
Chau Minh Pham
@chautmpham.bsky.social
2.1K followers
560 following
33 posts
PhD student @umdcs | Long-form Narrative Generation & Analysis | Intern @AdobeResearch @MSFTResearch | https://chtmp223.github.io
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Chau Minh Pham
Reposted by Chau Minh Pham


Reposted by Chau Minh Pham

Maria Antoniak
@mariaa.bsky.social
· Jul 23
Reposted by Chau Minh Pham

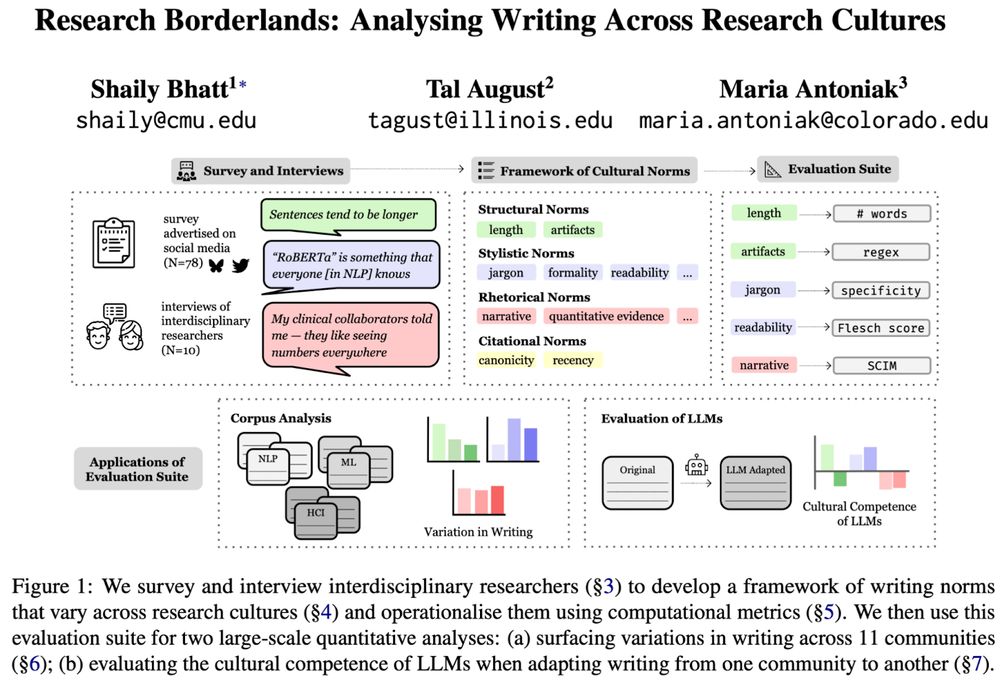






Chau Minh Pham
@chautmpham.bsky.social
· May 30


Reposted by Chau Minh Pham






Reposted by Chau Minh Pham

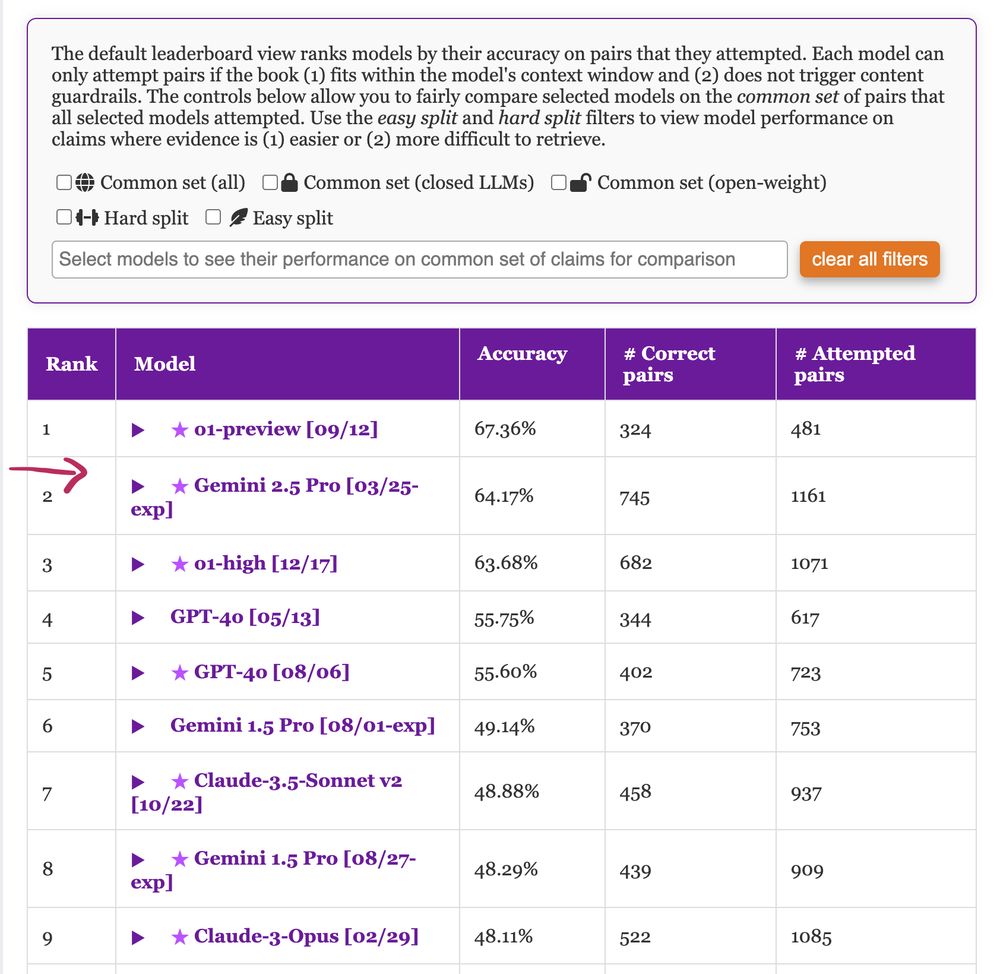
Reposted by Chau Minh Pham

Reposted by Chau Minh Pham

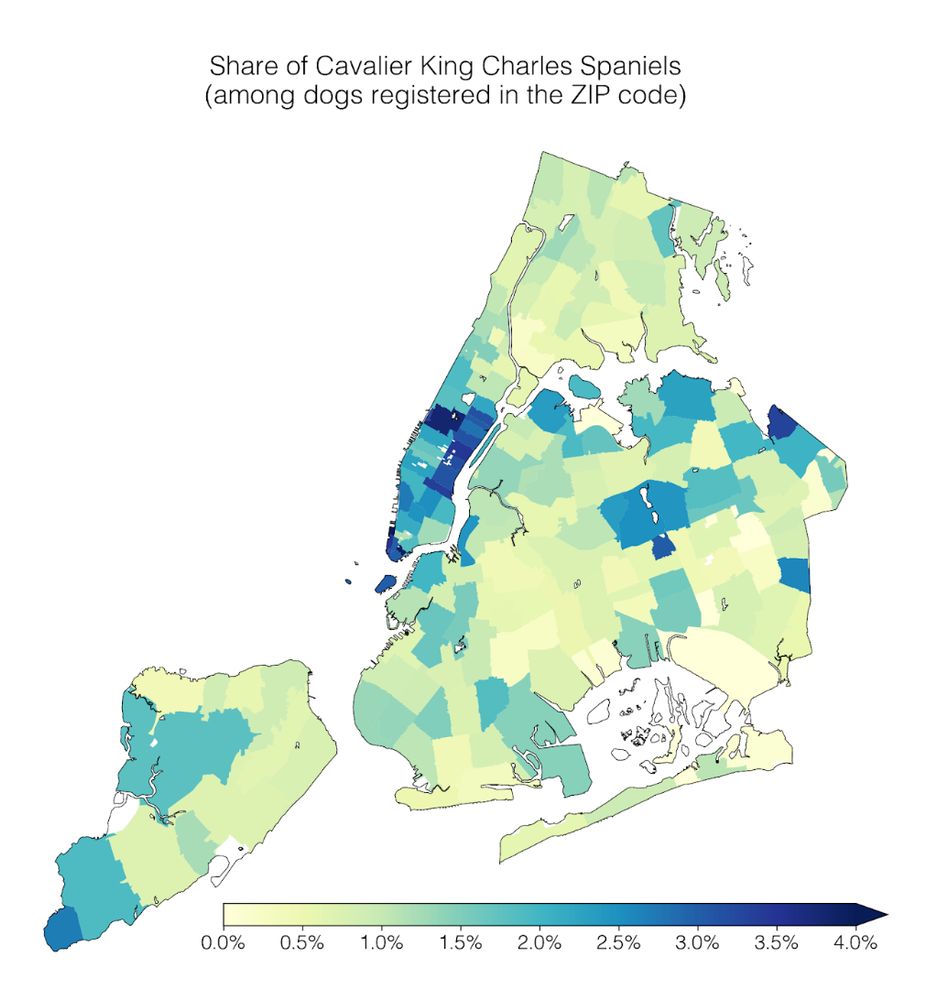
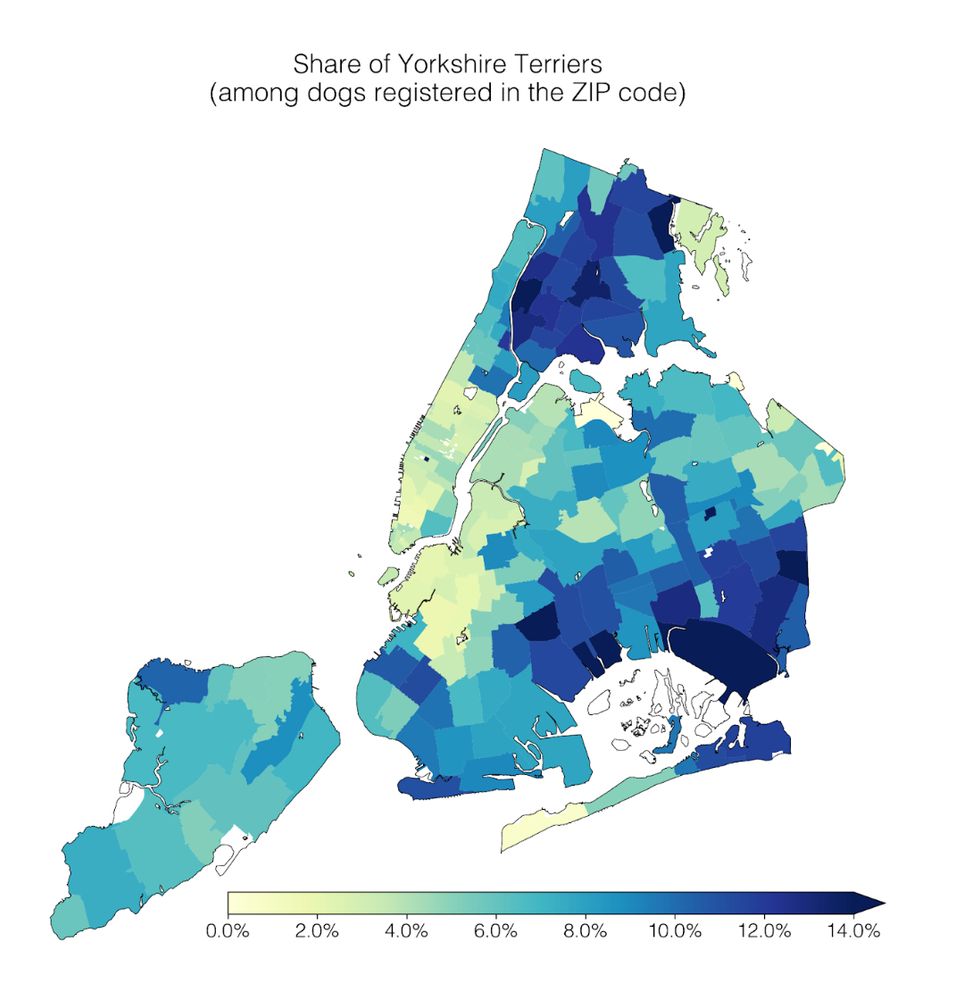
Reposted by Chau Minh Pham

Reposted by Chau Minh Pham



Reposted by Chau Minh Pham


Reposted by Chau Minh Pham


Reposted by Chau Minh Pham


Chau Minh Pham
@chautmpham.bsky.social
· Feb 25

To Trust or to Think: Cognitive Forcing Functions Can Reduce Overreliance on AI in AI-assisted Decision-making
People supported by AI-powered decision support tools frequently overrely on the AI: they accept an AI's suggestion even when that suggestion is wrong. Adding explanations to the AI decisions does not...
arxiv.org