
Xing Han Lu
@xhluca.bsky.social
680 followers
160 following
57 posts
👨🍳 Web Agents @mila-quebec.bsky.social
🎒 @mcgill-nlp.bsky.social
Posts
Media
Videos
Starter Packs
Reposted by Xing Han Lu

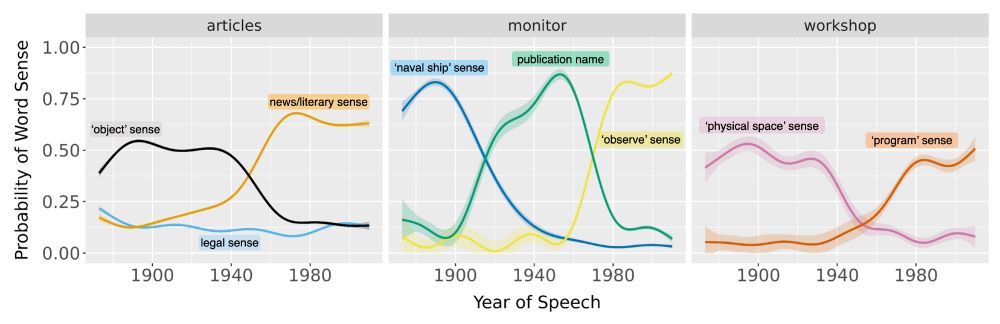
Reposted by Xing Han Lu




Reposted by Xing Han Lu


Reposted by Xing Han Lu


Xing Han Lu
@xhluca.bsky.social
· May 10
Reposted by Xing Han Lu

Reposted by Xing Han Lu



Xing Han Lu
@xhluca.bsky.social
· Apr 15
Xing Han Lu
@xhluca.bsky.social
· Apr 15
Reposted by Xing Han Lu

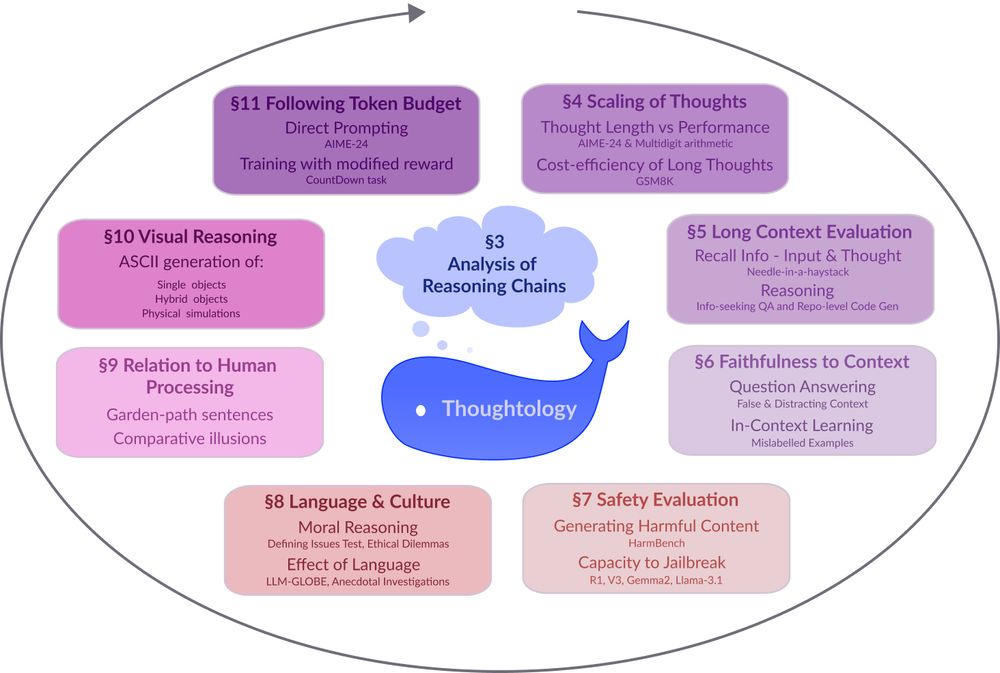

Reposted by Xing Han Lu

Reposted by Xing Han Lu
Reposted by Xing Han Lu



Reposted by Xing Han Lu



Reposted by Xing Han Lu


Reposted by Xing Han Lu
Reposted by Xing Han Lu


Xing Han Lu
@xhluca.bsky.social
· Mar 10