



TimDarcet
@timdarcet.bsky.social
PhD student, SSL for vision @ MetaAI & INRIA
tim.darcet.fr
tim.darcet.fr
Pinned
TimDarcet
@timdarcet.bsky.social
· Oct 1

Vision transformers need registers!
Or at least, it seems they 𝘸𝘢𝘯𝘵 some…
ViTs have artifacts in attention maps. It’s due to the model using these patches as “registers”.
Just add new tokens (“[reg]”):
- no artifacts
- interpretable attention maps 🦖
- improved performances!
arxiv.org/abs/2309.16588
Or at least, it seems they 𝘸𝘢𝘯𝘵 some…
ViTs have artifacts in attention maps. It’s due to the model using these patches as “registers”.
Just add new tokens (“[reg]”):
- no artifacts
- interpretable attention maps 🦖
- improved performances!
arxiv.org/abs/2309.16588
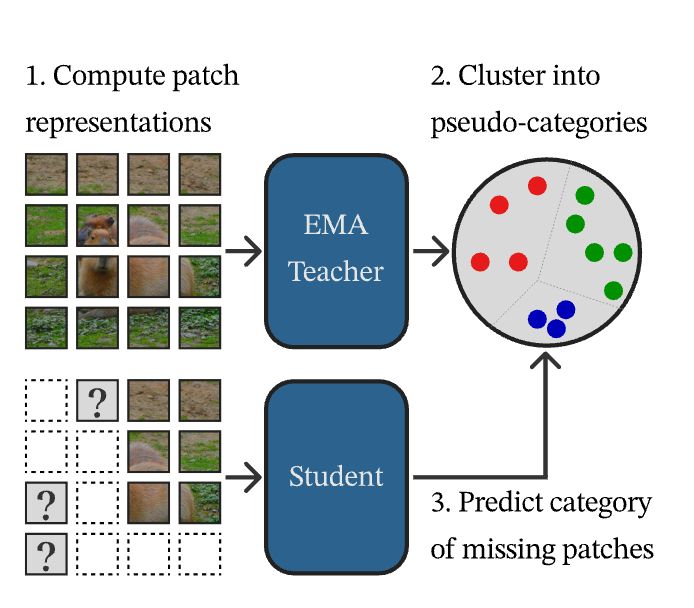
Want strong SSL, but not the complexity of DINOv2?
CAPI: Cluster and Predict Latents Patches for Improved Masked Image Modeling.
CAPI: Cluster and Predict Latents Patches for Improved Masked Image Modeling.
February 14, 2025 at 6:05 PM
Want strong SSL, but not the complexity of DINOv2?
CAPI: Cluster and Predict Latents Patches for Improved Masked Image Modeling.
CAPI: Cluster and Predict Latents Patches for Improved Masked Image Modeling.
Reposted by TimDarcet

(3/3) LUDVIG uses a graph diffusion mechanism to refine 3D features, such as coarse segmentation masks, by leveraging 3D scene geometry and pairwise similarities induced by DINOv2.
January 31, 2025 at 9:59 AM
(3/3) LUDVIG uses a graph diffusion mechanism to refine 3D features, such as coarse segmentation masks, by leveraging 3D scene geometry and pairwise similarities induced by DINOv2.
Reposted by TimDarcet
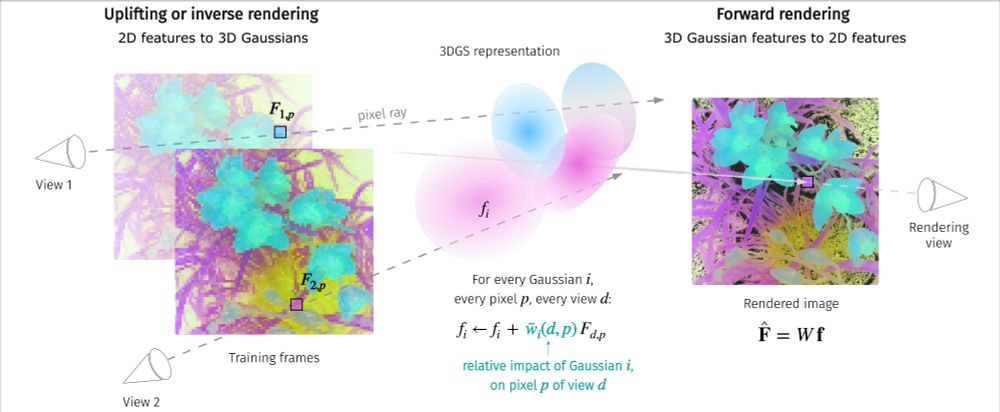
(2/3) We propose a simple, parameter-free aggregation mechanism, based on alpha-weighted multi-view blending of 2D pixel features in the forward rendering process.
January 31, 2025 at 9:59 AM
(2/3) We propose a simple, parameter-free aggregation mechanism, based on alpha-weighted multi-view blending of 2D pixel features in the forward rendering process.
Reposted by TimDarcet
(1/3) Happy to share LUDVIG: Learning-free Uplifting of 2D Visual features to Gaussian Splatting scenes, that uplifts visual features from models such as DINOv2 (left) & CLIP (mid) to 3DGS scenes. Joint work w. @dlarlus.bsky.social @jmairal.bsky.social
Webpage & code: juliettemarrie.github.io/ludvig
Webpage & code: juliettemarrie.github.io/ludvig
January 31, 2025 at 9:59 AM
(1/3) Happy to share LUDVIG: Learning-free Uplifting of 2D Visual features to Gaussian Splatting scenes, that uplifts visual features from models such as DINOv2 (left) & CLIP (mid) to 3DGS scenes. Joint work w. @dlarlus.bsky.social @jmairal.bsky.social
Webpage & code: juliettemarrie.github.io/ludvig
Webpage & code: juliettemarrie.github.io/ludvig
Reposted by TimDarcet

Outstanding Finalist 2: “DINOv2: Learning Robust Visual Features without Supervision," by Maxime Oquab, Timothée Darcet, Théo Moutakanni et al. 5/n openreview.net/forum?id=a68...

DINOv2: Learning Robust Visual Features without Supervision
The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could...
openreview.net
January 8, 2025 at 5:41 PM
Outstanding Finalist 2: “DINOv2: Learning Robust Visual Features without Supervision," by Maxime Oquab, Timothée Darcet, Théo Moutakanni et al. 5/n openreview.net/forum?id=a68...
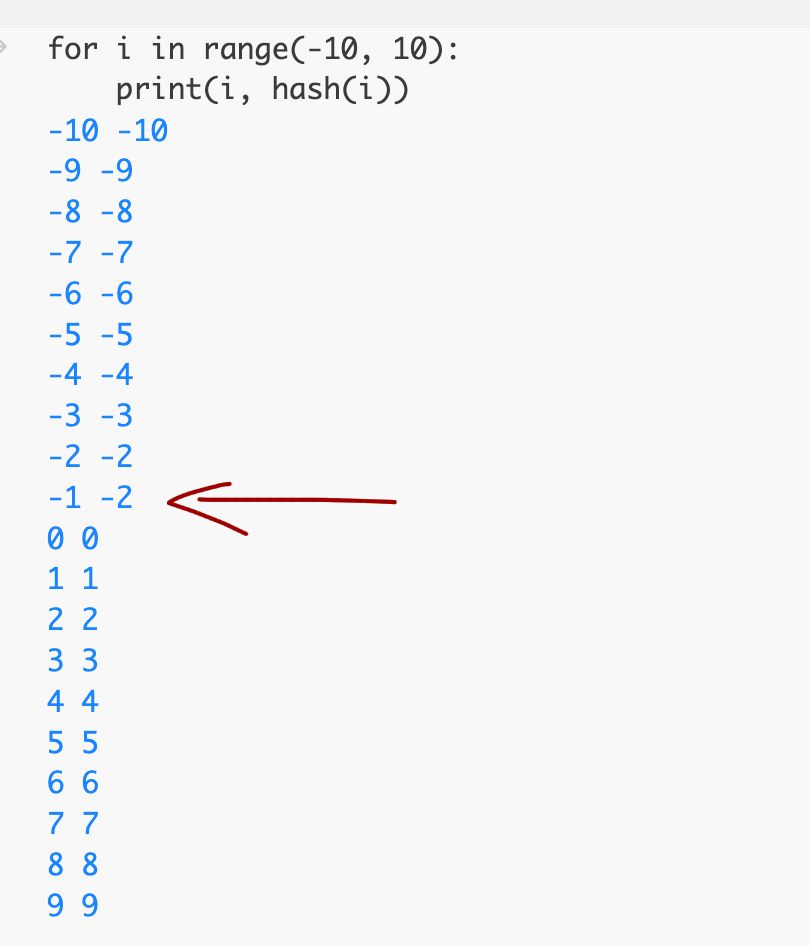
Hash functions are really useful to uniquely encode stuff without collision huh
January 7, 2025 at 2:15 PM
Hash functions are really useful to uniquely encode stuff without collision huh
At least there's diversity of opinions

December 27, 2024 at 6:56 PM
At least there's diversity of opinions
Reposted by TimDarcet

"no one can match my artistic vision" i mutter to myself repeatedly as i leave critical analyses undone and focus on what shade of gray to use in a supplemental figure
December 23, 2024 at 4:15 PM
"no one can match my artistic vision" i mutter to myself repeatedly as i leave critical analyses undone and focus on what shade of gray to use in a supplemental figure
Reposted by TimDarcet

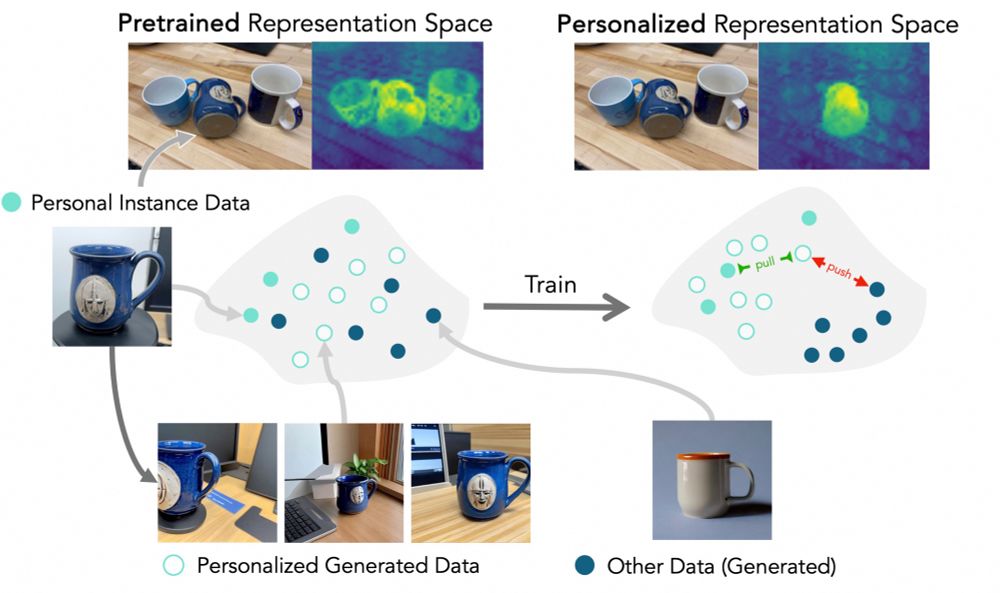
Personal vision tasks–like detecting *your mug*--are hard; they’re data scarce and fine-grained.
In our new paper, we show you can adapt general-purpose vision models to these tasks from just three photos!
📝: arxiv.org/abs/2412.16156
💻: github.com/ssundaram21/...
(1/n)
In our new paper, we show you can adapt general-purpose vision models to these tasks from just three photos!
📝: arxiv.org/abs/2412.16156
💻: github.com/ssundaram21/...
(1/n)
December 23, 2024 at 5:26 PM
Personal vision tasks–like detecting *your mug*--are hard; they’re data scarce and fine-grained.
In our new paper, we show you can adapt general-purpose vision models to these tasks from just three photos!
📝: arxiv.org/abs/2412.16156
💻: github.com/ssundaram21/...
(1/n)
In our new paper, we show you can adapt general-purpose vision models to these tasks from just three photos!
📝: arxiv.org/abs/2412.16156
💻: github.com/ssundaram21/...
(1/n)
Reposted by TimDarcet

Can video MAE scale? Yes.
Do you need language to scale video models? No.
arxiv.org/abs/2412.15212
Great rigorous benchmarking from my colleagues at Google DeepMind.
Do you need language to scale video models? No.
arxiv.org/abs/2412.15212
Great rigorous benchmarking from my colleagues at Google DeepMind.

Scaling 4D Representations
Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classifi...
arxiv.org
December 20, 2024 at 10:36 PM
Can video MAE scale? Yes.
Do you need language to scale video models? No.
arxiv.org/abs/2412.15212
Great rigorous benchmarking from my colleagues at Google DeepMind.
Do you need language to scale video models? No.
arxiv.org/abs/2412.15212
Great rigorous benchmarking from my colleagues at Google DeepMind.
Reposted by TimDarcet

Everything is a LAW when you have 4 points on a log-log plot 🤔

Yup sure, the curve has to kick in at some point. I guess “law” sounds cooler than linear-ish graph. Maybe it started out as an acronym “Linear for A While”.. 🤷♂️
December 15, 2024 at 2:39 PM
Everything is a LAW when you have 4 points on a log-log plot 🤔
Reposted by TimDarcet

Brilliant talk by Ilya, but he's wrong on one point.
We are NOT running out of data. We are running out of human-written text.
We have more videos than we know what to do with. We just haven't solved pre-training in vision.
Just go out and sense the world. Data is easy.

December 14, 2024 at 7:15 PM
Brilliant talk by Ilya, but he's wrong on one point.
We are NOT running out of data. We are running out of human-written text.
We have more videos than we know what to do with. We just haven't solved pre-training in vision.
Just go out and sense the world. Data is easy.
Reposted by TimDarcet

🌍 Guessing where an image was taken is a hard, and often ambiguous problem. Introducing diffusion-based geolocation—we predict global locations by refining random guesses into trajectories across the Earth's surface!
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
December 10, 2024 at 3:56 PM
🌍 Guessing where an image was taken is a hard, and often ambiguous problem. Introducing diffusion-based geolocation—we predict global locations by refining random guesses into trajectories across the Earth's surface!
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
Reposted by TimDarcet

Web 1.0 is back, baby
December 8, 2024 at 12:33 PM
Web 1.0 is back, baby
Wake up babe new iNat just dropped
Along with INQUIRE, we introduce iNat24, a new dataset of 5 million research-grade images from @inaturalist with 10,000 species labels.
This is one of the largest publicly available natural world image repositories!
This is one of the largest publicly available natural world image repositories!

December 7, 2024 at 12:53 PM
Wake up babe new iNat just dropped
Reposted by TimDarcet

Along with INQUIRE, we introduce iNat24, a new dataset of 5 million research-grade images from @inaturalist with 10,000 species labels.
This is one of the largest publicly available natural world image repositories!
This is one of the largest publicly available natural world image repositories!
December 6, 2024 at 8:28 PM
Along with INQUIRE, we introduce iNat24, a new dataset of 5 million research-grade images from @inaturalist with 10,000 species labels.
This is one of the largest publicly available natural world image repositories!
This is one of the largest publicly available natural world image repositories!
The hardest thing in the world is to refrain from using superlatives
December 6, 2024 at 9:22 AM
The hardest thing in the world is to refrain from using superlatives
Reposted by TimDarcet

I'd be fine calling this the "Milan Principle" and I'd extend it to "Most commercialized goods do not need new features."

Here's my incredibly popular opinion that will never get any traction:
Most software does not need new features. None. Zero. Zilch.
Most software does not need new features. None. Zero. Zilch.
November 30, 2024 at 8:38 AM
I'd be fine calling this the "Milan Principle" and I'd extend it to "Most commercialized goods do not need new features."
Reposted by TimDarcet

A fun thesis experiment: ResNet, DETR, and CLIP tackle Saint-Bernards. 🐶
ResNet focused on **fur** patterns, DETR too but also use **paws** (possibly because it helps define bounding boxes), and CLIP **head** concept oddly included human heads — language shaping learned concepts?
ResNet focused on **fur** patterns, DETR too but also use **paws** (possibly because it helps define bounding boxes), and CLIP **head** concept oddly included human heads — language shaping learned concepts?

November 27, 2024 at 6:51 PM
A fun thesis experiment: ResNet, DETR, and CLIP tackle Saint-Bernards. 🐶
ResNet focused on **fur** patterns, DETR too but also use **paws** (possibly because it helps define bounding boxes), and CLIP **head** concept oddly included human heads — language shaping learned concepts?
ResNet focused on **fur** patterns, DETR too but also use **paws** (possibly because it helps define bounding boxes), and CLIP **head** concept oddly included human heads — language shaping learned concepts?
Excellent writeup on GPU streams / CUDA memory
dev-discuss.pytorch.org/t/fsdp-cudac...
TLDR by default mem is proper to a stream, to share it::
- `Tensor.record_stream` -> automatic, but can be suboptimal and nondeterministic
- `Stream.wait` -> manual, but precise control
dev-discuss.pytorch.org/t/fsdp-cudac...
TLDR by default mem is proper to a stream, to share it::
- `Tensor.record_stream` -> automatic, but can be suboptimal and nondeterministic
- `Stream.wait` -> manual, but precise control

November 24, 2024 at 10:04 PM
Excellent writeup on GPU streams / CUDA memory
dev-discuss.pytorch.org/t/fsdp-cudac...
TLDR by default mem is proper to a stream, to share it::
- `Tensor.record_stream` -> automatic, but can be suboptimal and nondeterministic
- `Stream.wait` -> manual, but precise control
dev-discuss.pytorch.org/t/fsdp-cudac...
TLDR by default mem is proper to a stream, to share it::
- `Tensor.record_stream` -> automatic, but can be suboptimal and nondeterministic
- `Stream.wait` -> manual, but precise control
Reposted by TimDarcet

I've been using Skybridge (chromewebstore.google.com/detail/sky-f...) to rebuild the graph periodically which I think helps

Sky Follower Bridge - Chrome Web Store
Instantly find and follow the same users from your Twitter follows on Bluesky.
chromewebstore.google.com
November 24, 2024 at 5:40 AM
I've been using Skybridge (chromewebstore.google.com/detail/sky-f...) to rebuild the graph periodically which I think helps
Reposted by TimDarcet

please, remember our core values:
don't forget that we are all stupid on here
November 24, 2024 at 3:57 AM
please, remember our core values:
Reposted by TimDarcet

These opportunities are mostly reserved for the rest of the world. We need similar Industry-Academia PhD programs in the US too! We need an american version of the CIFRE.

Hello BlueSky! Joao Henriques (joao.science) and I are hiring a fully funded PhD student (UK/international) for the FAIR-Oxford program. The student will spend 50% of their time @UniofOxford and 50% @MetaAI (FAIR) in London, while completing a DPhil (Oxford PhD). Deadline: 2nd of Dec AOE!!
João F. Henriques
Research of Joao F. Henriques
joao.science
November 23, 2024 at 3:21 PM
These opportunities are mostly reserved for the rest of the world. We need similar Industry-Academia PhD programs in the US too! We need an american version of the CIFRE.
Reposted by TimDarcet

༼ つ ◕_◕ ༽つ GIVE DINOv3
November 22, 2024 at 11:48 AM
༼ つ ◕_◕ ༽つ GIVE DINOv3
Reposted by TimDarcet

𝗗𝗼𝗲𝘀 𝗮𝘂𝘁𝗼𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗽𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝘃𝗶𝘀𝗶𝗼𝗻? 🤔
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...

November 22, 2024 at 8:32 AM
𝗗𝗼𝗲𝘀 𝗮𝘂𝘁𝗼𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗽𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝘃𝗶𝘀𝗶𝗼𝗻? 🤔
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...