




Alexandre Ramé
@ramealexandre.bsky.social
Research Scientist at DeepMind. PhD from Sorbonne Université. Merging and aligning Gemmas.
https://alexrame.github.io/
https://alexrame.github.io/
Reposted by Alexandre Ramé

Coming up at ICML: 🤯Distribution shifts are still a huge challenge in ML. There's already a ton of algorithms to address specific conditions. So what if the challenge was just selecting the right algorithm for the right conditions?🤔🧵

July 7, 2025 at 4:51 PM
Coming up at ICML: 🤯Distribution shifts are still a huge challenge in ML. There's already a ton of algorithms to address specific conditions. So what if the challenge was just selecting the right algorithm for the right conditions?🤔🧵
Reposted by Alexandre Ramé

ChatBotArena is far from the first eval to be overfit to. It's becoming underrated. Likely the single most impactful evaluation project since ChatGPT. The labs are the ones releasing these slightly off models.

April 28, 2025 at 3:48 PM
ChatBotArena is far from the first eval to be overfit to. It's becoming underrated. Likely the single most impactful evaluation project since ChatGPT. The labs are the ones releasing these slightly off models.
Reposted by Alexandre Ramé

Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)

NeurIPS participation in Europe
We seek to understand if there is interest in being able to attend NeurIPS in Europe, i.e. without travelling to San Diego, US. In the following, assume that it is possible to present accepted papers ...
docs.google.com
March 30, 2025 at 6:04 PM
Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)
Hiring two student researchers for Gemma post-training team at @GoogleDeepMind Paris! First topic is about diversity in RL for LLMs (merging, generalization, exploration & creativity), second is about distillation. Ideal if you're finishing PhD. DMs open!
March 26, 2025 at 4:24 PM
Hiring two student researchers for Gemma post-training team at @GoogleDeepMind Paris! First topic is about diversity in RL for LLMs (merging, generalization, exploration & creativity), second is about distillation. Ideal if you're finishing PhD. DMs open!
Reposted by Alexandre Ramé

🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
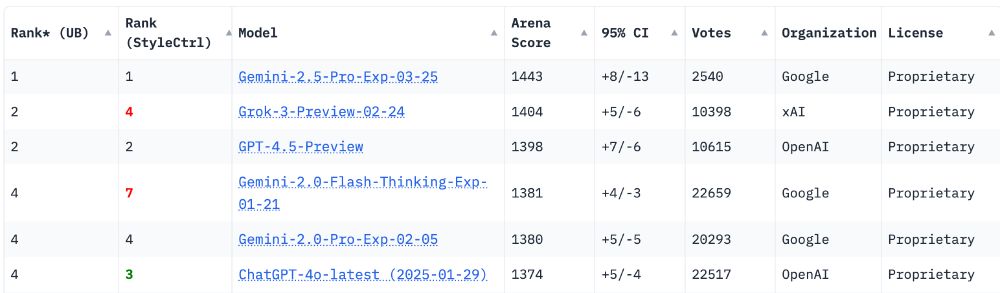

March 25, 2025 at 5:25 PM
🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Reposted by Alexandre Ramé
This is a very tidy little RL paper for reasoning. Their GRPO changes:
1 Two different clip hyperparams, so positive clipping can uplift more unexpected tokens
2 Dynamic sampling -- remove samples w flat reward in batch
3 Per token loss
4 Managing too long generations in loss
dapo-sia.github.io
1 Two different clip hyperparams, so positive clipping can uplift more unexpected tokens
2 Dynamic sampling -- remove samples w flat reward in batch
3 Per token loss
4 Managing too long generations in loss
dapo-sia.github.io

March 17, 2025 at 10:13 PM
This is a very tidy little RL paper for reasoning. Their GRPO changes:
1 Two different clip hyperparams, so positive clipping can uplift more unexpected tokens
2 Dynamic sampling -- remove samples w flat reward in batch
3 Per token loss
4 Managing too long generations in loss
dapo-sia.github.io
1 Two different clip hyperparams, so positive clipping can uplift more unexpected tokens
2 Dynamic sampling -- remove samples w flat reward in batch
3 Per token loss
4 Managing too long generations in loss
dapo-sia.github.io
Welcome Gemma 3, Google’s new open-weight LLM. All sizes (1B, 4B, 12B and 27B) excel on benchmarks, but the key result may be the 27B reaching 1338 on LMSYS. For this, we scaled post-training, with our novel distillation, RL and merging strategies.
Report: storage.googleapis.com/deepmind-med...
Report: storage.googleapis.com/deepmind-med...

March 12, 2025 at 9:03 AM
Welcome Gemma 3, Google’s new open-weight LLM. All sizes (1B, 4B, 12B and 27B) excel on benchmarks, but the key result may be the 27B reaching 1338 on LMSYS. For this, we scaled post-training, with our novel distillation, RL and merging strategies.
Report: storage.googleapis.com/deepmind-med...
Report: storage.googleapis.com/deepmind-med...
Reposted by Alexandre Ramé

My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12
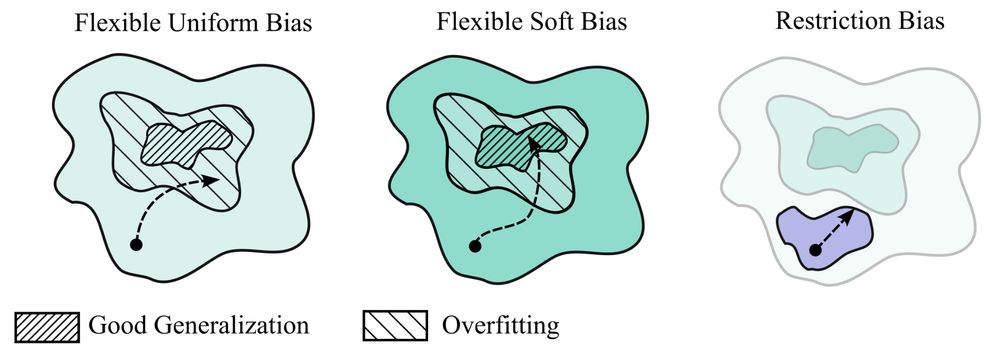
March 5, 2025 at 3:38 PM
My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12
Modern post-training is essentially distillation then RL. While reward hacking is well-known and feared, could there be such a thing as teacher hacking? Our latest paper confirms it. Fortunately, we also show how to mitigate it! The secret: diversity and onlineness! arxiv.org/abs/2502.02671
February 8, 2025 at 6:06 PM
Modern post-training is essentially distillation then RL. While reward hacking is well-known and feared, could there be such a thing as teacher hacking? Our latest paper confirms it. Fortunately, we also show how to mitigate it! The secret: diversity and onlineness! arxiv.org/abs/2502.02671
Reposted by Alexandre Ramé

We just released the Helium-1 model , a 2B multi-lingual LLM which @exgrv.bsky.social and @lmazare.bsky.social have been crafting for us! Best model so far under 2.17B params on multi-lingual benchmarks 🇬🇧🇮🇹🇪🇸🇵🇹🇫🇷🇩🇪
On HF, under CC-BY licence: huggingface.co/kyutai/heliu...
On HF, under CC-BY licence: huggingface.co/kyutai/heliu...

January 13, 2025 at 6:10 PM
We just released the Helium-1 model , a 2B multi-lingual LLM which @exgrv.bsky.social and @lmazare.bsky.social have been crafting for us! Best model so far under 2.17B params on multi-lingual benchmarks 🇬🇧🇮🇹🇪🇸🇵🇹🇫🇷🇩🇪
On HF, under CC-BY licence: huggingface.co/kyutai/heliu...
On HF, under CC-BY licence: huggingface.co/kyutai/heliu...
Reposted by Alexandre Ramé
ILYA: "PRETRAINING IS DONE. WE ARE NOW IN THE POST TRAINING ERA."
December 13, 2024 at 10:49 PM
ILYA: "PRETRAINING IS DONE. WE ARE NOW IN THE POST TRAINING ERA."
Reposted by Alexandre Ramé
Of all of OpenAI's days, the RL API is still the most revealing of the state of AI research trends. Lots of open doors for those looking at RL.
OpenAI's Reinforcement Finetuning and RL for the masses
The cherry on Yann LeCun’s cake has finally been realized.
OpenAI's Reinforcement Finetuning and RL for the masses
The cherry on Yann LeCun’s cake has finally been realized.

OpenAI's Reinforcement Finetuning and RL for the masses
The cherry on Yann LeCun’s cake has finally been realized.
buff.ly
December 11, 2024 at 4:03 PM
Of all of OpenAI's days, the RL API is still the most revealing of the state of AI research trends. Lots of open doors for those looking at RL.
OpenAI's Reinforcement Finetuning and RL for the masses
The cherry on Yann LeCun’s cake has finally been realized.
OpenAI's Reinforcement Finetuning and RL for the masses
The cherry on Yann LeCun’s cake has finally been realized.
Reposted by Alexandre Ramé

🚨So, you want to predict your model's performance at test time?🚨
💡Our NeurIPS 2024 paper proposes 𝐌𝐚𝐍𝐨, a training-free and SOTA approach!
📑 arxiv.org/pdf/2405.18979
🖥️https://github.com/Renchunzi-Xie/MaNo
1/🧵(A surprise at the end!)
💡Our NeurIPS 2024 paper proposes 𝐌𝐚𝐍𝐨, a training-free and SOTA approach!
📑 arxiv.org/pdf/2405.18979
🖥️https://github.com/Renchunzi-Xie/MaNo
1/🧵(A surprise at the end!)

December 3, 2024 at 4:58 PM
🚨So, you want to predict your model's performance at test time?🚨
💡Our NeurIPS 2024 paper proposes 𝐌𝐚𝐍𝐨, a training-free and SOTA approach!
📑 arxiv.org/pdf/2405.18979
🖥️https://github.com/Renchunzi-Xie/MaNo
1/🧵(A surprise at the end!)
💡Our NeurIPS 2024 paper proposes 𝐌𝐚𝐍𝐨, a training-free and SOTA approach!
📑 arxiv.org/pdf/2405.18979
🖥️https://github.com/Renchunzi-Xie/MaNo
1/🧵(A surprise at the end!)
Reposted by Alexandre Ramé

The right place for your phd:
With Colin Raffel, UofT works on decentralizing, democratizing, and derisking large-scale AI. Wanna work on model m(o)erging, collaborative/decentralized learning, identifying & mitigating risks, etc. Apply (deadline is Monday!)
web.cs.toronto.edu/graduate/how...
🤖📈
With Colin Raffel, UofT works on decentralizing, democratizing, and derisking large-scale AI. Wanna work on model m(o)erging, collaborative/decentralized learning, identifying & mitigating risks, etc. Apply (deadline is Monday!)
web.cs.toronto.edu/graduate/how...
🤖📈

How to Apply — Department of Computer Science, University of Toronto
web.cs.toronto.edu
November 30, 2024 at 11:49 AM
The right place for your phd:
With Colin Raffel, UofT works on decentralizing, democratizing, and derisking large-scale AI. Wanna work on model m(o)erging, collaborative/decentralized learning, identifying & mitigating risks, etc. Apply (deadline is Monday!)
web.cs.toronto.edu/graduate/how...
🤖📈
With Colin Raffel, UofT works on decentralizing, democratizing, and derisking large-scale AI. Wanna work on model m(o)erging, collaborative/decentralized learning, identifying & mitigating risks, etc. Apply (deadline is Monday!)
web.cs.toronto.edu/graduate/how...
🤖📈
Reposted by Alexandre Ramé

🥐 Building a Computer Vision FR Starter Pack!
👉 Who else should be included?
Comment below or DM me to be added
go.bsky.app/dfvcLZ
👉 Who else should be included?
Comment below or DM me to be added
go.bsky.app/dfvcLZ
November 29, 2024 at 9:19 AM
🥐 Building a Computer Vision FR Starter Pack!
👉 Who else should be included?
Comment below or DM me to be added
go.bsky.app/dfvcLZ
👉 Who else should be included?
Comment below or DM me to be added
go.bsky.app/dfvcLZ
Reposted by Alexandre Ramé

distributed learning for LLM?
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵

November 25, 2024 at 12:02 PM
distributed learning for LLM?
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
Reposted by Alexandre Ramé

Decomposing Uncertainty for Large Language Models through Input Clarification Ensembling by Bairu Hou et al. #ICML2024
tl;dr: generate multiple clarifications of input txt w/ external LLM then forward:
>disagreement btw outputs -> data uncertainty
>avg uncertainty in each output -> model uncertainty
tl;dr: generate multiple clarifications of input txt w/ external LLM then forward:
>disagreement btw outputs -> data uncertainty
>avg uncertainty in each output -> model uncertainty

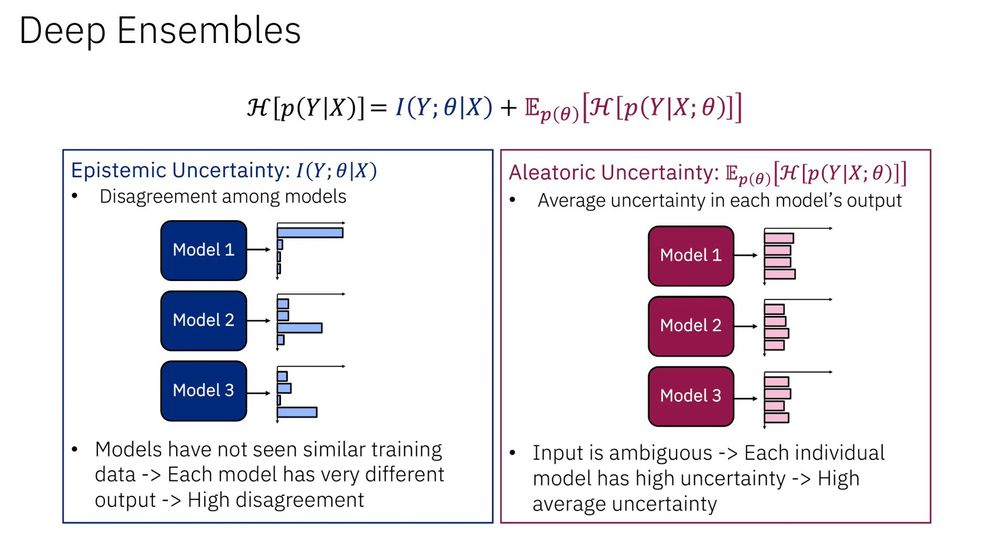


November 24, 2024 at 9:13 PM
Decomposing Uncertainty for Large Language Models through Input Clarification Ensembling by Bairu Hou et al. #ICML2024
tl;dr: generate multiple clarifications of input txt w/ external LLM then forward:
>disagreement btw outputs -> data uncertainty
>avg uncertainty in each output -> model uncertainty
tl;dr: generate multiple clarifications of input txt w/ external LLM then forward:
>disagreement btw outputs -> data uncertainty
>avg uncertainty in each output -> model uncertainty
Reposted by Alexandre Ramé

This year, there are 16 positions at CNRS in computer science (8 in "applied" domains → ask me - 8 on "fundamental" domains → ask the other David).
@mathurinmassias.bsky.social has a good list of advice mathurinm.github.io/cnrs_inria_a...
Official 🔗 www.ins2i.cnrs.fr/en/cnrsinfo/...
Don't wait!
@mathurinmassias.bsky.social has a good list of advice mathurinm.github.io/cnrs_inria_a...
Official 🔗 www.ins2i.cnrs.fr/en/cnrsinfo/...
Don't wait!
November 23, 2024 at 7:33 PM
This year, there are 16 positions at CNRS in computer science (8 in "applied" domains → ask me - 8 on "fundamental" domains → ask the other David).
@mathurinmassias.bsky.social has a good list of advice mathurinm.github.io/cnrs_inria_a...
Official 🔗 www.ins2i.cnrs.fr/en/cnrsinfo/...
Don't wait!
@mathurinmassias.bsky.social has a good list of advice mathurinm.github.io/cnrs_inria_a...
Official 🔗 www.ins2i.cnrs.fr/en/cnrsinfo/...
Don't wait!
Reposted by Alexandre Ramé
Feeling that Paris is "The Place To Be" for computer vision and AI in general.
November 21, 2024 at 9:28 AM
Feeling that Paris is "The Place To Be" for computer vision and AI in general.
Reposted by Alexandre Ramé
Min-p Sampling: arxiv.org/abs/2407.01082
1. Get max prob
2. Find min prob based on a threshold \in [0, 1] \times that max prob
3. Gather only tokens probs above that min prob
4. Sample in that pool, according to renormalized probs
More robust to change in temperature!
1. Get max prob
2. Find min prob based on a threshold \in [0, 1] \times that max prob
3. Gather only tokens probs above that min prob
4. Sample in that pool, according to renormalized probs
More robust to change in temperature!

Turning Up the Heat: Min-p Sampling for Creative and Coherent LLM Outputs
Large Language Models (LLMs) generate text by sampling the next token from a probability distribution over the vocabulary at each decoding step. However, popular sampling methods like top-p (nucleus…
arxiv.org
November 21, 2024 at 11:06 AM
Min-p Sampling: arxiv.org/abs/2407.01082
1. Get max prob
2. Find min prob based on a threshold \in [0, 1] \times that max prob
3. Gather only tokens probs above that min prob
4. Sample in that pool, according to renormalized probs
More robust to change in temperature!
1. Get max prob
2. Find min prob based on a threshold \in [0, 1] \times that max prob
3. Gather only tokens probs above that min prob
4. Sample in that pool, according to renormalized probs
More robust to change in temperature!
Reposted by Alexandre Ramé

November 19, 2024 at 11:00 PM
Reposted by Alexandre Ramé

Bluesky now has over 20M people!! 🎉
We've been adding over a million users per day for the last few days. To celebrate, here are 20 fun facts about Bluesky:
We've been adding over a million users per day for the last few days. To celebrate, here are 20 fun facts about Bluesky:
November 19, 2024 at 6:51 PM
Bluesky now has over 20M people!! 🎉
We've been adding over a million users per day for the last few days. To celebrate, here are 20 fun facts about Bluesky:
We've been adding over a million users per day for the last few days. To celebrate, here are 20 fun facts about Bluesky:
Reposted by Alexandre Ramé

New people in AI have joined recently, I can't cite all, but here are some: @fguney.bsky.social @natalianeverova.bsky.social @damienteney.bsky.social @jdigne.bsky.social @nbonneel.bsky.social @steevenj7.bsky.social @douillard.bsky.social @ramealexandre.bsky.social @stonet2000.bsky.social
1/
1/
November 17, 2024 at 10:22 PM
New people in AI have joined recently, I can't cite all, but here are some: @fguney.bsky.social @natalianeverova.bsky.social @damienteney.bsky.social @jdigne.bsky.social @nbonneel.bsky.social @steevenj7.bsky.social @douillard.bsky.social @ramealexandre.bsky.social @stonet2000.bsky.social
1/
1/