



Reposted by Yi-Hao Peng

MIT researchers present a framework to boost reliability in DETR object detection models, introducing a metric for calibration and uncertainty quantification. This could enhance safety in key areas like autonomous driving by pinpointing reliable predictions. https://arxiv.org/abs/2412.01782

Quantifying the Reliability of Predictions in Detection Transformers: Object-Level Calibration and Image-Level Uncertainty
ArXiv link for Quantifying the Reliability of Predictions in Detection Transformers: Object-Level Calibration and Image-Level Uncertainty
arxiv.org
December 13, 2025 at 1:31 AM
MIT researchers present a framework to boost reliability in DETR object detection models, introducing a metric for calibration and uncertainty quantification. This could enhance safety in key areas like autonomous driving by pinpointing reliable predictions. https://arxiv.org/abs/2412.01782
Reposted by Yi-Hao Peng

I put together a detailed collection of useful patterns I've collected after vibe-coding 150 different single-file HTML tools over the past couple of years simonwillison.net/2025/Dec/10/...

Useful patterns for building HTML tools
I’ve started using the term HTML tools to refer to HTML applications that I’ve been building which combine HTML, JavaScript, and CSS in a single file and use them to …
simonwillison.net
December 10, 2025 at 9:08 PM
I put together a detailed collection of useful patterns I've collected after vibe-coding 150 different single-file HTML tools over the past couple of years simonwillison.net/2025/Dec/10/...
Reposted by Yi-Hao Peng

It's finally here: The public (and most complete) version of my talk covering every stage of the process to build Olmo 3 Think. This involves changes and new considerations of every angle of the stack, from pretraining, evaluation, and of course post-training.

December 10, 2025 at 7:36 PM
It's finally here: The public (and most complete) version of my talk covering every stage of the process to build Olmo 3 Think. This involves changes and new considerations of every angle of the stack, from pretraining, evaluation, and of course post-training.
Reposted by Yi-Hao Peng

Here's a great review of what we saw in AI this year, from @gleech.org

AI in 2025: gestalt — LessWrong
This is the editorial for this year’s "Shallow Review of AI Safety". (It got long enough to stand alone.) …
www.lesswrong.com
December 8, 2025 at 5:24 PM
Here's a great review of what we saw in AI this year, from @gleech.org
Reposted by Yi-Hao Peng

This is why I always say its important to see video of robots either doing lots of stuff, or very long uncut videos. Its very easy to make a robot do one thing once

Not sure if @cpaxton.bsky.social came up with this or paraphrased it from someone else, but I’d be fine saying that “A robot demo video tells you that the robot can do no more than exactly what it did in the video” is Paxton’s Razor

at this point my default assumption is that any purportedly-autonomous thing is either following a prewritten script or is actually teleoperated
December 8, 2025 at 8:21 PM
This is why I always say its important to see video of robots either doing lots of stuff, or very long uncut videos. Its very easy to make a robot do one thing once
Reposted by Yi-Hao Peng
A theory posits that Large Language Models (LLMs) function as pattern repositories for AGI, missing a coordination layer for reasoning. The Multi-Agent Collaborative Intelligence framework enhances AI’s integration of information, reshaping our pursuit of AGI. https://arxiv.org/abs/2512.05765

The Missing Layer of AGI: From Pattern Alchemy to Coordination Physics
ArXiv link for The Missing Layer of AGI: From Pattern Alchemy to Coordination Physics
arxiv.org
December 8, 2025 at 11:11 PM
A theory posits that Large Language Models (LLMs) function as pattern repositories for AGI, missing a coordination layer for reasoning. The Multi-Agent Collaborative Intelligence framework enhances AI’s integration of information, reshaping our pursuit of AGI. https://arxiv.org/abs/2512.05765
Reposted by Yi-Hao Peng

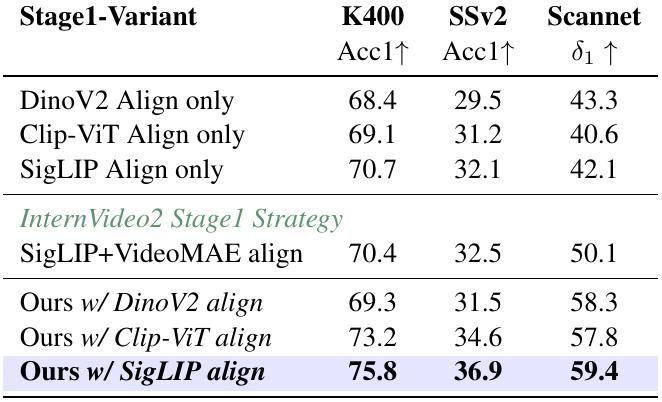
𝗜𝗻𝘁𝗲𝗿𝗻𝗩𝗶𝗱𝗲𝗼-𝗡𝗲𝘅𝘁: 𝗧𝗼𝘄𝗮𝗿𝗱𝘀 𝗚𝗲𝗻𝗲𝗿𝗮𝗹 𝗩𝗶𝗱𝗲𝗼 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹𝘀 𝘄𝗶𝘁𝗵𝗼𝘂𝘁 𝗩𝗶𝗱𝗲𝗼-𝗧𝗲𝘅𝘁 𝗦𝘂𝗽𝗲𝗿𝘃𝗶𝘀𝗶𝗼𝗻
Chenting Wang, Yuhan Zhu, Yicheng Xu ... Limin Wang
arxiv.org/abs/2512.01342
Trending on www.scholar-inbox.com
Chenting Wang, Yuhan Zhu, Yicheng Xu ... Limin Wang
arxiv.org/abs/2512.01342
Trending on www.scholar-inbox.com



December 4, 2025 at 7:00 AM
𝗜𝗻𝘁𝗲𝗿𝗻𝗩𝗶𝗱𝗲𝗼-𝗡𝗲𝘅𝘁: 𝗧𝗼𝘄𝗮𝗿𝗱𝘀 𝗚𝗲𝗻𝗲𝗿𝗮𝗹 𝗩𝗶𝗱𝗲𝗼 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹𝘀 𝘄𝗶𝘁𝗵𝗼𝘂𝘁 𝗩𝗶𝗱𝗲𝗼-𝗧𝗲𝘅𝘁 𝗦𝘂𝗽𝗲𝗿𝘃𝗶𝘀𝗶𝗼𝗻
Chenting Wang, Yuhan Zhu, Yicheng Xu ... Limin Wang
arxiv.org/abs/2512.01342
Trending on www.scholar-inbox.com
Chenting Wang, Yuhan Zhu, Yicheng Xu ... Limin Wang
arxiv.org/abs/2512.01342
Trending on www.scholar-inbox.com
Reposted by Yi-Hao Peng

Developer attempts to replicate "Liquid Glass" in CSS, and once finished realizes what she'd actually created is an exploit for a fundamental, previously unknown, and rather serious browser vulnerability
lyra.horse/blog/2025/12...
"CSS hack accidentally becomes regular hack"
lyra.horse/blog/2025/12...
"CSS hack accidentally becomes regular hack"
SVG Filters - Clickjacking 2.0
A novel and powerful twist on an old classic.
lyra.horse
December 5, 2025 at 2:03 AM
Developer attempts to replicate "Liquid Glass" in CSS, and once finished realizes what she'd actually created is an exploit for a fundamental, previously unknown, and rather serious browser vulnerability
lyra.horse/blog/2025/12...
"CSS hack accidentally becomes regular hack"
lyra.horse/blog/2025/12...
"CSS hack accidentally becomes regular hack"
Reposted by Yi-Hao Peng
LAMP enhances video generation by leveraging large language models to convert text into structured motion programs, allowing precise control over object and camera trajectories for improved cinematic storytelling and better alignment with user intent. https://arxiv.org/abs/2512.03619

LAMP: Language-Assisted Motion Planning for Controllable Video Generation
ArXiv link for LAMP: Language-Assisted Motion Planning for Controllable Video Generation
arxiv.org
December 5, 2025 at 12:41 AM
LAMP enhances video generation by leveraging large language models to convert text into structured motion programs, allowing precise control over object and camera trajectories for improved cinematic storytelling and better alignment with user intent. https://arxiv.org/abs/2512.03619
Reposted by Yi-Hao Peng
OSGym changes the game for general-purpose computer agent training, enabling over 1,000 virtual OS instances at a low cost, enhancing data gathering and model effectiveness. Open-source and geared toward academia, it seeks to democratize AI research. https://arxiv.org/abs/2511.11672

OSGym: Super-Scalable Distributed Data Engine for Generalizable Computer Agents
ArXiv link for OSGym: Super-Scalable Distributed Data Engine for Generalizable Computer Agents
arxiv.org
December 2, 2025 at 10:51 PM
OSGym changes the game for general-purpose computer agent training, enabling over 1,000 virtual OS instances at a low cost, enhancing data gathering and model effectiveness. Open-source and geared toward academia, it seeks to democratize AI research. https://arxiv.org/abs/2511.11672
Reposted by Yi-Hao Peng

Any algorithmic decision-making has both a prediction/inference AND a preference function over errors -- new NBER wp highlights how preference alignment can be too narrow within a given setting #linkoftheday
www.nber.org/system/files...
www.nber.org/system/files...

November 26, 2025 at 4:05 PM
Any algorithmic decision-making has both a prediction/inference AND a preference function over errors -- new NBER wp highlights how preference alignment can be too narrow within a given setting #linkoftheday
www.nber.org/system/files...
www.nber.org/system/files...
Reposted by Yi-Hao Peng

I am happy to share that I will be at NeurIPS in San Diego to present our paper with @rflamary.bsky.social and Bertrand Thirion on optimal transport plan prediction between graphs.
If you are around come say hi!
Paper: arxiv.org/abs/2506.12025
Poster #3703 Friday 5 December 4:30 - 7:30 pm
If you are around come say hi!
Paper: arxiv.org/abs/2506.12025
Poster #3703 Friday 5 December 4:30 - 7:30 pm

Unsupervised Learning for Optimal Transport plan prediction between unbalanced graphs
Optimal transport between graphs, based on Gromov-Wasserstein and other extensions, is a powerful tool for comparing and aligning graph structures. However, solving the associated non-convex optimizat...
arxiv.org
November 26, 2025 at 10:55 AM
I am happy to share that I will be at NeurIPS in San Diego to present our paper with @rflamary.bsky.social and Bertrand Thirion on optimal transport plan prediction between graphs.
If you are around come say hi!
Paper: arxiv.org/abs/2506.12025
Poster #3703 Friday 5 December 4:30 - 7:30 pm
If you are around come say hi!
Paper: arxiv.org/abs/2506.12025
Poster #3703 Friday 5 December 4:30 - 7:30 pm
Reposted by Yi-Hao Peng

Tencent's HunyuanOCR
An expert, end-to-end OCR model built on Hunyuan's native multimodal architecture and training strategy. This model "supposed to" achieve SOTA performance with only 1 billion parameters, significantly reducing deployment costs.
An expert, end-to-end OCR model built on Hunyuan's native multimodal architecture and training strategy. This model "supposed to" achieve SOTA performance with only 1 billion parameters, significantly reducing deployment costs.

November 25, 2025 at 6:29 AM
Tencent's HunyuanOCR
An expert, end-to-end OCR model built on Hunyuan's native multimodal architecture and training strategy. This model "supposed to" achieve SOTA performance with only 1 billion parameters, significantly reducing deployment costs.
An expert, end-to-end OCR model built on Hunyuan's native multimodal architecture and training strategy. This model "supposed to" achieve SOTA performance with only 1 billion parameters, significantly reducing deployment costs.
Reposted by Yi-Hao Peng

🚀 Introducing TMLR Beyond PDF!
🎬 This is a new, HTML-based submission format for TMLR, that supports interactive figures and videos, along with the usual LaTeX and images.
🎉 Thanks to TMLR Editors in Chief: Hugo Larochelle, @gautamkamath.com, Naila Murray, Nihar B. Shah, and Laurent Charlin!
🎬 This is a new, HTML-based submission format for TMLR, that supports interactive figures and videos, along with the usual LaTeX and images.
🎉 Thanks to TMLR Editors in Chief: Hugo Larochelle, @gautamkamath.com, Naila Murray, Nihar B. Shah, and Laurent Charlin!
November 25, 2025 at 4:12 PM
🚀 Introducing TMLR Beyond PDF!
🎬 This is a new, HTML-based submission format for TMLR, that supports interactive figures and videos, along with the usual LaTeX and images.
🎉 Thanks to TMLR Editors in Chief: Hugo Larochelle, @gautamkamath.com, Naila Murray, Nihar B. Shah, and Laurent Charlin!
🎬 This is a new, HTML-based submission format for TMLR, that supports interactive figures and videos, along with the usual LaTeX and images.
🎉 Thanks to TMLR Editors in Chief: Hugo Larochelle, @gautamkamath.com, Naila Murray, Nihar B. Shah, and Laurent Charlin!
Reposted by Yi-Hao Peng

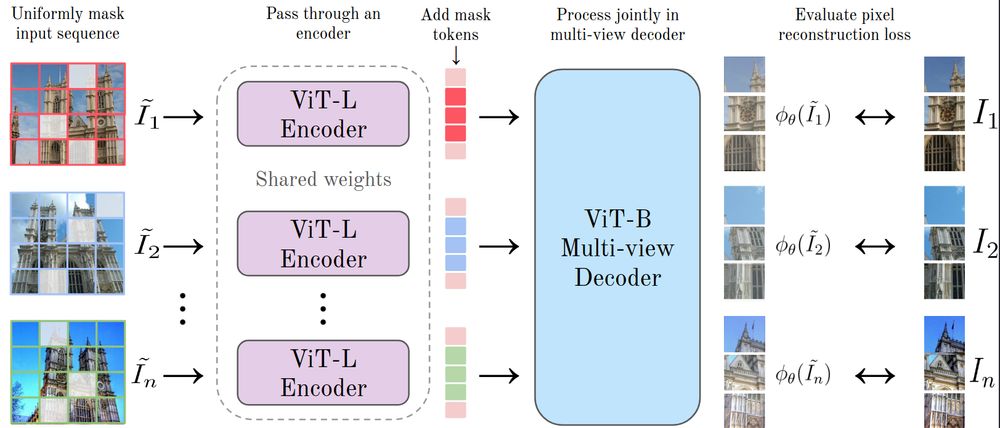
We are introducing MuM, a feature encoder (ViT-L) tailored for 3D vision tasks.
TLDR; Spiritual successor to CroCo with a simpler multi-view objective and larger scale. Beats DINOv3 and CroCo v2 in RoMa, feedforward reconstruction, and rel. pose.
arxiv.org/abs/2511.17309
github.com/davnords/mum
TLDR; Spiritual successor to CroCo with a simpler multi-view objective and larger scale. Beats DINOv3 and CroCo v2 in RoMa, feedforward reconstruction, and rel. pose.
arxiv.org/abs/2511.17309
github.com/davnords/mum
November 24, 2025 at 10:27 AM
We are introducing MuM, a feature encoder (ViT-L) tailored for 3D vision tasks.
TLDR; Spiritual successor to CroCo with a simpler multi-view objective and larger scale. Beats DINOv3 and CroCo v2 in RoMa, feedforward reconstruction, and rel. pose.
arxiv.org/abs/2511.17309
github.com/davnords/mum
TLDR; Spiritual successor to CroCo with a simpler multi-view objective and larger scale. Beats DINOv3 and CroCo v2 in RoMa, feedforward reconstruction, and rel. pose.
arxiv.org/abs/2511.17309
github.com/davnords/mum
Reposted by Yi-Hao Peng
Is a pixel-level autoregressive model the one model to rule vision?
Google DeepMind suggests that pixel-by-pixel autoregressive modeling may scale into a truly unified vision paradigm. Their study shows that as resolution increases, model size must grow much faster than the dataset,
Google DeepMind suggests that pixel-by-pixel autoregressive modeling may scale into a truly unified vision paradigm. Their study shows that as resolution increases, model size must grow much faster than the dataset,

November 25, 2025 at 12:31 AM
Is a pixel-level autoregressive model the one model to rule vision?
Google DeepMind suggests that pixel-by-pixel autoregressive modeling may scale into a truly unified vision paradigm. Their study shows that as resolution increases, model size must grow much faster than the dataset,
Google DeepMind suggests that pixel-by-pixel autoregressive modeling may scale into a truly unified vision paradigm. Their study shows that as resolution increases, model size must grow much faster than the dataset,
Reposted by Yi-Hao Peng
Initial impressions (and pelicans) of Claude Opus 4.5, Anthropic's new "best model in the world for coding" released this morning. simonwillison.net/2025/Nov/24/...

Claude Opus 4.5, and why evaluating new LLMs is increasingly difficult
Anthropic released Claude Opus 4.5 this morning, which they call “best model in the world for coding, agents, and computer use”. This is their attempt to retake the crown for …
simonwillison.net
November 24, 2025 at 7:38 PM
Initial impressions (and pelicans) of Claude Opus 4.5, Anthropic's new "best model in the world for coding" released this morning. simonwillison.net/2025/Nov/24/...
Reposted by Yi-Hao Peng
Microsoft's Fara-7B (Open-weight)
Their first agentic small language model for computer use. This experimental model includes robust safety measures to aid responsible deployment.
Blog: www.microsoft.com/en-us/resear...
Model: huggingface.co/microsoft/Fa...
Their first agentic small language model for computer use. This experimental model includes robust safety measures to aid responsible deployment.
Blog: www.microsoft.com/en-us/resear...
Model: huggingface.co/microsoft/Fa...

Fara-7B: An efficient agentic small language model for computer use
Fara-7B is our first agentic small language model for computer use. This experimental model includes robust safety measures to aid responsible deployment. Despite its size, Fara-7B holds its own again...
www.microsoft.com
November 25, 2025 at 12:16 AM
Microsoft's Fara-7B (Open-weight)
Their first agentic small language model for computer use. This experimental model includes robust safety measures to aid responsible deployment.
Blog: www.microsoft.com/en-us/resear...
Model: huggingface.co/microsoft/Fa...
Their first agentic small language model for computer use. This experimental model includes robust safety measures to aid responsible deployment.
Blog: www.microsoft.com/en-us/resear...
Model: huggingface.co/microsoft/Fa...
Reposted by Yi-Hao Peng

Breaking: we release a fully synthetic generalist dataset for pretraining, SYNTH and two new SOTA reasoning models exclusively trained on it. Despite having seen only 200 billion tokens, Baguettotron is currently best-in-class in its size range. pleias.fr/blog/blogsyn...

November 10, 2025 at 5:30 PM
Breaking: we release a fully synthetic generalist dataset for pretraining, SYNTH and two new SOTA reasoning models exclusively trained on it. Despite having seen only 200 billion tokens, Baguettotron is currently best-in-class in its size range. pleias.fr/blog/blogsyn...
Reposted by Yi-Hao Peng
The first research on the fundamentals of character training -- i.e. applying modern post training techniques to ingrain specific character traits into models.
All models, datasets, code etc released.
Really excited about this project! Sharan, the lead student author, was a joy to work with.
All models, datasets, code etc released.
Really excited about this project! Sharan, the lead student author, was a joy to work with.


November 4, 2025 at 4:51 PM
The first research on the fundamentals of character training -- i.e. applying modern post training techniques to ingrain specific character traits into models.
All models, datasets, code etc released.
Really excited about this project! Sharan, the lead student author, was a joy to work with.
All models, datasets, code etc released.
Really excited about this project! Sharan, the lead student author, was a joy to work with.
Reposted by Yi-Hao Peng

Great overview of the workshops and tutorials.
My favorites:
1) CAD representation
2) synthetic data to help city-scale reconstruction
3) trends in 3D vision
4) visual chain-of-thoughts?
My favorites:
1) CAD representation
2) synthetic data to help city-scale reconstruction
3) trends in 3D vision
4) visual chain-of-thoughts?




November 3, 2025 at 1:06 PM
Great overview of the workshops and tutorials.
My favorites:
1) CAD representation
2) synthetic data to help city-scale reconstruction
3) trends in 3D vision
4) visual chain-of-thoughts?
My favorites:
1) CAD representation
2) synthetic data to help city-scale reconstruction
3) trends in 3D vision
4) visual chain-of-thoughts?
Reposted by Yi-Hao Peng
Instance-Level Composed Image Retrieval
@billpsomas.bsky.social George Retsinas @nikos-efth.bsky.social Panagiotis Filntisis,Yannis Avrithis, Petros Maragos, Ondrej Chum, @gtolias.bsky.social
tl;dr: condition-based retrieval (+dataset) - old photo/sunset/night/aerial/model arxiv.org/abs/2510.25387
@billpsomas.bsky.social George Retsinas @nikos-efth.bsky.social Panagiotis Filntisis,Yannis Avrithis, Petros Maragos, Ondrej Chum, @gtolias.bsky.social
tl;dr: condition-based retrieval (+dataset) - old photo/sunset/night/aerial/model arxiv.org/abs/2510.25387




November 3, 2025 at 12:53 PM
Instance-Level Composed Image Retrieval
@billpsomas.bsky.social George Retsinas @nikos-efth.bsky.social Panagiotis Filntisis,Yannis Avrithis, Petros Maragos, Ondrej Chum, @gtolias.bsky.social
tl;dr: condition-based retrieval (+dataset) - old photo/sunset/night/aerial/model arxiv.org/abs/2510.25387
@billpsomas.bsky.social George Retsinas @nikos-efth.bsky.social Panagiotis Filntisis,Yannis Avrithis, Petros Maragos, Ondrej Chum, @gtolias.bsky.social
tl;dr: condition-based retrieval (+dataset) - old photo/sunset/night/aerial/model arxiv.org/abs/2510.25387
Reposted by Yi-Hao Peng

💡Can we trust synthetic data for statistical inference?
We show that synthetic data (e.g., LLM simulations) can significantly improve the performance of inference tasks. The key intuition lies in the interactions between the moment residuals of synthetic data and those of real data
We show that synthetic data (e.g., LLM simulations) can significantly improve the performance of inference tasks. The key intuition lies in the interactions between the moment residuals of synthetic data and those of real data

October 10, 2025 at 4:12 PM
💡Can we trust synthetic data for statistical inference?
We show that synthetic data (e.g., LLM simulations) can significantly improve the performance of inference tasks. The key intuition lies in the interactions between the moment residuals of synthetic data and those of real data
We show that synthetic data (e.g., LLM simulations) can significantly improve the performance of inference tasks. The key intuition lies in the interactions between the moment residuals of synthetic data and those of real data
Reposted by Yi-Hao Peng

We have a new sequence model for robotics, which will be presented at #NeurIPS2025:
Kinaema: A recurrent sequence model for memory and pose in motion
arxiv.org/abs/2510.20261
By @mbsariyildiz.bsky.social, @weinzaepfelp.bsky.social, G. Bono, G. Monaci and myself
@naverlabseurope.bsky.social
1/9
Kinaema: A recurrent sequence model for memory and pose in motion
arxiv.org/abs/2510.20261
By @mbsariyildiz.bsky.social, @weinzaepfelp.bsky.social, G. Bono, G. Monaci and myself
@naverlabseurope.bsky.social
1/9

October 24, 2025 at 7:18 AM
We have a new sequence model for robotics, which will be presented at #NeurIPS2025:
Kinaema: A recurrent sequence model for memory and pose in motion
arxiv.org/abs/2510.20261
By @mbsariyildiz.bsky.social, @weinzaepfelp.bsky.social, G. Bono, G. Monaci and myself
@naverlabseurope.bsky.social
1/9
Kinaema: A recurrent sequence model for memory and pose in motion
arxiv.org/abs/2510.20261
By @mbsariyildiz.bsky.social, @weinzaepfelp.bsky.social, G. Bono, G. Monaci and myself
@naverlabseurope.bsky.social
1/9
Reposted by Yi-Hao Peng

October 20, 2025 at 11:49 PM