




Fabien Plisson
@fabienplisson.bsky.social
BioDesign, Machine Learning, Drug Discovery | Rosenkranz Award 2021 | Dad | Polyglot | Capybarist | plissonf.github.io
Founding ingeniebio.com
ORCID 0000-0003-224
Founding ingeniebio.com
ORCID 0000-0003-224
Pinned
Fabien Plisson
@fabienplisson.bsky.social
· Nov 10
Ingenie Bio | biomolecular design
Ingenie Bio integrates data-driven solutions to support biomolecular design across drug discovery and beyond.
ingeniebio.com
Happy to launch Iɴɢᴇɴɪᴇ Bɪᴏ, a consulting firm offering data-driven solutions for biomolecular discovery and design! We specialize in AI-driven molecular design, computational chemistry, and more. Let's collaborate! Visit ingeniebio.com #AI #ML #drugdiscovery
Reposted by Fabien Plisson

NSF Invests Nearly $32M to Accelerate Novel AI-Driven Approaches in Protein Design
ow.ly/NJzp50WCc00 #NSF #AIwire
ow.ly/NJzp50WCc00 #NSF #AIwire

NSF Invests Nearly $32M to Accelerate Novel AI-Driven Approaches in Protein Design
Aug. 8, 2025 -- The U.S. National Science Foundation Directorate for Technology, Innovation and Partnerships (NSF TIP) announced an inaugural investment
ow.ly
August 8, 2025 at 5:45 PM
NSF Invests Nearly $32M to Accelerate Novel AI-Driven Approaches in Protein Design
ow.ly/NJzp50WCc00 #NSF #AIwire
ow.ly/NJzp50WCc00 #NSF #AIwire
Reposted by Fabien Plisson

Worth a watch:
Head of Signal, Meredith Whittaker, on so-called "agentic AI" and the difference between how it's described in the marketing and what access and control it would actually require to work as advertised.
Head of Signal, Meredith Whittaker, on so-called "agentic AI" and the difference between how it's described in the marketing and what access and control it would actually require to work as advertised.
June 26, 2025 at 4:28 PM
Worth a watch:
Head of Signal, Meredith Whittaker, on so-called "agentic AI" and the difference between how it's described in the marketing and what access and control it would actually require to work as advertised.
Head of Signal, Meredith Whittaker, on so-called "agentic AI" and the difference between how it's described in the marketing and what access and control it would actually require to work as advertised.
Reposted by Fabien Plisson

Think coronavirus spikes have run out of surprises? Think again.
Our latest preprint dives into the highly unusual spikes of marine mammal coronaviruses.
www.biorxiv.org/content/10.1...
This #cryoEM study was led by @viralfusion.bsky.social, with key contributions from an amazing team.
Our latest preprint dives into the highly unusual spikes of marine mammal coronaviruses.
www.biorxiv.org/content/10.1...
This #cryoEM study was led by @viralfusion.bsky.social, with key contributions from an amazing team.
May 23, 2025 at 5:02 AM
Think coronavirus spikes have run out of surprises? Think again.
Our latest preprint dives into the highly unusual spikes of marine mammal coronaviruses.
www.biorxiv.org/content/10.1...
This #cryoEM study was led by @viralfusion.bsky.social, with key contributions from an amazing team.
Our latest preprint dives into the highly unusual spikes of marine mammal coronaviruses.
www.biorxiv.org/content/10.1...
This #cryoEM study was led by @viralfusion.bsky.social, with key contributions from an amazing team.
Never too late to publish, I am proud to see this work finally published: Tagitinin C, a Sesquiterpene Lactone, and Derivatives as Proteasome Inhibitors doi.org/10.1002/ejoc...

Tagitinin C, a Sesquiterpene Lactone, and Derivatives as Proteasome Inhibitors
Tagitinin C, a germacranolide, isolated from Tithonia diversifolia was shown to have an interesting level of activity on the proteasome pathway. It is however a particularly unstable molecule, sensit...
doi.org
May 5, 2025 at 1:32 AM
Never too late to publish, I am proud to see this work finally published: Tagitinin C, a Sesquiterpene Lactone, and Derivatives as Proteasome Inhibitors doi.org/10.1002/ejoc...
Reposted by Fabien Plisson

Choosing ML architectures for protein engineering is often challenging. Our “new” updated preprint provides a rational framework to match ML models to protein fitness tasks, showing landscape ruggedness influences prediction accuracy. Mahakaran dana Adam et al www.biorxiv.org/content/10.1...

Investigating the determinants of performance in machine learning for protein fitness prediction
Machine learning (ML) has revolutionized protein biology, solving long-standing problems in protein folding, scaffold generation and function design tasks. A range of architectures have shown success ...
www.biorxiv.org
April 22, 2025 at 12:41 PM
Choosing ML architectures for protein engineering is often challenging. Our “new” updated preprint provides a rational framework to match ML models to protein fitness tasks, showing landscape ruggedness influences prediction accuracy. Mahakaran dana Adam et al www.biorxiv.org/content/10.1...
Reposted by Fabien Plisson

Run BioEmu in Colab - just click "Runtime → Run all"! Our notebook uses ColabFold to generate MSAs, BioEmu to predict trajectories, and Foldseek to cluster conformations.
Thanks @jjimenezluna.bsky.social for the help!
🌐 colab.research.google.com/github/sokry...
📄 www.biorxiv.org/content/10.1...
Thanks @jjimenezluna.bsky.social for the help!
🌐 colab.research.google.com/github/sokry...
📄 www.biorxiv.org/content/10.1...

Google Colab
colab.research.google.com
March 29, 2025 at 9:50 AM
Run BioEmu in Colab - just click "Runtime → Run all"! Our notebook uses ColabFold to generate MSAs, BioEmu to predict trajectories, and Foldseek to cluster conformations.
Thanks @jjimenezluna.bsky.social for the help!
🌐 colab.research.google.com/github/sokry...
📄 www.biorxiv.org/content/10.1...
Thanks @jjimenezluna.bsky.social for the help!
🌐 colab.research.google.com/github/sokry...
📄 www.biorxiv.org/content/10.1...
Reposted by Fabien Plisson

Protein function often depends on protein dynamics. To design proteins that function like natural ones, how do we predict their dynamics?
@hkws.bsky.social and I are thrilled to share the first big, experimental datasets on protein dynamics and our new model: Dyna-1!
🧵
@hkws.bsky.social and I are thrilled to share the first big, experimental datasets on protein dynamics and our new model: Dyna-1!
🧵
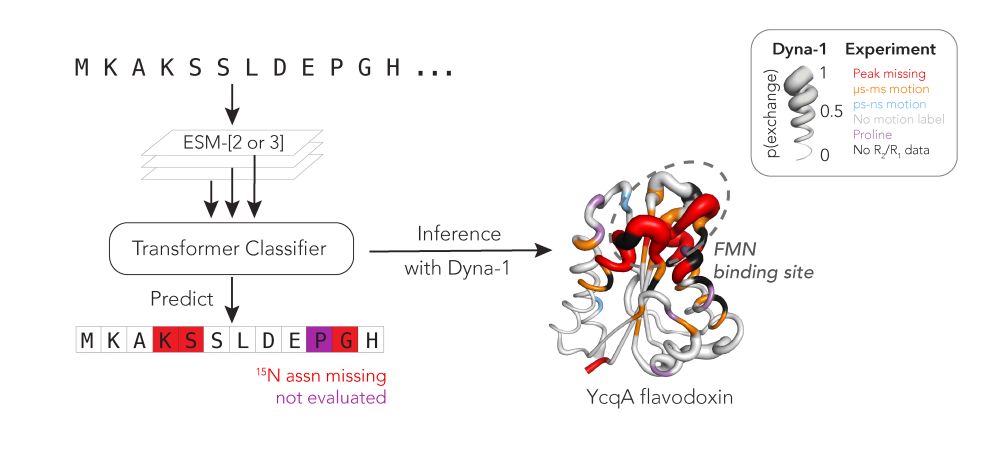
March 20, 2025 at 3:02 PM
Protein function often depends on protein dynamics. To design proteins that function like natural ones, how do we predict their dynamics?
@hkws.bsky.social and I are thrilled to share the first big, experimental datasets on protein dynamics and our new model: Dyna-1!
🧵
@hkws.bsky.social and I are thrilled to share the first big, experimental datasets on protein dynamics and our new model: Dyna-1!
🧵
Reposted by Fabien Plisson

You can download my protein structure-inspired artwork from pdb webpage:
pdb101.rcsb.org/sci-art/bezs...
@rcsbpdb.bsky.social
@pdbeurope.bsky.social
#sciart
pdb101.rcsb.org/sci-art/bezs...
@rcsbpdb.bsky.social
@pdbeurope.bsky.social
#sciart
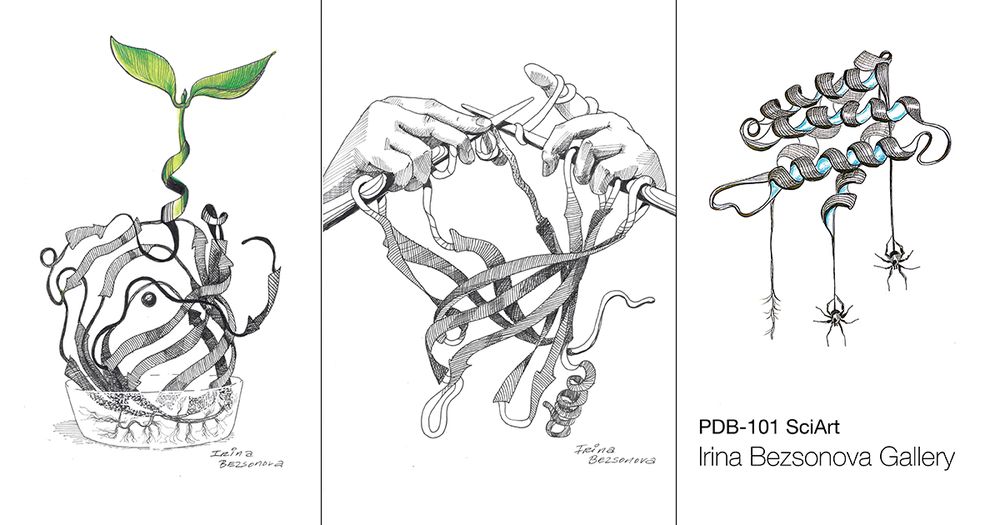
PDB101: Irina Bezsonova Gallery
PDB-101: Training, Outreach, and Education portal of RCSB PDB
pdb101.rcsb.org
March 15, 2025 at 11:42 AM
You can download my protein structure-inspired artwork from pdb webpage:
pdb101.rcsb.org/sci-art/bezs...
@rcsbpdb.bsky.social
@pdbeurope.bsky.social
#sciart
pdb101.rcsb.org/sci-art/bezs...
@rcsbpdb.bsky.social
@pdbeurope.bsky.social
#sciart
Reposted by Fabien Plisson

YouTube is the world's 2nd-largest search engine. So why aren't more conference keynotes and presentations there? 🤔
February 19, 2025 at 3:53 PM
YouTube is the world's 2nd-largest search engine. So why aren't more conference keynotes and presentations there? 🤔
Reposted by Fabien Plisson

Modern-Day Oracles or Bullshit Machines?
Jevin West (@jevinwest.bsky.social) and I have spent the last eight months developing the course on large language models (LLMs) that we think every college freshman needs to take.
thebullshitmachines.com
Jevin West (@jevinwest.bsky.social) and I have spent the last eight months developing the course on large language models (LLMs) that we think every college freshman needs to take.
thebullshitmachines.com

INTRODUCTION
thebullshitmachines.com
February 4, 2025 at 4:12 PM
Modern-Day Oracles or Bullshit Machines?
Jevin West (@jevinwest.bsky.social) and I have spent the last eight months developing the course on large language models (LLMs) that we think every college freshman needs to take.
thebullshitmachines.com
Jevin West (@jevinwest.bsky.social) and I have spent the last eight months developing the course on large language models (LLMs) that we think every college freshman needs to take.
thebullshitmachines.com
Reposted by Fabien Plisson

Short thread about this interesting preprint that explores antibody design by combining MD with inverse folding and active learning. It's a bit rough around the edges but it introduces a cool idea I hope is further fleshed out www.biorxiv.org/content/10.1...
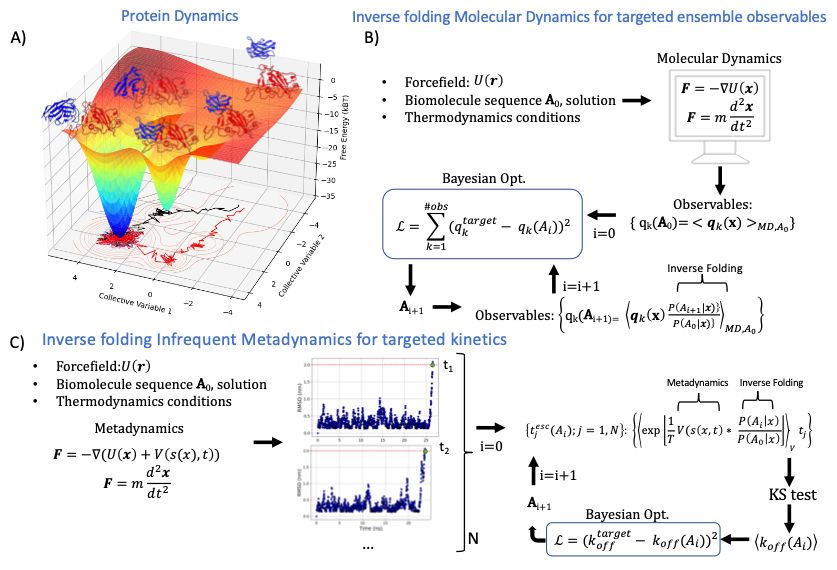
February 17, 2025 at 8:14 AM
Short thread about this interesting preprint that explores antibody design by combining MD with inverse folding and active learning. It's a bit rough around the edges but it introduces a cool idea I hope is further fleshed out www.biorxiv.org/content/10.1...
Are protein language models the universal key?
doi.org/10.1016/j.sb...
Brilliant and thoughtful piece.
doi.org/10.1016/j.sb...
Brilliant and thoughtful piece.
Redirecting
doi.org
February 13, 2025 at 2:56 AM
Are protein language models the universal key?
doi.org/10.1016/j.sb...
Brilliant and thoughtful piece.
doi.org/10.1016/j.sb...
Brilliant and thoughtful piece.
Brilliant video on the development of protein structure prediction featuring #AF2 and #Rosetta series
youtu.be/P_fHJIYENdI?...
youtu.be/P_fHJIYENdI?...
What if all the world's biggest problems have the same solution?
YouTube video by Veritasium
youtu.be
February 12, 2025 at 5:34 AM
Brilliant video on the development of protein structure prediction featuring #AF2 and #Rosetta series
youtu.be/P_fHJIYENdI?...
youtu.be/P_fHJIYENdI?...
Reposted by Fabien Plisson

(1/4)In our new paper in @cp-trendsgenetics.bsky.social @cellpress.bsky.social, we highlight some fascinating tiny proteins—microproteins—which appear to be widespread in nature. www.cell.com/trends/genet...
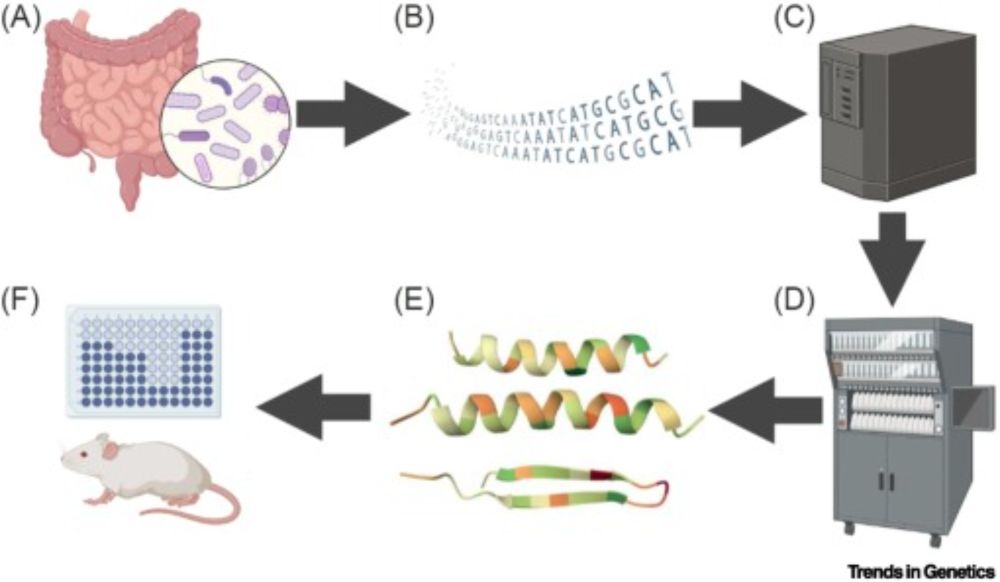
Microproteins: emerging roles as antibiotics
Recent advances in computational prediction and experimental techniques have detected
previously unknown microproteins, particularly in the human microbiome. These small
proteins, produced by diverse ...
www.cell.com
February 5, 2025 at 2:00 PM
(1/4)In our new paper in @cp-trendsgenetics.bsky.social @cellpress.bsky.social, we highlight some fascinating tiny proteins—microproteins—which appear to be widespread in nature. www.cell.com/trends/genet...
Great editorial from @evotec.bsky.social using AI+ML tools to assist drug discovery campaigns in the small and middle chemical spaces
pubs.acs.org/doi/10.1021/...
pubs.acs.org/doi/10.1021/...

Real-World Applications and Experiences of AI/ML Deployment for Drug Discovery
OR SEARCH CITATIONS
pubs.acs.org
January 30, 2025 at 8:50 AM
Great editorial from @evotec.bsky.social using AI+ML tools to assist drug discovery campaigns in the small and middle chemical spaces
pubs.acs.org/doi/10.1021/...
pubs.acs.org/doi/10.1021/...
Closer to my experience in #CompBiology - the development of AI algorithms to discover and design antimicrobial peptides against #AMR, where predictive ML models are employed to predict the antimicrobial nature (classification) or activity (regression), primarily from sequences.
January 29, 2025 at 11:37 PM
Closer to my experience in #CompBiology - the development of AI algorithms to discover and design antimicrobial peptides against #AMR, where predictive ML models are employed to predict the antimicrobial nature (classification) or activity (regression), primarily from sequences.
Drug discovery and biotechnology are multi-objective optimisation challenges. Machine learning models integrate well into an enzyme engineering pipeline to predict properties and functions. Parallelising these models allows multi-objective optimisation.
January 29, 2025 at 11:24 PM
Drug discovery and biotechnology are multi-objective optimisation challenges. Machine learning models integrate well into an enzyme engineering pipeline to predict properties and functions. Parallelising these models allows multi-objective optimisation.
Reposted by Fabien Plisson
(1/5)Venoms are an underexplored treasure trove of bioactive molecules. Our latest research taps into these evolutionary powerhouses to find a new arsenal against drug-resistant bacteria.
We introduce Venomics AI.
www.biorxiv.org/content/10.1...
We introduce Venomics AI.
www.biorxiv.org/content/10.1...

January 15, 2025 at 6:41 PM
(1/5)Venoms are an underexplored treasure trove of bioactive molecules. Our latest research taps into these evolutionary powerhouses to find a new arsenal against drug-resistant bacteria.
We introduce Venomics AI.
www.biorxiv.org/content/10.1...
We introduce Venomics AI.
www.biorxiv.org/content/10.1...
Reposted by Fabien Plisson

Many people talk about the "Golden Age of Antibiotics", but I hadn't seen it visualized properly.
Just how many types of antibiotics were discovered during that time?
So, I visualized it myself!
Just how many types of antibiotics were discovered during that time?
So, I visualized it myself!

December 23, 2024 at 10:09 AM
Many people talk about the "Golden Age of Antibiotics", but I hadn't seen it visualized properly.
Just how many types of antibiotics were discovered during that time?
So, I visualized it myself!
Just how many types of antibiotics were discovered during that time?
So, I visualized it myself!
Reposted by Fabien Plisson





December 18, 2024 at 6:11 AM
What a stunning view #SydneyOpera #Xmas

December 17, 2024 at 4:18 AM
What a stunning view #SydneyOpera #Xmas
Reposted by Fabien Plisson

This should go chiral

We did this crazy project where we tried to see if proteins could interact with their mirror image ligand. Seems impossible when proteins need to form 3D structures to interact. But what about if the interaction remains disordered???
www.nature.com/articles/s41...
www.nature.com/articles/s41...
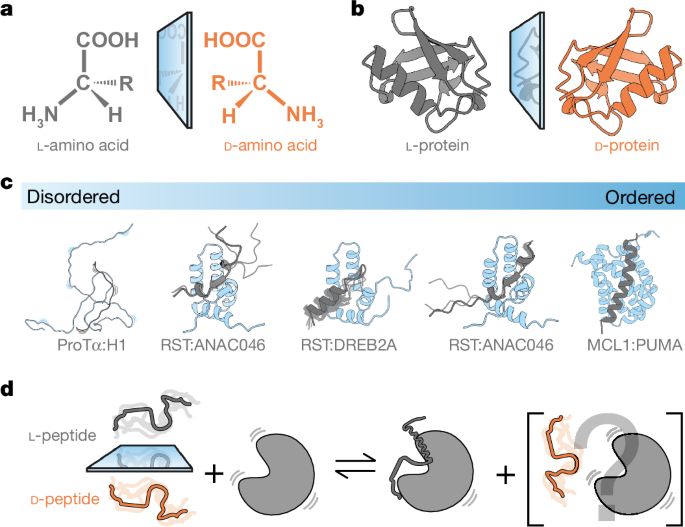
Stereochemistry in the disorder–order continuum of protein interactions - Nature
Studies on protein–protein interactions using proteins containing d- or l-amino acids show that stereoselectivity of binding varies with the degree of disorder within the complex.
www.nature.com
November 27, 2024 at 8:35 PM
This should go chiral
Reposted by Fabien Plisson

If you want to support my voyage, you can still do so here: www.chuffed.org/project/help...

Help Selene get to Antarctica
Hi! I'm Selene Fernandez, a scientist, a daughter and a mother.
www.chuffed.org
December 9, 2024 at 5:48 AM
If you want to support my voyage, you can still do so here: www.chuffed.org/project/help...
Reposted by Fabien Plisson
Applications are open for PhD places on the Engineering Biology CDT programme, beginning Sept 2025.
The programme is run jointly by the Universities of Bristol and Oxford.
Apply to Bristol (by 13 Jan 2025): bristol.ac.uk/study/postgr...
Apply to Oxford (by 8 Jan 2025): ox.ac.uk/admissions/g...
The programme is run jointly by the Universities of Bristol and Oxford.
Apply to Bristol (by 13 Jan 2025): bristol.ac.uk/study/postgr...
Apply to Oxford (by 8 Jan 2025): ox.ac.uk/admissions/g...

November 15, 2024 at 10:37 AM
Applications are open for PhD places on the Engineering Biology CDT programme, beginning Sept 2025.
The programme is run jointly by the Universities of Bristol and Oxford.
Apply to Bristol (by 13 Jan 2025): bristol.ac.uk/study/postgr...
Apply to Oxford (by 8 Jan 2025): ox.ac.uk/admissions/g...
The programme is run jointly by the Universities of Bristol and Oxford.
Apply to Bristol (by 13 Jan 2025): bristol.ac.uk/study/postgr...
Apply to Oxford (by 8 Jan 2025): ox.ac.uk/admissions/g...
Thanks to @sunnalab & @MQ_BDRC for inviting me to the symposium. I was very pleased to present our @CinvestavIra & @IngenieBio work in the #AI-driven peptide discovery & design. It stimulated some interesting questions over bias, representation learning, data scarcity and hype.

December 13, 2024 at 11:08 AM
Thanks to @sunnalab & @MQ_BDRC for inviting me to the symposium. I was very pleased to present our @CinvestavIra & @IngenieBio work in the #AI-driven peptide discovery & design. It stimulated some interesting questions over bias, representation learning, data scarcity and hype.