




Chau Minh Pham
@chautmpham.bsky.social
PhD student @umdcs | Long-form Narrative Generation & Analysis | Intern @AdobeResearch @MSFTResearch | https://chtmp223.github.io
Pinned

🤔 What if you gave an LLM thousands of random human-written paragraphs and told it to write something new -- while copying 90% of its output from those texts?
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
Reposted by Chau Minh Pham

Short Little Difficult Books | Discussion

Short Little Difficult Books
Novels that challenge with style, story, or form that you can read in a day.
countercraft.substack.com
November 18, 2025 at 3:20 PM
Short Little Difficult Books | Discussion
Reposted by Chau Minh Pham

Why AI writing is mid
How the current way of training language models destroys any voice (and hope of good writing).
www.interconnects.ai/p/why-ai-wri...
How the current way of training language models destroys any voice (and hope of good writing).
www.interconnects.ai/p/why-ai-wri...

Why AI writing is mid
How the current way of training language models destroys any voice (and hope of good writing).
www.interconnects.ai
November 17, 2025 at 3:41 PM
Why AI writing is mid
How the current way of training language models destroys any voice (and hope of good writing).
www.interconnects.ai/p/why-ai-wri...
How the current way of training language models destroys any voice (and hope of good writing).
www.interconnects.ai/p/why-ai-wri...
Reposted by Chau Minh Pham

I curated some readings for class on "data tensions" and the list felt worth sharing. Come on a tour of datasets, books, the web, and AI with me...
We'll start with this piece on the Google Books project: the hopes, dreams, disasters, and aftermath of building a public library on the internet.
1/n
We'll start with this piece on the Google Books project: the hopes, dreams, disasters, and aftermath of building a public library on the internet.
1/n

Torching the Modern-Day Library of Alexandria
“Somewhere at Google there is a database containing 25 million books and nobody is allowed to read them.”
www.theatlantic.com
November 14, 2025 at 4:39 PM
I curated some readings for class on "data tensions" and the list felt worth sharing. Come on a tour of datasets, books, the web, and AI with me...
We'll start with this piece on the Google Books project: the hopes, dreams, disasters, and aftermath of building a public library on the internet.
1/n
We'll start with this piece on the Google Books project: the hopes, dreams, disasters, and aftermath of building a public library on the internet.
1/n
Reposted by Chau Minh Pham

Excited to share our new paper, "DataRater: Meta-Learned Dataset Curation"!
We explore a fundamental question: How can we *automatically* learn which data is most valuable for training foundation models?
Paper: arxiv.org/pdf/2505.17895 to appear at @neuripsconf.bsky.social
Thread 👇
We explore a fundamental question: How can we *automatically* learn which data is most valuable for training foundation models?
Paper: arxiv.org/pdf/2505.17895 to appear at @neuripsconf.bsky.social
Thread 👇
November 6, 2025 at 11:29 AM
Excited to share our new paper, "DataRater: Meta-Learned Dataset Curation"!
We explore a fundamental question: How can we *automatically* learn which data is most valuable for training foundation models?
Paper: arxiv.org/pdf/2505.17895 to appear at @neuripsconf.bsky.social
Thread 👇
We explore a fundamental question: How can we *automatically* learn which data is most valuable for training foundation models?
Paper: arxiv.org/pdf/2505.17895 to appear at @neuripsconf.bsky.social
Thread 👇
Reposted by Chau Minh Pham

As DH grows, it’s increasingly important to publish conference papers, but there hasn’t been a clear venue for that.
So I’m thrilled to share this new home for DH proceedings, which will include CHR papers & more.
Thanks to @taylor-arnold.bsky.social for leading this effort!
bit.ly/ach-anthology
So I’m thrilled to share this new home for DH proceedings, which will include CHR papers & more.
Thanks to @taylor-arnold.bsky.social for leading this effort!
bit.ly/ach-anthology

October 29, 2025 at 3:39 PM
As DH grows, it’s increasingly important to publish conference papers, but there hasn’t been a clear venue for that.
So I’m thrilled to share this new home for DH proceedings, which will include CHR papers & more.
Thanks to @taylor-arnold.bsky.social for leading this effort!
bit.ly/ach-anthology
So I’m thrilled to share this new home for DH proceedings, which will include CHR papers & more.
Thanks to @taylor-arnold.bsky.social for leading this effort!
bit.ly/ach-anthology
Reposted by Chau Minh Pham

LLMs are often used for text annotation, especially in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828

October 27, 2025 at 2:59 PM
LLMs are often used for text annotation, especially in social science. In some cases, this involves placing text items on a scale: eg, 1 for liberal and 9 for conservative
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828
There are a few ways to accomplish this task. Which work best? Our new EMNLP paper has some answers🧵
arxiv.org/pdf/2507.00828
Reposted by Chau Minh Pham

AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:

October 22, 2025 at 3:24 PM
AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
Reposted by Chau Minh Pham

"AI slop" seems to be everywhere, but what exactly makes text feel like "slop"?
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)


September 24, 2025 at 1:21 PM
"AI slop" seems to be everywhere, but what exactly makes text feel like "slop"?
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)
In our new work (w/ @tuhinchakr.bsky.social, Diego Garcia-Olano, @byron.bsky.social ) we provide a systematic attempt at measuring AI "slop" in text!
arxiv.org/abs/2509.19163
🧵 (1/7)
Reposted by Chau Minh Pham
Keynote at #COLM2025: Nicholas Carlini from Anthropic
"Are language models worth it?"
Explains that the prior decade of his work on adversarial images, while it taught us a lot, isn't very applied; it's unlikely anyone is actually altering images of cats in scary ways.
"Are language models worth it?"
Explains that the prior decade of his work on adversarial images, while it taught us a lot, isn't very applied; it's unlikely anyone is actually altering images of cats in scary ways.
October 9, 2025 at 1:12 PM
Keynote at #COLM2025: Nicholas Carlini from Anthropic
"Are language models worth it?"
Explains that the prior decade of his work on adversarial images, while it taught us a lot, isn't very applied; it's unlikely anyone is actually altering images of cats in scary ways.
"Are language models worth it?"
Explains that the prior decade of his work on adversarial images, while it taught us a lot, isn't very applied; it's unlikely anyone is actually altering images of cats in scary ways.
Reposted by Chau Minh Pham

📢 New #COLM2025 paper 📢
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵

September 16, 2025 at 5:16 PM
📢 New #COLM2025 paper 📢
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵
Reposted by Chau Minh Pham
What are your favorite recent papers on using LMs for annotation (especially in a loop with human annotators), synthetic data for task-specific prediction, active learning, and similar?
Looking for practical methods for settings where human annotations are costly.
A few examples in thread ↴
Looking for practical methods for settings where human annotations are costly.
A few examples in thread ↴
July 23, 2025 at 8:10 AM
What are your favorite recent papers on using LMs for annotation (especially in a loop with human annotators), synthetic data for task-specific prediction, active learning, and similar?
Looking for practical methods for settings where human annotations are costly.
A few examples in thread ↴
Looking for practical methods for settings where human annotations are costly.
A few examples in thread ↴
Reposted by Chau Minh Pham
I see this work as our answer to the "cultural alignment" and "cultural benchmarking" trends in NLP research. Instead of making decisions for people, we consider "culture" in a specific setting with specific people for a specific task, and we ask people directly about their cultural adaptations.

🖋️ Curious how writing differs across (research) cultures?
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
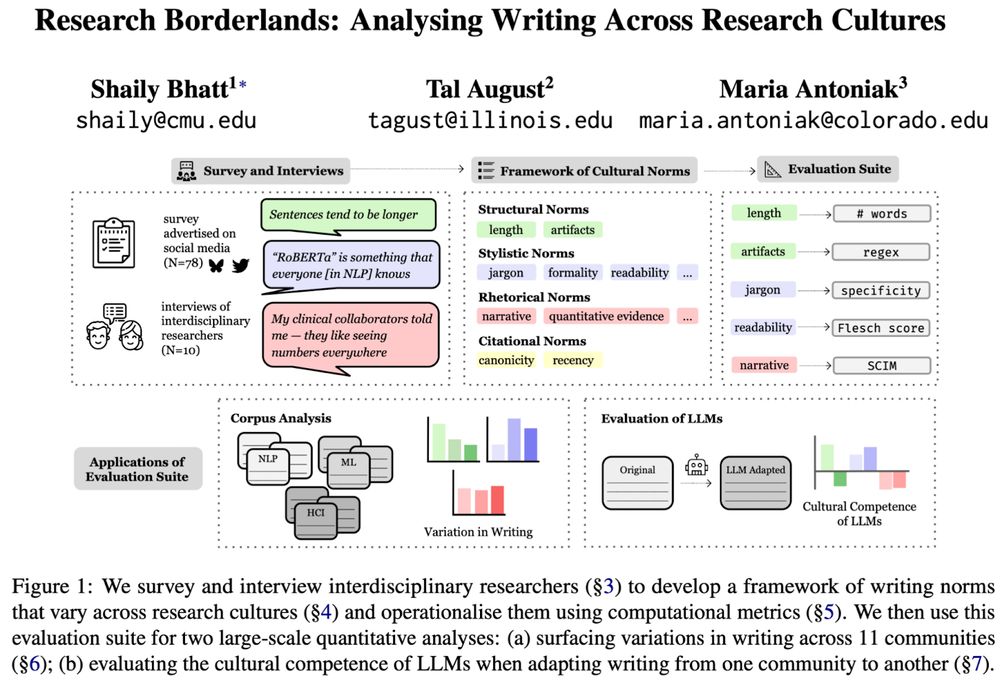
June 10, 2025 at 7:48 AM
I see this work as our answer to the "cultural alignment" and "cultural benchmarking" trends in NLP research. Instead of making decisions for people, we consider "culture" in a specific setting with specific people for a specific task, and we ask people directly about their cultural adaptations.
🤔 What if you gave an LLM thousands of random human-written paragraphs and told it to write something new -- while copying 90% of its output from those texts?
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
June 3, 2025 at 3:09 PM
🤔 What if you gave an LLM thousands of random human-written paragraphs and told it to write something new -- while copying 90% of its output from those texts?
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
We find that LLMs (e.g. GPT-4o, LLaMA-3.1) consistently recall book content across languages, even for texts without official translation in pre-training data!
Great work led by undergrads at UMass NLP 🥳
Great work led by undergrads at UMass NLP 🥳

LLMs memorize novels 📚 in English. But what about existing translations? Or translations into new languages?
Our 🦉OWL dataset (31K/10 languages) shows GPT4o recognizes books:
92% English
83% official translations
69% unseen translations
75% as audio (EN)
Our 🦉OWL dataset (31K/10 languages) shows GPT4o recognizes books:
92% English
83% official translations
69% unseen translations
75% as audio (EN)

May 30, 2025 at 3:53 PM
We find that LLMs (e.g. GPT-4o, LLaMA-3.1) consistently recall book content across languages, even for texts without official translation in pre-training data!
Great work led by undergrads at UMass NLP 🥳
Great work led by undergrads at UMass NLP 🥳
Reposted by Chau Minh Pham

One of the ways that LLMs can be inconsistent is the "generator-validator gap," where LLMs deem their own answers incorrect.
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇


April 16, 2025 at 6:03 PM
One of the ways that LLMs can be inconsistent is the "generator-validator gap," where LLMs deem their own answers incorrect.
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
Reposted by Chau Minh Pham

📚 Check out the newest JCA article by Li Lucy (@lucy3.bsky.social), Camilla Griffiths, Claire Ying, JJ Kim-Ebio, Sabrina Baur, Sarah Levine, Jennifer L. Eberhardt, David Bamman (@dbamman.bsky.social), and Dorottya Demszky. culturalanalytics.org/article/1316...
Racial and Ethnic Representation in Literature Taught in US High Schools | Published in Journal of Cultural Analytics
By Li Lucy, Camilla Griffiths & 7 more. We quantify the representation, or presence, of characters of color in English Language Arts instruction in the United States to better understand possible raci...
culturalanalytics.org
April 9, 2025 at 1:06 PM
📚 Check out the newest JCA article by Li Lucy (@lucy3.bsky.social), Camilla Griffiths, Claire Ying, JJ Kim-Ebio, Sabrina Baur, Sarah Levine, Jennifer L. Eberhardt, David Bamman (@dbamman.bsky.social), and Dorottya Demszky. culturalanalytics.org/article/1316...
Reposted by Chau Minh Pham
A very cool paper shows that you can use the RL loss to improve story generation by some clever setups on training on known texts (e.g. ground predictions versus a next chapter you know). RL starting to generalize already!

Learning to Reason for Long-Form Story Generation
Generating high-quality stories spanning thousands of tokens requires competency across a variety of skills, from tracking plot and character arcs to keeping a consistent and engaging style. Due to…
buff.ly
April 8, 2025 at 2:13 PM
A very cool paper shows that you can use the RL loss to improve story generation by some clever setups on training on known texts (e.g. ground predictions versus a next chapter you know). RL starting to generalize already!
Reposted by Chau Minh Pham

We have updated #nocha, a leaderboard for reasoning over long-context narratives 📖, with some new models including #Gemini 2.5 Pro which shows massive improvements over the previous version! Congrats to #Gemini team 🪄 🧙 Check 🔗 novelchallenge.github.io for details :)
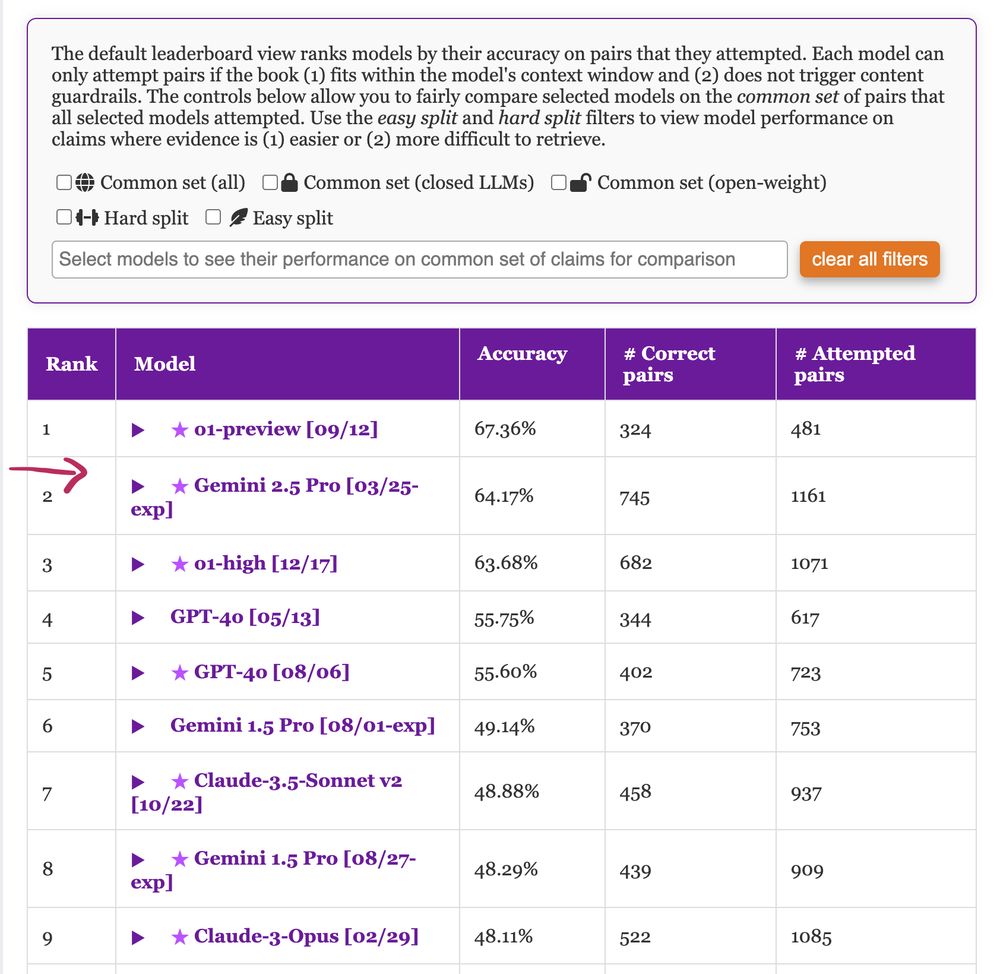
April 2, 2025 at 4:30 AM
We have updated #nocha, a leaderboard for reasoning over long-context narratives 📖, with some new models including #Gemini 2.5 Pro which shows massive improvements over the previous version! Congrats to #Gemini team 🪄 🧙 Check 🔗 novelchallenge.github.io for details :)
Reposted by Chau Minh Pham

New paper from our team @GoogleDeepMind!
🚨 We've put LLMs to the test as writing co-pilots – how good are they really at helping us write? LLMs are increasingly used for open-ended tasks like writing assistance, but how do we assess their effectiveness? 🤔
arxiv.org/pdf/2503.19711
🚨 We've put LLMs to the test as writing co-pilots – how good are they really at helping us write? LLMs are increasingly used for open-ended tasks like writing assistance, but how do we assess their effectiveness? 🤔
arxiv.org/pdf/2503.19711
arxiv.org
April 2, 2025 at 9:51 AM
New paper from our team @GoogleDeepMind!
🚨 We've put LLMs to the test as writing co-pilots – how good are they really at helping us write? LLMs are increasingly used for open-ended tasks like writing assistance, but how do we assess their effectiveness? 🤔
arxiv.org/pdf/2503.19711
🚨 We've put LLMs to the test as writing co-pilots – how good are they really at helping us write? LLMs are increasingly used for open-ended tasks like writing assistance, but how do we assess their effectiveness? 🤔
arxiv.org/pdf/2503.19711
Reposted by Chau Minh Pham

Our lab had a #dogathon 🐕 yesterday where we analyzed NYC Open Data on dog licenses. We learned a lot of dog facts, which I’ll share in this thread 🧵
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
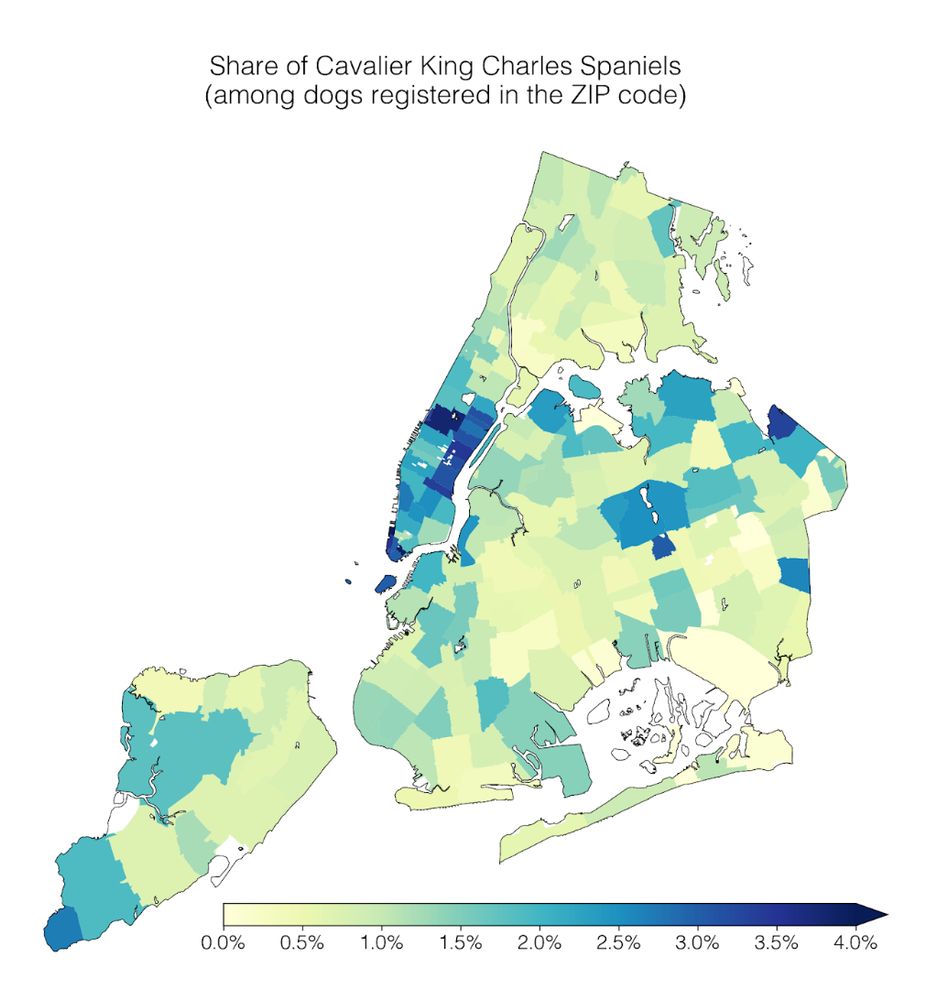
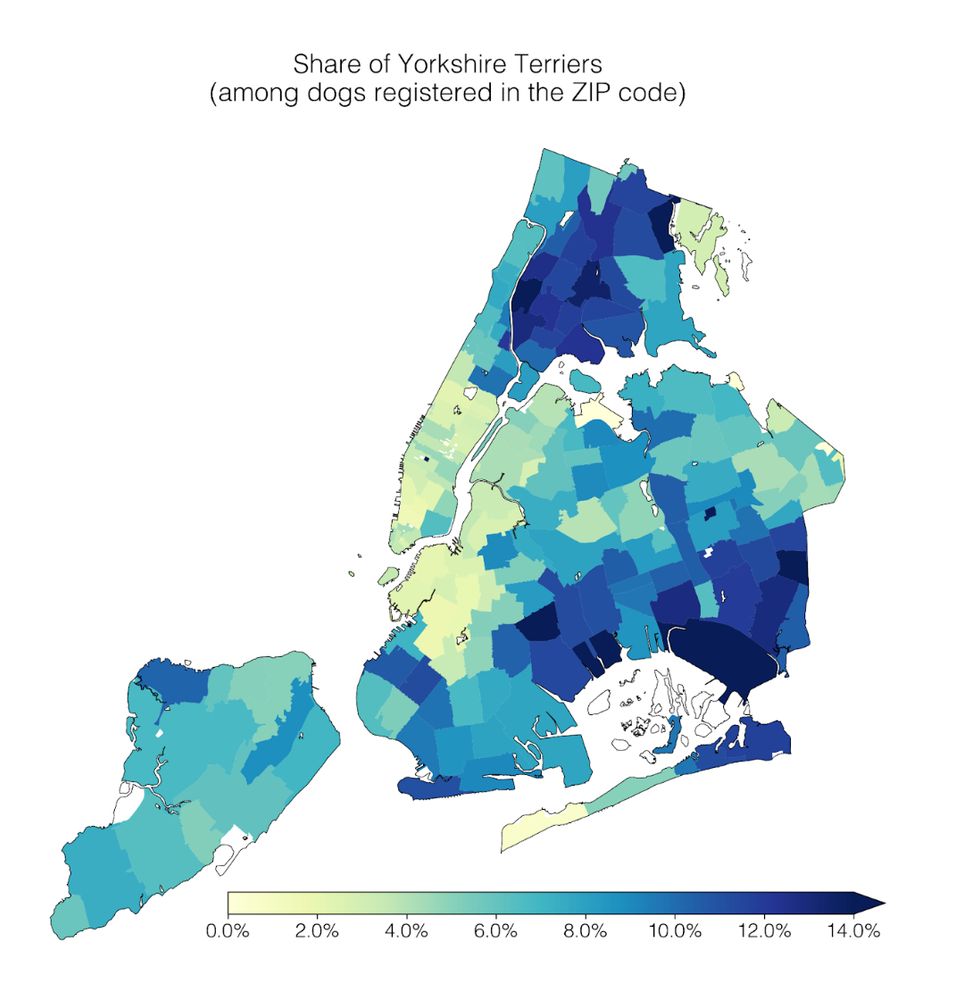
April 2, 2025 at 2:16 PM
Our lab had a #dogathon 🐕 yesterday where we analyzed NYC Open Data on dog licenses. We learned a lot of dog facts, which I’ll share in this thread 🧵
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
Reposted by Chau Minh Pham

The high effort solution is to use an LLM to make a browser extension which tracks your academic reading and logs every paper you interact with to github, which builds and publishes a webapp to expose the data.
Which, clearly only a crazy weirdo would do.
dmarx.github.io/papers-feed/
Which, clearly only a crazy weirdo would do.
dmarx.github.io/papers-feed/
ArXiv Paper Feed
dmarx.github.io
March 27, 2025 at 3:18 AM
The high effort solution is to use an LLM to make a browser extension which tracks your academic reading and logs every paper you interact with to github, which builds and publishes a webapp to expose the data.
Which, clearly only a crazy weirdo would do.
dmarx.github.io/papers-feed/
Which, clearly only a crazy weirdo would do.
dmarx.github.io/papers-feed/
Reposted by Chau Minh Pham

💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets.
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
March 18, 2025 at 3:17 PM
💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets.
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Ask OpenAI Operator for bus routes from your home in Vietnam to a university and it likely fails because it refuses to use Google Maps! Our new BEARCUBS 🐻 benchmark shows CU agents still struggle with seemingly straightforward multimodal questions.

Introducing 🐻 BEARCUBS 🐻, a “small but mighty” dataset of 111 QA pairs designed to assess computer-using web agents in multimodal interactions on the live web!
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%

March 12, 2025 at 2:58 PM
Ask OpenAI Operator for bus routes from your home in Vietnam to a university and it likely fails because it refuses to use Google Maps! Our new BEARCUBS 🐻 benchmark shows CU agents still struggle with seemingly straightforward multimodal questions.
Reposted by Chau Minh Pham

Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇

March 5, 2025 at 5:06 PM
Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
Reposted by Chau Minh Pham
Excited to share our preprint "Provocations from the Humanities for Generative AI Research”
We're open to feedback—read & share thoughts!
@laurenfklein.bsky.social @mmvty.bsky.social @docdre.distributedblackness.net @mariaa.bsky.social @jmjafrx.bsky.social @nolauren.bsky.social @dmimno.bsky.social
We're open to feedback—read & share thoughts!
@laurenfklein.bsky.social @mmvty.bsky.social @docdre.distributedblackness.net @mariaa.bsky.social @jmjafrx.bsky.social @nolauren.bsky.social @dmimno.bsky.social

February 28, 2025 at 1:34 AM
Excited to share our preprint "Provocations from the Humanities for Generative AI Research”
We're open to feedback—read & share thoughts!
@laurenfklein.bsky.social @mmvty.bsky.social @docdre.distributedblackness.net @mariaa.bsky.social @jmjafrx.bsky.social @nolauren.bsky.social @dmimno.bsky.social
We're open to feedback—read & share thoughts!
@laurenfklein.bsky.social @mmvty.bsky.social @docdre.distributedblackness.net @mariaa.bsky.social @jmjafrx.bsky.social @nolauren.bsky.social @dmimno.bsky.social