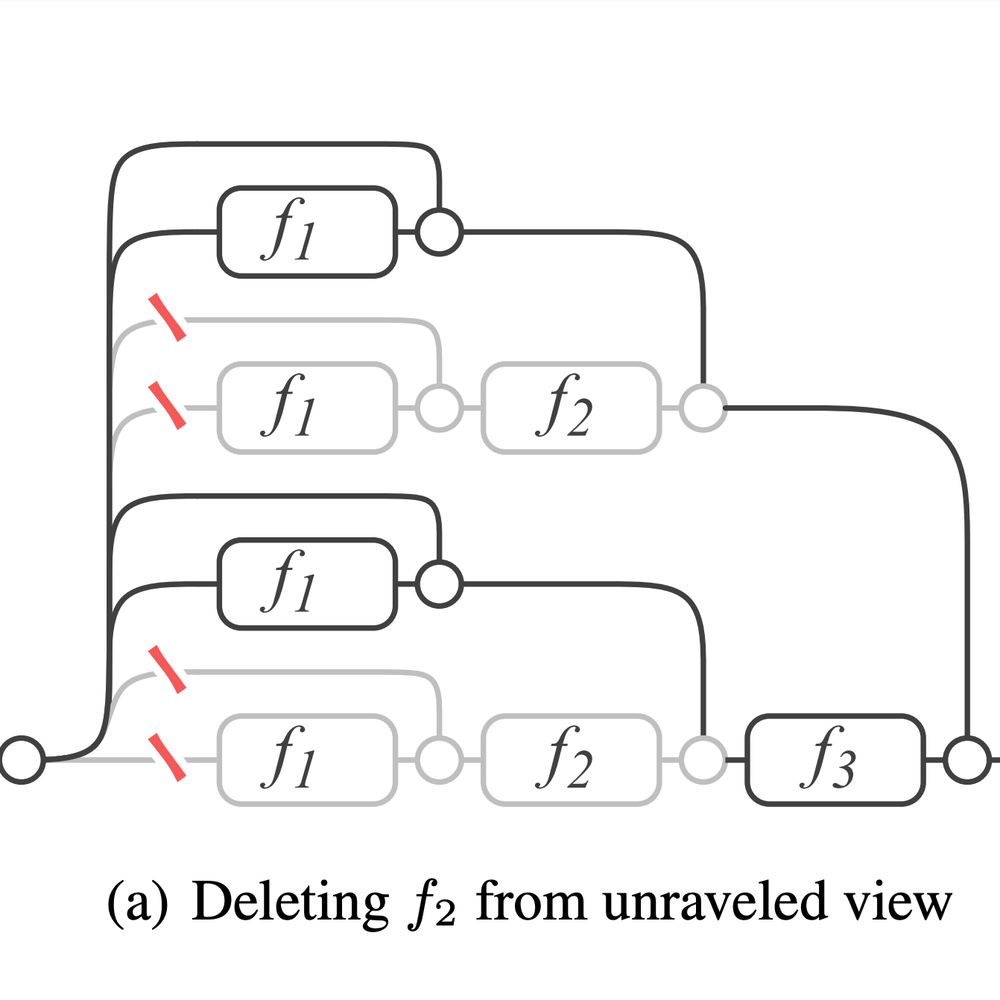
Reposted by Sebastian Loeschcke



Reposted by Sebastian Loeschcke

