Czech Republic
The Czech Republic, also known as Czechia and historically known as Bohemia, is a landlocked country in Central Europe. The… more







Reposted by: Czech Republic
Processing and acquisition traces in visual encoders: What does CLIP know about your camera?
arxiv.org/abs/2508.10637
To be presented at #ICCV2025 (highlight). @iccv.bsky.social
Reposted by: Czech Republic

vrg.fel.cvut.cz/ilias/
Reposted by: Czech Republic

Instance-Level Recognition and Generation (ILR+G) Workshop at ICCV2025 @iccv.bsky.social
📅 new deadline: June 26, 2025 (23:59 AoE)
📄 paper submission: cmt3.research.microsoft.com/ILRnG2025
🌐 ILR+G website: ilr-workshop.github.io/ICCVW2025/
#ICCV2025 #ComputerVision #AI

Reposted by: Czech Republic



Reposted by: Czech Republic
Reposted by: Czech Republic
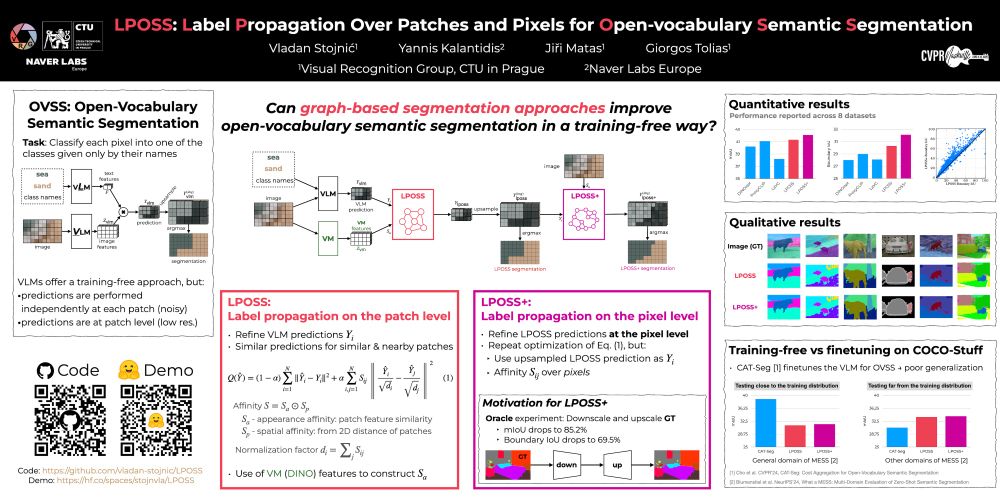
We show how can graph-based label propagation be used to improve weak, patch-level predictions from VLMs for open-vocabulary semantic segmentation.
📅 June 13, 2025, 16:00 – 18:00 CDT
📍 Location: ExHall D, Poster #421
Reposted by: Czech Republic
📅 Sat 14/6, 10:30-12:30
📍 Poster #395, ExHall D

Sat 10:30-12:30 ILIAS: Instance-Level Image retrieval At Scale
Fri 10:30-12:30 A Dataset for Semantic Segmentation in the Presence of Unknowns
Fri 16:00-18:00 LOCORE: Image Re-ranking with Long-Context Sequence Modeling
Reposted by: Czech Republic
We will now feature a single submission track with new submission dates.
📅 New submission deadline: June 21, 2025
🔗 Submit here: cmt3.research.microsoft.com/ILRnG2025
🌐 More details: ilr-workshop.github.io/ICCVW2025/
#ICCV2025
Reposted by: Czech Republic

